你好,Hadoop
Posted 合众科技直通车
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了你好,Hadoop相关的知识,希望对你有一定的参考价值。
君不见,双十一天猫淘宝1682亿交易量叹为观止...
君不见,购物商城“猜你喜欢”深得我心...(此处省略1000字,吃土的人生充满辛酸…)
但是…
数以亿计的败家用户…如此精准的营销…
他们是怎么做到的?!
真相只有一个:大数据计算!

让小编偷偷告诉你,我们也在研究大数据哦~已经搭建了Hadoop集群环境啦!

听小编给你慢慢道来~
有几名技术人员,从1月开始学习了解HDFS、MapReduce、Yarn等Hadoop核心组件 ,3月底开始着手部署Hadoop数据平台,于4月底攻坚克难完成运行环境的搭建。
,3月底开始着手部署Hadoop数据平台,于4月底攻坚克难完成运行环境的搭建。
超哥说,辣么多资料,我的眼睛都看花了呀呀呀(献上小编的膝盖 )
)
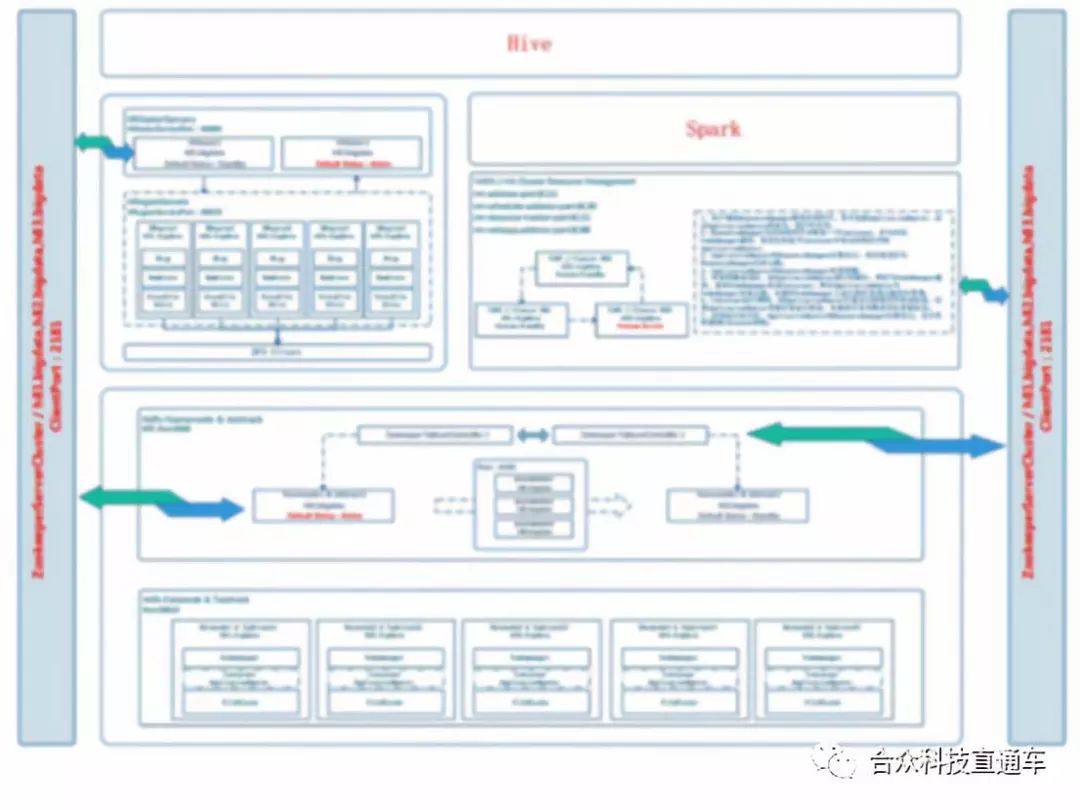
目前,技术团队正在该平台上进行基于Hbase的**模型开发。
下面来看看相关人员的心得~
超哥:Hadoop平台/大数据与传统BI的区别
Hadoop平台/大数据技术的第一要务是要解决业务问题(此处业务问题为广义的业务问题,可以是核心业务,可以是外围系统或功能,也可以是数仓、ecif等衍生系统),大数据在一定程度上讲就是用全新的数据技术手段来拓展和优化业务。
大数据相对于传统BI,不仅仅是简单的PLUS的关系,它涉及了开发思想、开发工具和开发人员深层次的变革和更新。传统BI创造的价值是长远的,关键的价值在于,企业可通过BI梳理业务和管理流程。通过数据可视化督促数据治理,倒逼业务质量和数据质 量,借此提出指标的改进方案和行动计划,以提升关键指标。大数据的价值,需要对全量的、多品类、跨业务的数据分析,才能产生价值,传统BI的 结构化约束,极大制约了数据种类,同时传统数据库架 构已无法应对爆发式的结构化业务数据增长及多样性的业务需求。而基于Hadoop的大数据处理,优势在于计算的扩展性,可以处理TB 到PB的数据,另外大数据平台可对非结构化的数据进行分析处理,可满足对业务的多样化需求的支持,充分挖掘数据价值。
个人认为,从大数据服务器集群的数量来确定一个企业是否达到大数据开发的最低标准是片面的,从数据处理的角度来讲,使用一台(传统数据库)服 务器(针对不同的业务场景,该服务器配置不同,可以是小型机,pc server等)无法正常生成结果集数据时,通过线型增加服务数据以达到扩展计算和存储的方案,均为大数据思想的解决方案。
(再次献上小编的膝盖~)
徐哥:HBase 开发过程中的“坑”
HBase是一种列式存储数据库,与传统的关系型数据库是不一样,所以在开发过程中对列式数据库的操作也和传统关系型数据库的方式不一样,下面就HBase开发过程中遇到的一些“坑”及解决办法和大家分享一下:
坑1:API函数被废弃
在学习一门新的开发工具的时候我们一般都会到网上寻找前人发表的代码例子以供参考,但是网上写的博客一般都没有写API的版本号,等我们将别人写好的代码copy到我们自己的工程的时候,就会出现下面的状况:
public static void get(String tablename,String row)
throws IOException{
HTable table=new HTable(cfg,tablename);
Get g=new Get(Bytes.toBytes(row));
Result result=table.get(g);
System.out.println("Get: "+result);
}
上面这段代码是我们容易在网上搜索到的,然而当我们将上面的代码放到我们自己的工程里的时候会发现HTable,虽然该方法还能用,但是显然是已经被废弃掉的了,这样就只能查找对应版本的API了。
于是需要打开HBase 1.2.6版本的API,发现已经没有HTable这个类了,取而代之的是Table类,并且实例化该类是从Connection对象中获取的,于是新版本的API变成如下:
Connection conn = HBaseUtil.getConnection();
TableName tname = TableName.valueOf(namespaceAsString, tableName);
Table htable = conn.getTable(tname);
ResultScanner rs = htable.getScanner(new Scan());
...
htable.close();
这样就没有烦人的删除线了,整个代码也看着清爽些了。
坑2:查询最大值
在实际开发中我们经常会用到查询主键的最大值,这个在Oracle数据库中用max函数非常容易实现,但是在HBase中没有提供这个函数,so,就需要自己想办法实现这个方法了。但是在网上找了半边也没有找到很好的解决办法,最后,偶然间在知乎上有为大神提供了一种方法,于是拿来使用一下。
具体的思路是HBase的rowkey(主键)是按顺序存储的,API中的Scan函数提供从前往后或者从后往前顺序扫描,这样只要从后往前找到第一条数据就是我们要找的rowkey最大值:
Table htable = conn.getTable(tname);
Scan scan = new Scan();
scan.setReversed(true);/*设置从后往前进行扫描*/
scan.setCaching(1);/*设置缓存的大小*/
scan.setMaxResultSize(1);/*设置结果集最大值*/
scan.setFilter(new PageFilter(1));/*设置分页大小,不设置的话结果会取很多值*/
ResultScanner rs = htable.getScanner(scan);
...
坑3:非主键扫描
HBase是列式存储结构,主键只有一个,并且在其他段值上没法创建索引。这样我们在进行非主键字段进行过滤查询的时候就会进行全表扫描,如果表的数据量非常大的话,比如说有4000万条数据,则API会报连接超时的错误(指定时间内没有返回结果),这样进行非主键过滤查询就不可行,需要采取其他办法进行处理。
目前采用的一种办法是根据业务需求将查询结果保存到临时表,然后再通过临时表导入HBase中,再通过API获取相应的结果。
举个栗子:
有个业务需求需要查询投保人名下的保单数量,在Oracle下面的查询语句如下:
SELECT COUNT(m.policy_id) policy_count
FROM t_contract_master m
WHERE m.applicant_id = 123456
我们根据applicant_id新建一张临时表:
create table t_cache_tmp as
SELECT applicant_id applicant_id, COUNT(m.policy_id) policy_count
FROM t_contract_master m
GROUP BY m.APPLICANT_ID;
将t_cache_tmp通过工具导入到HBase中,然后将applicant_id作为rowkey,这样就可以在HBase中用API通过rowkey进行快速访问了。
小编:坑这么多,会不会掉坑里出不来了…
徐哥:来来来,教你认识下“艺高人胆大”这几个字怎么写~
小编:V587!
小编觉得大家都棒棒哒~
突然好像看见了数以亿计的保险客户在屏幕上迅速掠过…
以上是关于你好,Hadoop的主要内容,如果未能解决你的问题,请参考以下文章