摸底10余家一线互联网公司大数据架构图:Hadoop渗透力太强!
Posted IT168企业级
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了摸底10余家一线互联网公司大数据架构图:Hadoop渗透力太强!相关的知识,希望对你有一定的参考价值。
国内外对Hadoop生态系统的生存状况争论不休,既然如此,我们不妨摸底调查一番,看看国内一线互联网公司(具备自我搭建大数据平台能力的厂商)的大数据平台是如何搭建的?是否基于Hadoop生态系统?Hadoop的存在感有多少?庞大的Hadoop生态系统中又有哪些组件真正脱颖而出了呢?(本文内容来源于公开资料整理)
BAT之阿里巴巴
如果要论数据,恐怕只有以电商起家的阿里巴巴才能拥有如此丰富且庞大的数据。有业务场景也有技术能力,阿里巴巴的大数据实力不容置疑。目前,阿里巴巴对外提供基于阿里云的大数据服务。众多大数据产品中,笔者看到了Elasticsearch的身影。
在数据分析和搜索等方面,阿里提供基于开源Elasticsearch及商业版X-Pack插件。Elasticsearch想必大家都不陌生,是继Hadoop之后非常受欢迎的后起之秀。阿里巴巴的大数据解决方案中会有它的出现一点也不让人惊讶,有了Elasticsearch还有Hadoop的用武之地吗?
在阿里巴巴早年的数加平台(整个大数据部分统称为数加)介绍中,阿里云大数据事业部数加平台技术负责人陈廷曾表示,阿里统一的自主可控的大数据平台是在Hadoop的基础上构建的,这套平台支撑了阿里很重要的一些业务,可见Hadoop对于阿里大数据平台的构建起到了至关重要的作用。
BAT之腾讯
腾讯的数据量虽然也不小,但多来源于社交数据。在离线数据处理的介绍中,我们看到腾讯大数据套件基于Hadoop体系的MapReduce、HIVE、PIG、Spark技术向企业用户提供强大的数据离线批处理能力。
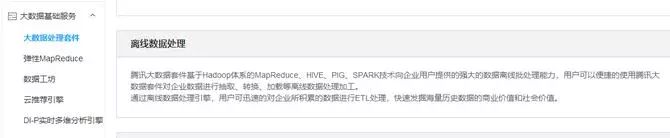
除此之外,Hadoop生态体系还包括Yarn、HBase、Sqoop、Ambari、Zookeeper、Flume、Kafka、Storm、Spark Streaming、Elastic Search、Impala、Presto、HAWQ、HUE、Log Search、Solr、Kylin。
很多人认为Hadoop生态体系中实力最弱的就是MapReduce,然而目前的腾讯大数据体系中仍然可以看到MapReduce的身影,不知道之后是否会考虑更换。
BAT之百度
百度的数据与上述两家又不同,百度的数据来源多为搜索数据,依托自身百度引擎。进入百度的大数据产品页面,可以发现百度主打的招牌是“智能”。百度的大数据产品中应用了大规模的机器学习、深度学习等能力。
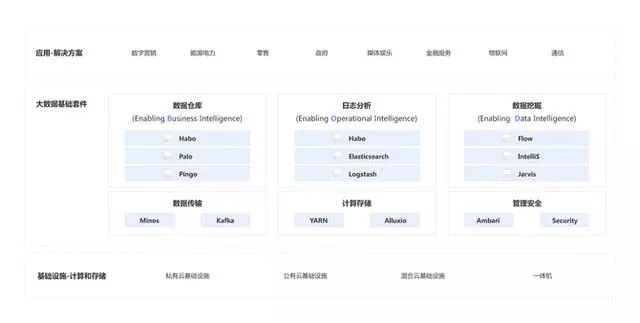
百度的大数据基础套件“鲁班”的基础架构如下,可以很直观地看到,百度大数据基础套件中的Kafka和YARN均来源于Hadoop生态系统。
京东:
京东的电商业务和物流业务如今也是越做越大,京东大数据部为了解决公司越来越广泛的实时业务需求,推出了一整套技术解决方案——JRDW(JD Realtime Data Warehouse)。
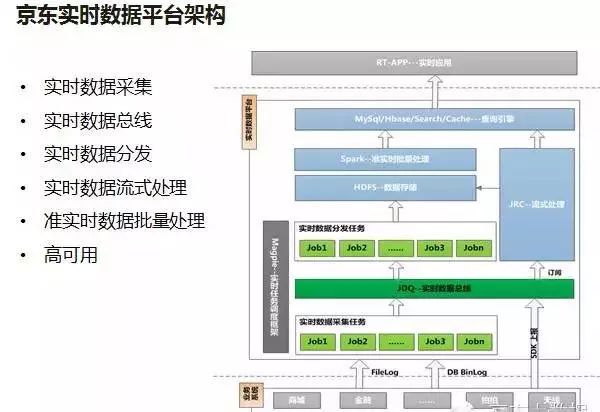
根据介绍,整个大数据平台有不少开源组件的加入,京东大数据部门在开源组件的基础上又针对其缺点进行了部分调整,形成了最终框架。在后期的发展中,京东意识到如果要搭建一个稳定可靠的实时任务运行平台很重要,通过对Storm、Hadoop、HBase、Kafka等的研究,京东自主开发了高可用调度平台Magpie。
图中可以很直接地看出Hadoop的身影,明显Hadoop对其大数据平台架构的搭建过程起到了启发作用。
美团:
美团的大数据平台主要支撑了美团的到店餐饮、到店综合、酒店旅游、猫眼电影、外卖配送等业务,中间则是基础数据部,最下层基于美团云。如果将基础数据部放大,基本如下图所示:
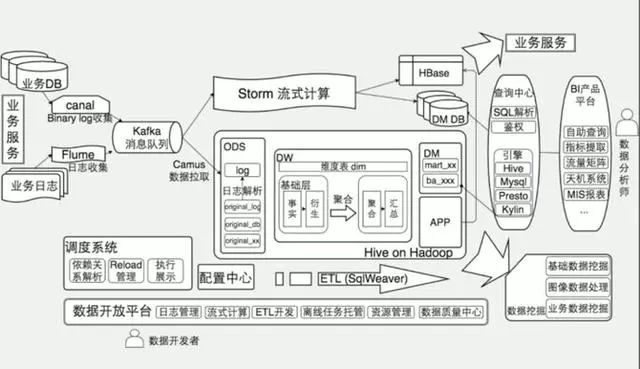
离线计算部分是基于Hadoop的数据仓库数据应用。具体到组件,基础服务层有HDFS和YARN的参与,计算引擎层有HBase、Kylin、Hive、Spark、Presto等来自Hadoop生态系统的组件参与。

根据一年前的统计数据,这套平台有42P+总存储量,每天有15万个MapReduce和Spark任务,现在想必数据量和复杂度已经再一次升高了。
网易:
网易的一站式大数据管理和应用开发平台——网易猛犸,覆盖了大规模数据存储与计算、应用开发、数据管理与集成等场景。
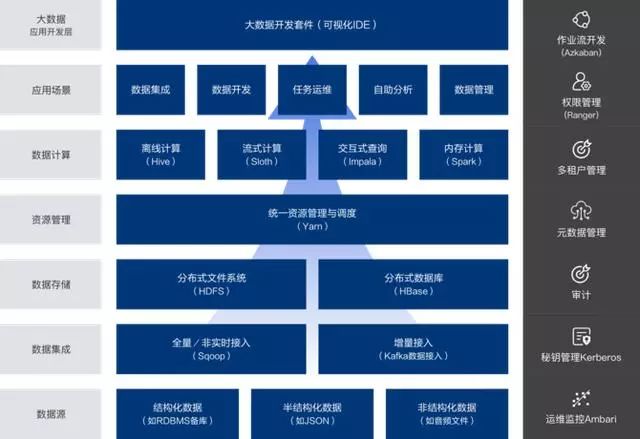
在其公布的大数据架构图中,我们可以看到底层基本完全构建于Hadoop生态系统,数据集成、数据存储、资源管理都和Hadoop生态系统有关。这套系统支持HDFS、Hbase、Kudu等从GB到PB级别的存储方案,支持Hive和MapReduce等批量计算、Spark内存计算、Kylin多维分析等多种计算方案。
今日头条:
2014年之前,今日头条并没有专门的人负责做数据。随着活跃用户数的迅猛增长,各种各样的需求不断,今日头条意识到几个数据工程师单打独斗根本解决不了问题,于是数据平台团队成立了。
该团队将Hadoop、Hive、Spark和Kylin等封装成工具,将工具与分析模式相结合包装成解决方案以提供给业务部门。在数据生成与采集方面,今日头条使用Spark实现类Sqoop的分布式抓取;在数据传输方面,采用Kafka作为数据总线,连接在线和离线系统;在数据计算方面,今日头条使用了Spark SQL和Hive;在Cube类查询引擎,今日头条已经成为Kylin国内最大使用用户之一。
滴滴:
作为目前最大且最活跃的独角兽企业,滴滴的大数据架构部门十分年轻,成立时间仅一年有余。去年,滴滴宣布向各地交通管理部门开放“滴滴交通信息平台”数据,而滴滴当时的平台日订单量已经超过2000万,流量高峰期每分钟接到的用户需求高达两万次。
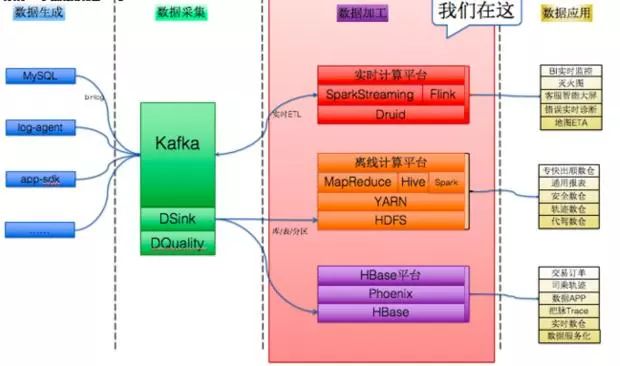
从图中不难看出,滴滴大数据平台分为多个组成部分,数据加工和数据采集两阶段明显用到了不少Hadoop生态系统的组件,数据加工部分完全依托Hadoop生态系统。
知乎
截止2017年8月,知乎注册用户数破亿,全站DAU达2600万,月浏览量180亿......知乎大数据架构分为数据采集、数据计算、数据服务和数据产品层。
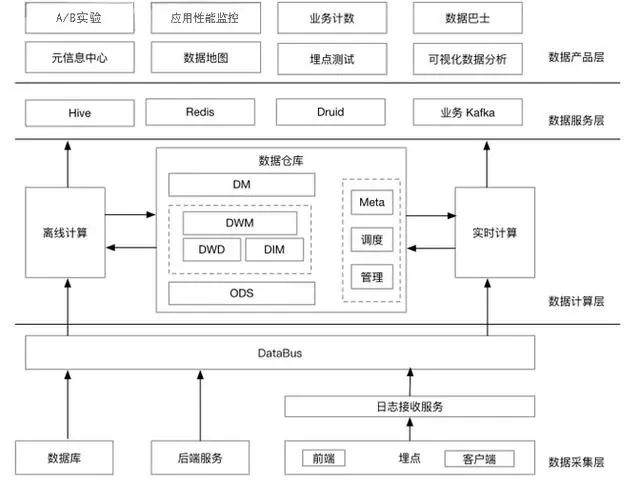
对于很多公司都会出现的mysql数据实时查询需求,知乎调研了Hive和HBase,但最后选择了将BinLog实时打入Kafka,起一套Spark Streaming程序,将数据写入Kudu,这样做的性能会更高一些。虽然这部分组件来源Hadoop生态系统,但知乎内部架构师曾表示公司正在考虑采用TiDB。
新浪
新浪同样掌握着大量社交数据,在之前有关新浪大数据体系架构的介绍中,我们可以了解到新浪的技术架构同样基于Hadoop生态圈,最下面是日志接受传输,然后进入Hadoop层,在这之上是ETL数据的整合,随后是中央数据仓库,数据挖掘、实时统计与计算等操作。
近几年,随着新技术的不断发展,新浪的大数据体系也在不断改变,但Hadoop生态体系依旧占据着重要位置。
58同城
58的大数据体系主要分为数据应用、数据应用平台、数据基础平台三层。在接入层,58使用了Canal/Sqoop解决数据接入问题,另一部分数据使用Flume,其中Sqoop和Flume均来源于Hadoop生态体系;存储层全是熟人:HDFS、HBase、Kafka;调度层是Yarn;计算层全部来自于Hadoop生态体系,比如MR、Hive等。
......
总结
最新调查结果显示,中国每年进口最多的不是石油,而是芯片。国内一线互联网公司的大数据生态体系建设基本被Hadoop包圆,这种存在感快赶上芯片在中国的地位了吧。庞大的Hadoop生态体系中,MapReduce、HDFS、Kafka和Yarn的出现频度最高。然而,不少言论都认为MapReduce的市场竞争力在逐渐减弱,如今这个应用状况似乎一点失宠的意思都没有啊!
以上是关于摸底10余家一线互联网公司大数据架构图:Hadoop渗透力太强!的主要内容,如果未能解决你的问题,请参考以下文章
媒体观察丨国内大数据一线专家分享:大家都在用Hadoop的原因是什么?
深入HBaseSparkAlluxioGreenplumStreamSQL等大数据技术及其架构设计