独家 | 一文读懂Hadoop:Mapreduce
Posted 数据派THU
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了独家 | 一文读懂Hadoop:Mapreduce相关的知识,希望对你有一定的参考价值。
随着全球经济的不断发展,大数据时代早已悄悄到来,而Hadoop又是大数据环境的基础,想入门大数据行业首先需要了解Hadoop的知识。2017年年初apache发行了Hadoop3.0,也意味着一直有一群人在对Hadoop不断的做优化,不仅如此,各个Hadoop的商业版本也有好多公司正在使用,这也印证了它的商业价值。
读者可以通过阅读“一文读懂Hadoop”系列文章,对Hadoop技术有个全面的了解,它涵盖了Hadoop官网的所有知识点,并且通俗易懂,英文不好的读者完全可以通过阅读此篇文章了解Hadoop。
本期独家内容“一文读懂Hadoop”系列文章先介绍Hadoop,继而分别详细介绍HDFS、MAPREDUCE、YARN的所有知识点,分为四期内容在近几天推送。敬请关注后续内容。
本期内容为大家详解Mapreduce:
Mapreduce是一个计算框架,既然是做计算的框架,那么表现形式就是有个输入(input),mapreduce操作这个输(input),通过本身定义好的计算模型,得到一个输出(output),这个输出就是我们所需要的结果。
我们要学习的就是这个计算模型的运行规则。在运行一个mapreduce计算任务时候,任务过程被分为两个阶段:map阶段和reduce阶段,每个阶段都是用键值对(key/value)作为输入(input)和输出(output)。而程序员要做的就是定义好这两个阶段的函数:map函数和reduce函数。
1. 设计理念
分布式计算;
移动计算而不移动数据。
2. 计算框架
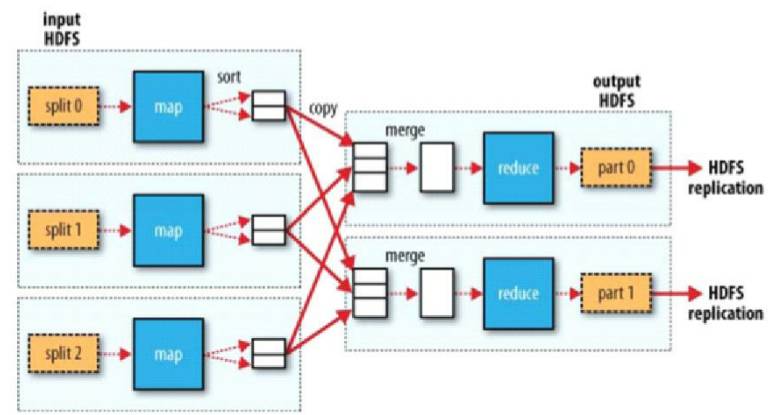
第一个阶段是split,主要是将大文件切分成小文件。
第二个阶段是map,做些基本的分析,一般一个split对应一个map。一般很少在map端做累加,如果文件较大,就要将split传给map的文件全部加载到内存。
第三个阶段是shuffle,主要做排序、分区、分组,连接map与reduce。
第四个阶段是reduce,做进一步分析,reduce在拿数据的时候是通过迭代器的方式拿的,避免了内存溢出的情况。
3. 主从结构
主resourcemanager:
负责调度分配每一个task任务运行于nodemanager上,如果发现有失败的,就重新分配任务到其它节点,每一个hadoop集群中只有一个resourcemanager,一般它运行在master节点。
从nodemanager:
nodemanager主动与resourcemanager通信,接收作业,并负责执行每一个task任务,为了减少网络带宽,nodemanager最好运行在hdfs的datanode上。
4. 组成
4.1 MapReduce的split的大小
Split的最大值为:max_split
Split的最小值为:min_split
Block的大小:block
切分规则:max(min_split,min(max_split,block)),主要是为了减少网络带宽。
4.2 Mapper
MapReduce的思想:分而治之。Mapper负责“分”即把复杂的任务分解为若干个简单的任务执行,这样数据或计算规模相对于源任务大大缩小,就近计算,即会被分配到存放了所需数据的节点进行计算,并且这些小任务可以并行计算,彼此间几乎没有依赖关系。
计算框架Mapper中resourcemanager主要是对计算流程的管理,数据存放在datanode上,计算也在这上面计算。同时,namenode管理元数据信息,过程中resourcemanager会请求namenode。
4.3 Shuffle
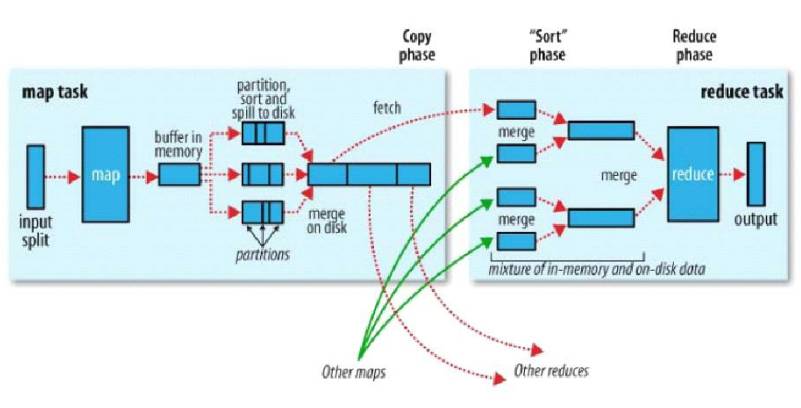
Shuffle是介于mapper与reducer中间的一个步骤,hadoop一般都是移动计算而不移动数据,但是在shuffle阶段有数据的移动。首先map以K-Value键值对的形式输出,输出后写到内存缓冲区,每一个map_task都有一个内存缓冲区(默认100MB)存储着map的输出结果。当写入内存缓冲区中的数据达到了一定的阈值时,将缓冲区的数据以一个临时文件的方式存放到磁盘(split)。溢写是由单独线程来完成,不影响往缓冲区写map结果的线程(split.percent)默认是0.8,将溢写的过程中的一个个磁盘小文件进行分区,分区的目的是为了标记这些数据都是由后面的哪个reduce来处理。分区的默认规则是key的hash值%reduce的个数。当溢写线程启动后,需要对这80MB空间内的KEY做排序(sort)。将磁盘小文件合并成一个大文件(combiner),然后reduce主动去map端把属于自己的数据拉取过来,到了reduce端要进行二次排序(分组)。同时reduce端的数据也是加载到内存的,内存满了同样会触发溢写。过多的小文件同样会合并成大文件,最后是reduce的输出。
4.4 Reducer
Reducer主要是对map阶段的进行汇总,Reduce的数目由mapred-site.xml配置文件里的项目mapred.reduce.tasks决定,缺省值为1,用户可以覆盖。
4.4.1 计算框架Reducer
其中resourcemanager用于调度,reduce从map端拿数据,并进行汇总,将结果输出到hdfs中。
本期独家内容“一文读懂Hadoop”系列文章先介绍Hadoop,继而分别详细介绍HDFS、MAPREDUCE、YARN的所有知识点,分为四期内容在近几天推送。敬请关注后续内容。
一文读懂Hadoop系列往期回顾:

宋莹,数据派研究部志愿者,北京中软融鑫ETL工程师。喜爱数学和计算机,酷爱大数据分析、大数据挖掘、机器学习。
【一文读懂】系列往期回顾:
数据派研究部介绍
数据派研究部成立于2017年初,志于打造一流的结构化知识分享平台、活跃的数据科学爱好者社群,致力于传播数据思维、提升数据能力、探索数据价值、实现产学研结合!
研究部的逻辑在于知识结构化、实践出真知:梳理打造结构化基础知识网络;原创手把手教以及实践经验等文章;形成专业兴趣社群,交流学习、组队实践、追踪前沿。
兴趣组是研究部的核心,各组既遵循研究部整体的知识分享和实践项目规划,又会各具特色:
算法模型组:积极组队参加kaggle等比赛,原创手把手教系列文章;
调研分析组:通过专访等方式调研大数据的应用,探索数据产品之美;
系统平台组:追踪大数据&人工智能系统平台技术前沿,对话专家;
自然语言处理组:重于实践,积极参加比赛及策划各类文本分析项目;
制造业大数据组:秉工业强国之梦,产学研政结合,挖掘数据价值;
数据可视化组:将信息与艺术融合,探索数据之美,学用可视化讲故事;
网络爬虫组:爬取网络信息,配合其他各组开发创意项目。
点击文末“阅读原文”,报名数据派研究部志愿者,总有一组适合你~
转载须知
如需转载文章,请做到 1、正文前标示:转自数据派THU(ID:DatapiTHU);2、文章结尾处附上数据派二维码。
申请转载,请发送邮件至datapi@tsingdata.com

企业,个人加入组织请查看“联合会”
往期精彩内容请查看“号内搜”
加入志愿者或联系我们请查看“关于我们”
点击“阅读原文”加入组织~
以上是关于独家 | 一文读懂Hadoop:Mapreduce的主要内容,如果未能解决你的问题,请参考以下文章