与 Hadoop 对比,如何看待 Spark 技术?
Posted 雷课
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了与 Hadoop 对比,如何看待 Spark 技术?相关的知识,希望对你有一定的参考价值。
雷课
关注



spark
解密
对
比
之
下
的
spark
回到本题,来说说Hadoop和Spark。Hadoop包括Yarn和HDFS以及MapReduce,说Spark代替Hadoop应该说是代替MapReduce。
MapReduce的缺陷很多,最大的缺陷之一是Map + Reduce的模型。这个模型并不适合描述复杂的数据处理过程。很多公司(包括我们)把各种奇怪的Machine Learning计算用MR模型描述,不断挖(lan)掘(yong)MR潜力,对系统工程师和Ops也是极大挑战了。

很多计算,本质上并不是一个Map,Shuffle再Reduce的结构,比如我编译一个SubQuery的SQL,每个Query都做一次Group By,我可能需要Map,Reduce+Reduce,中间不希望有无用的Map;

又或者我需要Join,这对MapReduce来说简直是噩梦,什么给左右表加标签,小表用Distributed Cache分发,各种不同Join的Hack,都是因为MapReduce本身是不直接支持Join的,其实我需要的是,两组不同的计算节点扫描了数据之后按照Key分发数据到下一个阶段再计算,就这么简单的规则而已;

再或者我要表示一组复杂的数据Pipeline,数据在一个无数节点组成的图上流动,而因为MapReduce的呆板模型,我必须一次一次在一个Map/Reduce步骤完成之后不必要地把数据写到磁盘上再读出,才能继续下一个节点,因为Map Reduce2个阶段完成之后,就算是一个独立计算步骤完成,必定会写到磁盘上等待下一个Map Reduce计算。


上面这些问题,算是每个号称下一代平台都尝试解决的。
“挖掘”MR模型的潜力
现在号称次世代平台现在做的相对有前景的是Hortonworks的Tez和Databricks的Spark。他们都尝试解决了上面说的那些问题。Tez和Spark都可以很自由地描述一个Job里执行流(所谓DAG,有向无环图)。他们相对现在的MapReduce模型来说,极大的提升了对各种复杂处理的直接支持,不需要再绞尽脑汁“挖掘”MR模型的潜力。

有兴趣的童鞋可以看看这个PPT
http://www.slideshare.net/Hadoop_Summit/w-235phall1pandey
▲
这是Hadoop峰会上Tez的材料,第九页开始有描述Hive on Tez和传统MR Hive的区别,这些区别应该也适用于MR Hive和Spark SQL,也很清楚的体现了为何MR模型很笨重。
相比Tez,Spark加入了更多内存Cache操作,但据了解它也是可以不Cache直接处理的,只是效率就会下降。

再说Programming Interface,Tez的Interface更像MapReduce,但是允许你定义各种Edge来连接不同逻辑节点。Spark则利用了Functional Programming的理念,API十分简洁,相比MR和Tez简单到令人发指。我不清楚Spark如果要表现复杂的DAG会不会也变得很麻烦,但是至少wordcount的例子看起来是这样的,大家可以比较感受下:
▲ 网址:
incubator-tez/WordCount.java at master · apache/incubator-tez · GitHub
Examples | Apache Spark
处理大规模数据而言,他们都需要更多proven cases。至少Hadoop MapReduce是被证明可行的。
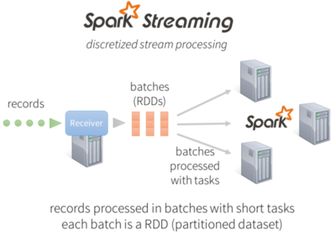
作为Data Pipeline引擎来说,MapReduce每个步骤都会存盘,而Spark和Tez可以直接网络发送到下一个步骤,速度上是相差很多的,但是存盘的好处是允许继续在失败的数据上继续跑,所以直观上说MapReduce作为pipeline引擎更稳健。但理论上来说,如果选择在每个完成的小步骤上加CheckPoint,那Tez和Spark完全能和现在的MapReduce达到一样的稳健。
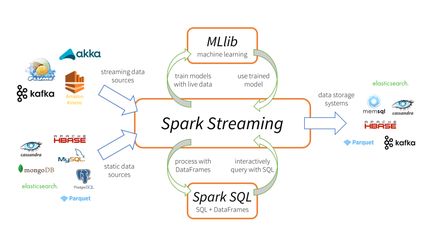
▲
总结来说,即便现在不成熟,但是并没有什么阻碍他们代替现有的MapReduce Batch Process。
对Tez而言,似乎商业上宣传不如Spark成功。Databricks头顶Berkley的光环,商业宣传又十分老道,阵营增长极快。光就系统设计理念,没有太大的优劣,但是商业上可能会拉开差距。Cloudera也加入了Spark阵营,以及很多其他大小公司,可以预见的是,Spark会成熟的很快,相比Tez。

但Tez对于Hortonworks来说是赢取白富美的关键,相信为了幸福他们也必须努力打磨推广tez。
所以就算现在各家试用会有种种问题,但是毕竟现在也就出现了2个看起来有戏的“次世代”平台,那慢慢试用,不断观望,逐步替换,会是大多数公司的策略。
点击底部“阅读全文”,查看最新培训安排
以上是关于与 Hadoop 对比,如何看待 Spark 技术?的主要内容,如果未能解决你的问题,请参考以下文章