学习必备!详解Hadoop的分布式文件系统
Posted 大数据视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习必备!详解Hadoop的分布式文件系统相关的知识,希望对你有一定的参考价值。
通过前几天的学习,我们对Hadoop及其Hadoop生态有了全面的了解。大家都知道 Hadoop 主要由HDFS和MapReduce 引擎两部分组成。最底部是HDFS,它存储Hadoop 集群中所有存储节点上的文件。而HDFS 的上一层是MapReduce 引擎,该引擎由JobTrackers 和TaskTrackers组成。
在这篇文章中,数据妞跟大家一起了解Hadoop的分布式文件系统——HDFS(Hadoop Distributed File System)。我们将从HDFS的背景、基本概念开始,步步深入了解HDFS的设计目标、HDFS的基本结构等知识。一起踏上HDFS的学习之旅吧,Let’s Go!

随着数据量越来越大,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。
学术上的定义是:分布式文件系统是一种允许文件通过网络在台主机上分享的文件的系统,可让多机器上的多用户分享文件和存储空间。分布式文件管理系统很多,HDFS 只是其中一种。适用于一次写入、多次查询的情况,不支持并发写情况,小文件不合适。因为小文件也占用一个块,小文件越多(1000个1k文件)块越多,NameNode压力越大。
维基百科上是这样解释的:
The Hadoop distributed file system (HDFS) is a distributed, scalable, and portable file-system written in Java for the Hadoop framework. A Hadoop cluster has nominally a single namenode plus a cluster of datanodes, although redundancy options are available for the namenode due to its criticality. Each datanode serves up blocks of data over the network using a block protocol specific to HDFS. The file system uses TCP/IP sockets for communication. Clients use remote procedure call (RPC) to communicate between each other.
HDFS是一个分布式文件系统,它能运行在普通的硬件之上,且具备高度容错性。它能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
1. 存储超大文件
这里的“超大文件”是指几百MB、GB甚至TB级别的文件。
2. 最高效的访问模式是:一次写入、多次读取(流式数据访问)
HDFS存储的数据集作为hadoop的分析对象。在数据集生成后,长时间在此数据集上进行各种分析。每次分析都将设计该数据集的大部分数据甚至全部数据,因此读取整个数据集的时间延迟比读取第一条记录的时间延迟更重要。
3. 运行在普通廉价的服务器上
HDFS设计理念之一就是让它能运行在普通的硬件之上,即便硬件出现故障,也可以通过容错策略来保证数据的高可用。
我们通过hadoop shell上传的文件是存放在DataNode的block中,通过linux shell是看不到文件的,只能看到block。可以一句话描述HDFS:把客户端的大文件存放在很多节点的数据块中。在这里,出现了三个关键词:文件、节点、数据块。HDFS就是围绕着这三个关键词设计的,我们在学习的时候也要紧抓住这三个关键词来学习。
下面是关于数据块、namenode、datanode的基本概念,大家可以先了解下。
数据块(block):大文件会被分割成多个block进行存储,block大小默认为64MB。每一个block会在多个datanode上存储多份副本,默认是3份。
元数据节点( namenode ):namenode负责管理文件目录、文件和block的对应关系,以及block和datanode的对应关系。
数据节点(datanode):datanode就负责存储了,当然大部分容错机制都是在datanode上实现的。
从元数据节点(secondarynamenode):不是我们所想象的元数据节点的备用节点,其实它主要的功能是周期性将元数据节点的命名空间镜像文件和修改日志合并,以防日志文件过大。
我们先来弄清楚这个三种节点的关系吧!
其实,元数据节点上存储的东西就相当于一般文件系统中的目录,也是有命名空间的映射文件以及修改的日志,只是分布式文件系统将数据分布在各个机器上进行存储罢了。
下面我们将以这几张说明图来展示,相信你很快就可以明白了。

元数据节点与从元数据节点目录图

数据节点目录结构图
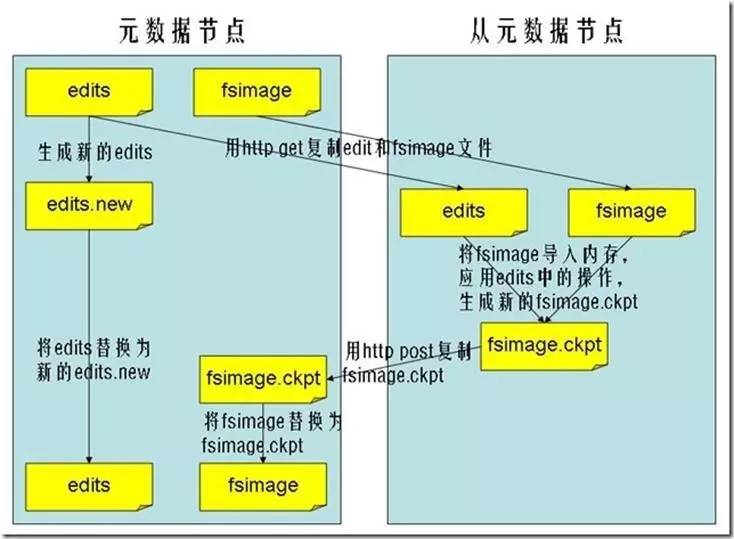
元数据节点与从元数据节点之间的进行checkpoint的过程
HDFS是一个主/从(Mater/Slave)体系结构,从最终用户的角度来看,它就像传统的文件系统一样,可以通过目录路径对文件执行CRUD(Create、Read、Update和Delete)操作。但由于分布式存储的性质,HDFS集群拥有一个NameNode和一些DataNode。
NameNode管理文件系统的元数据,DataNode存储实际的数据。客户端通过同NameNode和DataNodes的交互访问文件系统。客户端联系NameNode以获取文件的元数据,而真正的文件I/O操作是直接和DataNode进行交互的。
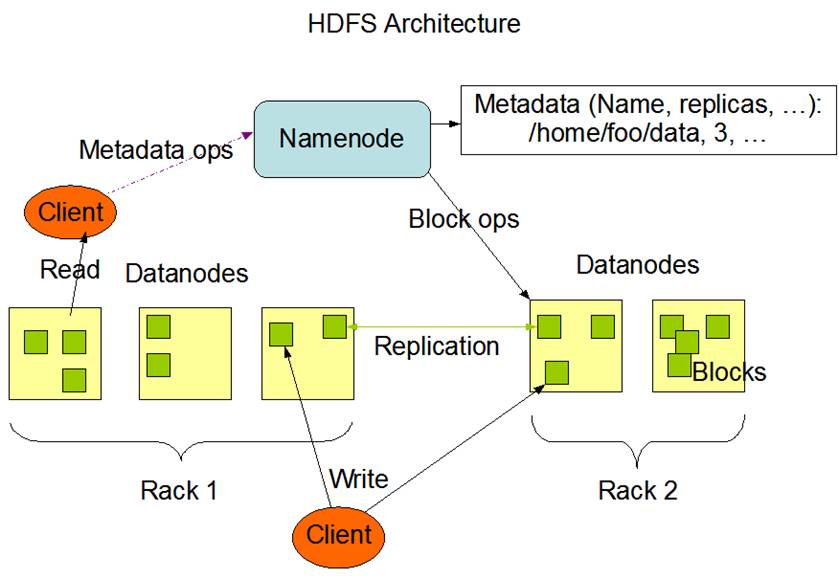
下面我们将了解元数据节点、从元数据节点、数据节点以及客户端在整体架构中的作用:
NameNode
NameNode可以看作是分布式文件系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。NameNode会将文件系统的Meta-data存储在内存中,这些信息主要包括了文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode的信息等。
Secondary namenode
它并非NameNode的热备,而是辅助NameNode,分担其工作量。定期合并fsimage和fsedits,推送给NameNode。在紧急情况下,可辅助恢复NameNode。
DataNode
DataNode是文件存储的基本单元,它将Block存储在本地文件系统中,保存了Block的Meta-data,同时周期性地将所有存在的Block信息发送给NameNode。
Client
它用于:
文件切分与NameNode交互,获取文件位置信息;
与DataNode交互,读取或者写入数据;
管理HDFS;
访问HDFS。
文件写入
它用于:
Client向NameNode发起文件写入的请求。
NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。
文件读取
Client向NameNode发起文件读取的请求。
NameNode返回文件存储的DataNode的信息。
Client读取文件信息。
HDFS典型的部署是在一个专门的机器上运行NameNode,集群中的其他机器各运行一个DataNode;也可以在运行NameNode的机器上同时运行DataNode,或者一台机器上运行多个DataNode。一个集群只有一个NameNode的设计大大简化了系统架构。
1.HDFS原理分析:基本概念
2.HDFS详解
3.解读HDFS
4.Hadoop日记Day5---HDFS介绍
5.Hadoop之HDFS
注明:本文为原创文章
如需转载,烦请联系数据妞获得授权,谢谢合作。
HDFS不是这么简单就能说清楚的,今天与大家先分享以上的内容。后期,数据妞还会分享一些HDFS进行文件操作的内容,希望大家持续关注大数据视界。
觉得文章不错,欢迎多多分享、点赞哦!
以上是关于学习必备!详解Hadoop的分布式文件系统的主要内容,如果未能解决你的问题,请参考以下文章