HADOOP集群救火:一次Hive服务卡顿问题解决纪要
Posted Hadoop技术学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HADOOP集群救火:一次Hive服务卡顿问题解决纪要相关的知识,希望对你有一定的参考价值。
下面文字是来自 天源迪科 大数据专家一篇纯干货的实战问题解决过程。
看到这种总结文章,还是非常激动,这种类似解决问题过程我也经常有。特别能感受到作者开始碰到问题的一筹莫展 到 最后解决之后酣畅伶俐的心情。
强烈推荐!!!也希望更多的同学也来一起分享问题解决过程。
问题背景
Hive 0.13可能算是相对古老一点的Hive版本,但仍然在我们有些生产集群上使用。因为版本较老,bug自然相对会多一点。我这一次接到的问题是这样,现场的简单一句话就是“Hive beeline卡顿”,具体表象:“Hive服务跑着跑着一段时间后,大约几个小时到是几个小时不等,出现beeline建连接卡顿连接不上情况,一般需要等待一段时间,长短不等,几分钟,或是半小时以上”。为了临时缓解使用上的问题,现场开发了一些电子巡检的脚本,一旦发现这样的问题自动重启Hive的服务,当然对现有在运行的作业是会产生影响,因此又在ETL调度层面做了重处理的机制。我们部署有一套数据开发工具供应用开发人员使用,由于也是JDBC方式访问Hive服务,白天也会收到大量的类似投诉,因此平台的用户感知不是很好。进一步了解,该问题由来已久,持续了一两年,客户自己和厂家的专家也都参与折腾过,消耗精力巨大,尽管上从技术上乍一看是一个小问题,但影响面却是非常大,生产的问题都不是小问题。
集群环境
HADOOP版本 |
CDH 5.3.3,对应hadoop是Hadoop2.5,采用的是tar解压方式安装管理 |
Hive版本 |
Hive0.13.3 |
节点规模 |
50个左右 |
分析过程
我们首先按惯例跟踪了服务在资源消耗、连接释放等方面的问题,如:用netstat跟踪服务被连接的计数、用jmap查看服务内存的gc情况、用jstack去尽可能发现一些死锁的片段,并做出一些参数的调整,效果都不理想。要命的是,该问题出来的周期长,每一轮的调参看效果动辄十几个小时,时间是有限的,要求我们有更大的定力。
在排除掉参数配置上的失误之外,其它比较疑难问题最直接的解决办法是版本升级,但升级工作遇到如下情况。
客户要求:客户认为,目前集群中的存量数据大,升级又是手动操作,存在较大风险。近阶段基调是基于现有版本保障正常运行,组件级的升级是允许的,但不考虑Hadoop核心层面的大升级
Hive大版本的升级可行性:下一个CDH中包含稳定版本是1.1.0,套件是CDH5.4 , Hadoop2.6, 目前集群是Hadoop2.5,在这样的条件下能不能单独升级呢?我曾寄希望于这样的升级,能够直接的修复当前的问题,这样大家都轻松。猜想大家也做过一些通过偷梁换柱更换版本的经历,而我们验证确实是不行,主要问题出在MapReduce框架相关的JAR兼容性上,大家如有兴趣可以去下尝试
Hive小版本升级,做了过一轮hive0.13.3-CDH5.3.3到hive0.13.3-CDH5.3.10的升级,解决了Hive metastore连接释放的bug(很明显的可以观察到metastore服务对于连接是产生和释放是存在缺陷的),但验证过后发现问题没有解决,而且需要同步做一个Sentry组件的小升级,考虑到生产影响因此做了回退
Hive服务是HiveServer2和Hivemetastore一整套服务,按照二分法的原则来排查。找准一个卡顿时间点,仅将Hivemetastore服务做一个重启而不是都重启两个服务,发现可以连接。由此是否可以断定是metastore端产生的问题呢?陆陆续续,我们找到一些这样的资料:
大体意思是讲因为元数据中表或分区过多,对于metastore服务的影响。对元数据库表做了一个统计,分区数在2000以上的表对象不在少数,该集群是一个Hive被重度使用的环境,人员建模和开发水平层次不齐,出现一些状况在所难免。由此,我们坚信metastore端的问题来得更显著。为了规避分区表查询的压力,我们尝试添加hive.limit.query.max.table.partition参数来做限定,限定起到作用了,糟糕的是带来了新的部分语句的语法解析问题,为了不影响现有业务,不得不再次回退。此刻有点沮丧。
解决方案
既然是metastore的问题,能不能在它上面做点文章。说干就干。
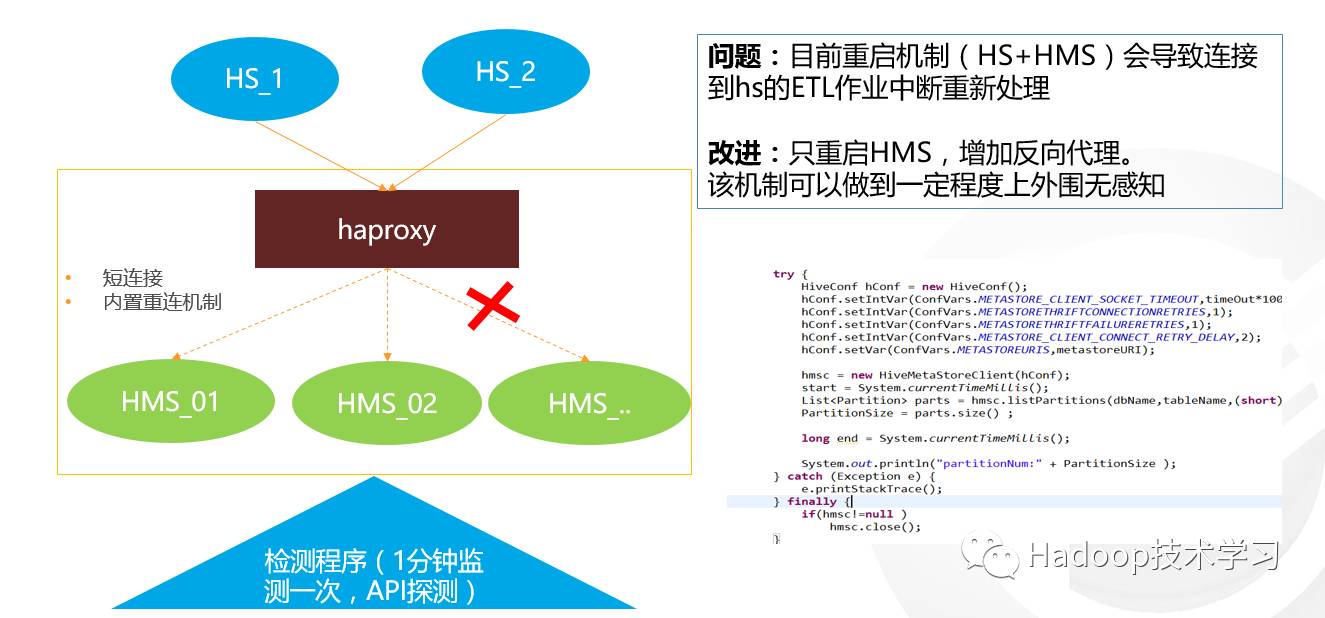
对hiveserver2服务通过jdbc程序或beeline命令探测大家可能比较熟悉,实际上metastore服务的探测编程也是非常容易的,通过短短的几行代码也可以做到:

为了准确的了解到服务的可连接情况,额外编写了一套crontab脚本,按照每分钟探测metastore、每两分钟探测hiveserver,记录详细的时间信息和探测结果。 另外针对JDBC连接的探测,增加连接的超时将会起到很好的效果,API是DriverManager.setLoginTimeout(timeout),否则程序将会长久卡住并启动多份。
解决效果
我们重点关注的是hiveserver2服务的探测情况,因为这就是我们前端用户需要关注的,通过24小时的观察,除了1~2次的短时停顿(约在1分钟左右,时间点处在metastore服务卡死而未恢复好时间点上),其它均表现正常。大胆预测,这样的稳定水平已经能足够满足业务使用要求。当然还是需要补充说明的,这仍然是截止到我在整理这个文档的运行情况,后面还指不定出来新情况。
总结
坦率讲,hive服务层面并未根治,是时间问题,更多是个人能力问题,目前评估需要源代码层面调整,局部的小补丁总会引出新问题,要么做大版本升级。但通过变通手段缓解生产的实际问题,个人也有收获。希望上述过程给大家一点启发。
以上是关于HADOOP集群救火:一次Hive服务卡顿问题解决纪要的主要内容,如果未能解决你的问题,请参考以下文章