为Hadoop集群装备上警报系统
Posted 大数据开放实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为Hadoop集群装备上警报系统相关的知识,希望对你有一定的参考价值。
分布性是Hadoop的一个重要特征,Hadoop集群由众多机器构成,其中的节点数可多达数百甚至1000+,这样的部署特性使集群性能监控成为一个棘手问题。运维人员在管理Hadoop集群时,为了及时了解系统运行情况,避免风险的产生,可能需要长期不断的收集各种信息,以掌握资源使用情况进程运行状况。这种落后方式的精确度不高且实时性较差,使很多性能问题只有在当服务运行任务出错时,才被管理人员发现。
手动监控的不便经常导致挽救危险的机会被错过,星环在各种案例实践中意识到这样的问题,针对此设计并实现了告警监控页面,并提供于Transwarp Manager(简称Manager)的图形界面。一旦集群任一服务状态超过危险阈值,就会触发告警,相关信息将实时显示在告警主页面,以告知给运维人员。
把告警系统部署在Hadoop集群中,可方便用户监控系统资源短缺、故障切换、健康问题等各种异常现象,找到失败任务的根源,及时采取应对措施,避免问题或危险的发现被拖延。本文将以Transwarp Data Hub(TDH)中的告警系统为例,介绍如何利用告警系统做运维。
三个功能模块
为了方便操作和明晰使用需求,我们将告警系统分成了三个模块:告警信息浏览、警报配置、通知功能。分别用于对告警信息的浏览、自定义告警设置、告警信息的实时通知。
警报信息浏览:
告警信息浏览界面用于查看告警系统对于当前集群状态的警报。每条信息包含了告警触发时间、等级、分类、状态、标题、资源等描述。每条警报状态有两种状态,ACTIVE和CLEARED,分别代表未解除和已被解除的告警,该状态会根据系统情况实时更新。
根据是否需要用户手动解除,我们将告警分为两类:1.可自动解除的告警,譬如某节点的cpu负载过高触发告警,当cpu负载恢复正常水平后,告警将自动解除,从ACTIVE状态变为CLEARED状态;2.需要手动解除的告警,譬如NameNode发生了主从切换,对于此类告警用户需点击clear按钮清除。可以点击相应告警信息从如下图所示的下拉描述项中了解是否需要手动解除。

另外如果用户欲查看特定的告警类别,可通过“筛选”功能实现,筛选器的各选项如下图所示。

例如,Manager默认只显示处于ACTIVE状态的告警,如果需要查看所有历史告警信息,可以在警告状态栏下选择CLEARED。需要特别说明的是告警分类,不同分类代表不同类别信息的告警,TDH警报系统将告警信息分为三类METRIC、HEALTH_CHECK、FAILOVER,顾名思义,分别表示对于指标的告警,健康问题的告警和主从切换触发的告警。
除此之外,用户还可以拖动页面上方的时间轴来限制显示特定时间范围内的报警信息:
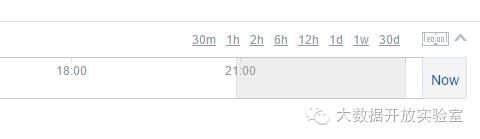
警报配置:
点击报警首页的配置按钮进入如下告警配置界面。各个服务都有对应的告警配置页。
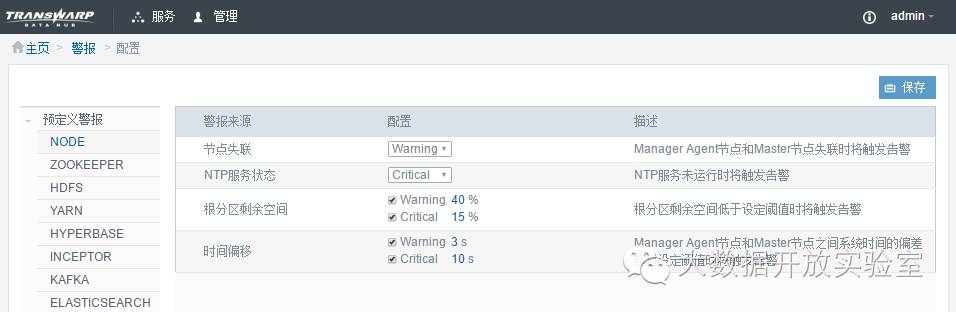
每个告警配置项给出了告警的配置方式和描述,以方便用户的理解。Manager预定义了部分关键的告警项,用户还可以根据个人需求自定义。
告警级别分为两级:Warning、Critical。
告警配置项分为两类:非数值型和数值型。非数值型用于监控异常行为,决定当出现异常行为时,应发出哪种等级的报警,其中Disable代表不发出警告。数值型选项用于划分数量或百分比的数值区间,例如磁盘剩余空间、cpu负载等,不同区间对应不同级别警报,通常当指定项低于(或高于)设定阈值时,就产生相应等级的报警。告警系统会对用户输入数值的类型、Warning和Critical数值的相对大小是否合理、数值是否超出正常范围等做简单检验。
实时通知:
实时通知就是要求系统不仅将警告信息显示在Manager上,还将信息根据所设定的途径实时发送给用户。Manager目前提供了两种通知方式:邮件通知和触发脚本调用。用户可以在配置页上对它们进行配置。
邮件通知
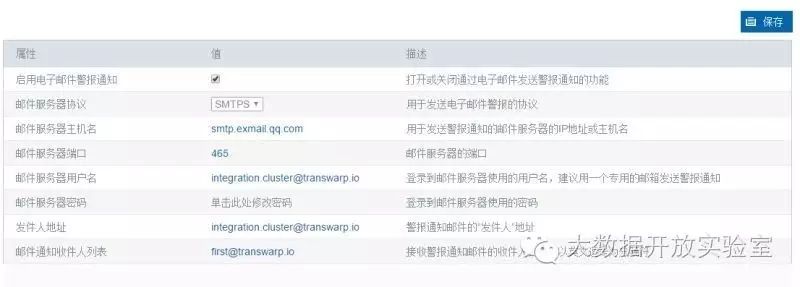
在告警通知配置界面设定好邮件收发送信息后,若告警触发,收件人会收到如下警报邮件,内容和告警首页的条目类似。
脚本调用
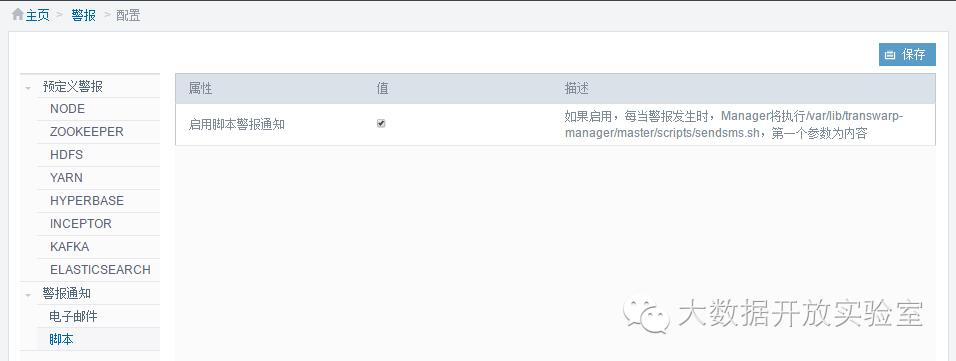
在配置界面选定脚本触发方式后,用户需编写并提供触发脚本sendsms.sh,并放置在Manager节点的var/lib/transwarp-manager/master/scripts/目录下,告警信息出现后Manager会把内容作为脚本的第一个参数传递给脚本。
应用实例
NameNode磁盘空余空间不足
NameNode 所在磁盘分区的空间占用过满将容易导致集群启动失败。所以为了提前预防因此产生的宕机,我们对HDFS的NameNode资源目录所在分区的可用空间做如下的报警设定:

剩余空间低于40%时发出Warning报警,低于15%时发出Critical报警。
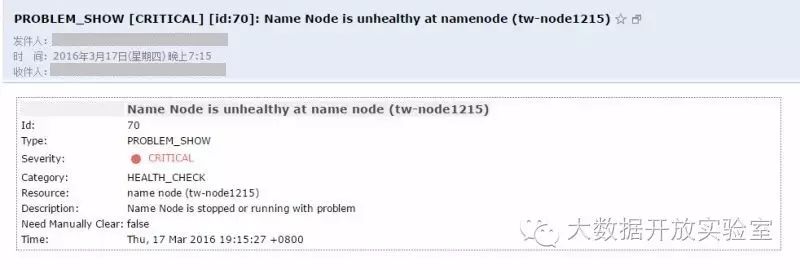
当NameNode的可用磁盘空间低于40%时,界面上将出现如下警报。该信息告诉我们该告警是对于tw-node3048节点上NameNode角色的预警,产生的原因是/hadoop/namnode_dir所在分区的可用空间低于Warning的阈值。

此时我们应考虑增加分区资源,或者删除不需要的历史文件,释放磁盘空间。
健康检查报警
TDH会对各服务进行状态检查,对不健康服务进行警报。以Kafka为例,系统通过检查Kafka Broker是否在Zookeeper上有注册信息来判断Broker是否还活着,不健康的Broker过多将导致宕机,所以Kafka Server的健康监测是关键监控项。
这里我们借助报警系统中Kafka的“不健康Kafka Server百分比”来监控Kafka Server的健康状态,当不健康Kafka Server数量超过5%时,发出Warning警报,超过10%发出Critical警报。

下面是当Unhealthy Kafka Server数量超过10%时出现的报警。从该信息我们知道,这是由Health Check问题所触发的,提示Kafka Server的健康状态不佳。

此时我们应该通过Manager性能指标页面分析各Kafka Server所在节点的资源使用情况,检查日志,进行问题排查并修复。
总结
根据上述介绍,在部署了报警功能的Hadoop系统中,用户能够快速实时了解危机情况和状态,及时采取措施预防潜在问题产生。TDH告警系统广泛覆盖了需要警报的项目,从多方面为每个服务提供了多个报警项选择,提供细致的监控保障。为了实现高效的Hadoop集群管理,熟练运用并掌握报警系统的配置项,根据实际应用选择合理的阈值,是建议TDH集群运维人员具备的一项技能。
往期原创文章
大数据开放实验室由星环信息科技(上海)有限公司运营,专门致力于大数据技术的研究和传播。若转载请在文章开头明显注明“文章来源于微信订阅号——大数据开放实验室”,并保留作者和账号介绍。
以上是关于为Hadoop集群装备上警报系统的主要内容,如果未能解决你的问题,请参考以下文章