初体验Hadoop-伪分布环境的搭建
Posted 敏叔的技术札记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了初体验Hadoop-伪分布环境的搭建相关的知识,希望对你有一定的参考价值。
上文说到过一台机器下hadoop的样子,这次我们一起来体会一下~~
一般刚刚接触hadoop或者需要用于做开发的时候,伪分布集群显得很重要;伪分布环境是在一台节点上启动了Hadoop基本功能节点,所以这种环境可以用于运行例如Hive、MR、Spark程序等,更重要的一点,初期的资源比较有限,伪分布环境可以在简单几步动作之后安装完成,可以给人很强大的自信。
嗯,下面准备带大家入坑。。
一、初期的配置准备
首先是软件准备:
图一:软件准备情况
创建目录,解压:

图二:压缩包解压
为hadoop目录创建软链接:
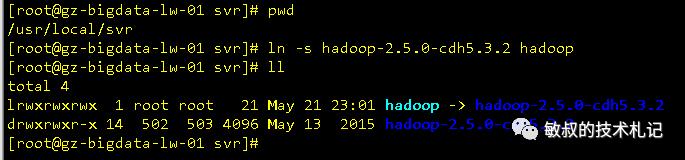
图三:软连接
同样,对jdk压缩包做同样的工作:
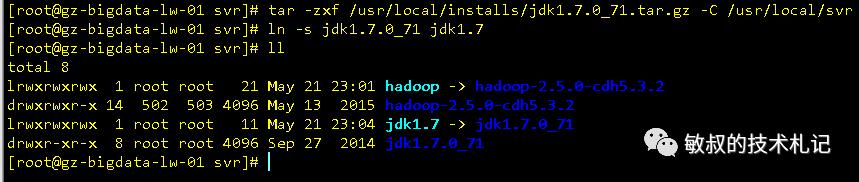
图四:jdk解压缩
到了这里,软件包准备完成了,我们切换到hadoop的文件目录去看一下,根据linux目录规范,我们很自然了解到bin下面一般是基本命令,sbin下面会放一些管理脚本:

图五:hadoop的命令结构
我们试着启动一下,看下情况:

图六:错误的提示
很棒,我们第一次收到了来自hadoop命令行中的提示,从提示我们可以读到很多信息:
JAVA_HOME没有设置
由此,我们需要对hadoop多一点点认识:
hadoop是java语言开发的,运行需要java环境,需要配置jdk
默认不做配置的时候,hadoop会使用默认的配置,需要我们针对进行修改,具体配置可以查看core-default.xml、hdfs-default.xml、mapred-default.xml、yarn-default.xml
hadoop是分布式程序,启动脚本运行方式是通过ssh方式去进行远程控制节点,为了不每次输入密码,我们会设置节点之间免密码登录模式
当然,单机的情况也是走的网络,所以在单机上需要进行这些配置。我把主机名修改为gz-bigdata-lw-01.com,然后配置域名解析:

图七:域名解析
配置hadoop所需的jdk,hadoop的环境变量位于etc/hadoop-env.sh
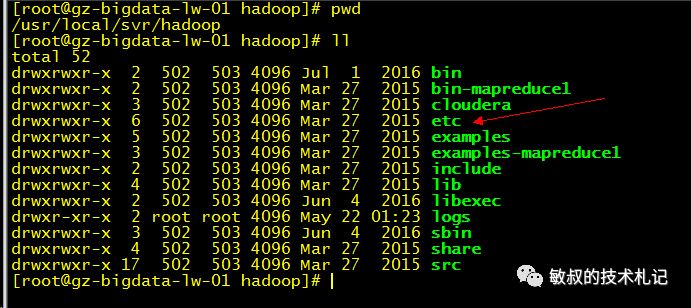
图八:配置文件所在的目录
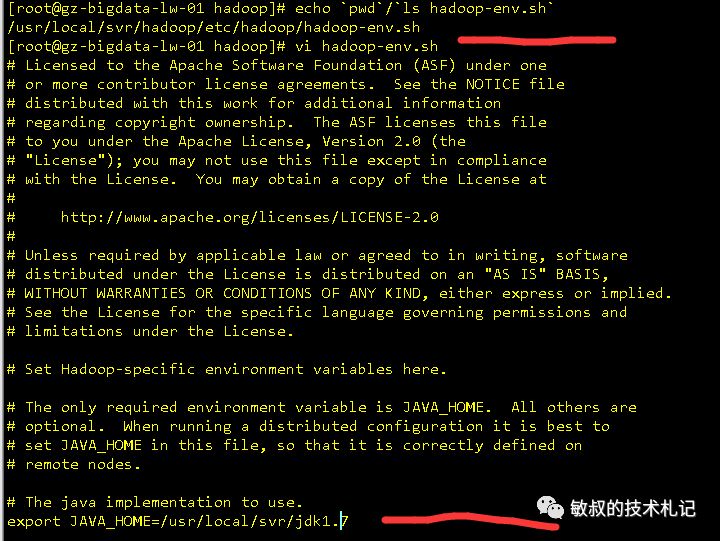
图九:hadoop中jdk的配置
修改配置文件 core-site.xml (vim /usr/local/hadoop/etc/hadoop/core-site.xml),在configuration节点中添加子节点,配置完成之后如下:
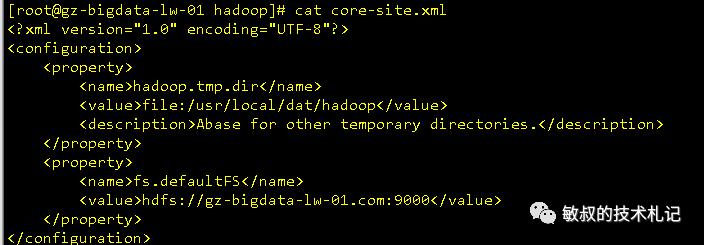
图十:core-site.xml的配置
同样配置hdfs-site.xml:
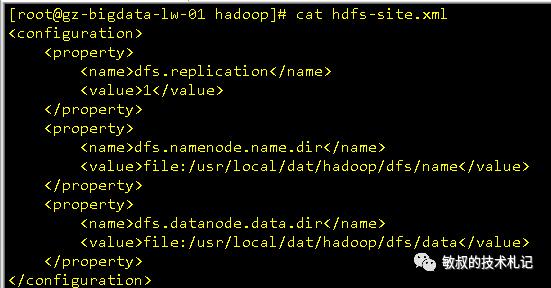
图十一:hdfs-site.xml的配置
还没完,还有设置本机免密码登录:
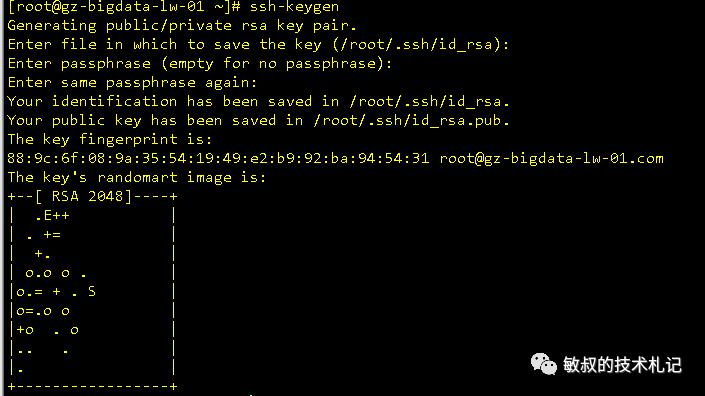
图十二:公钥生成
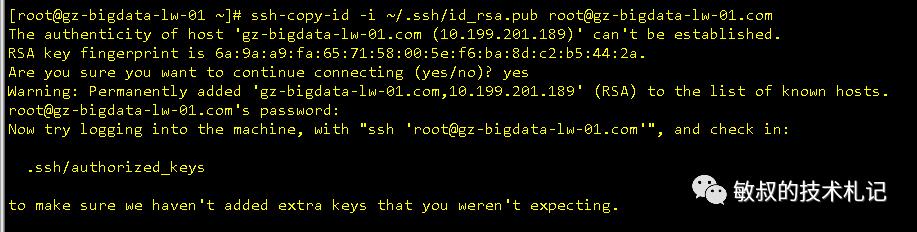
图十三,发送秘钥到远程
测试生成情况,ok

图十四,测试ssh的连接
二、服务的启动和运行
似乎终于到了启动阶段了,当然一般情况写文章或者其他做一些资料的时候,不会体现其中的过程,实际上要启动部署完成一个服务,很容易有错误的情况,这种情况通过不断的修正之后得到解决,这个过程中呢,重要一点,就是要知道怎么查看日志,hadoop的日志默认路径是在hadoop安装目录下面的logs文件夹,这个文件要经常查看,才能了解服务运行的情况。
图十五:日志查看
下面进行服务的启动,这些服务不一定一次可以成功,需要不断查看日志进行跟踪问题。
NameNode格式化:
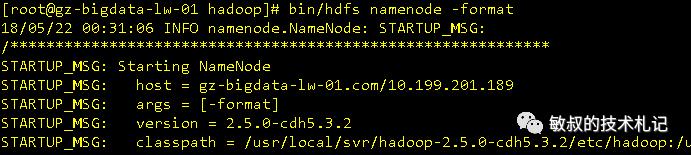
图十六:日志查看
看到 has been successfully formatted.字样,才是格式化成功
启动NameNode:

图十七:日志查看
访问验证:http://10.199.201.189:50070/
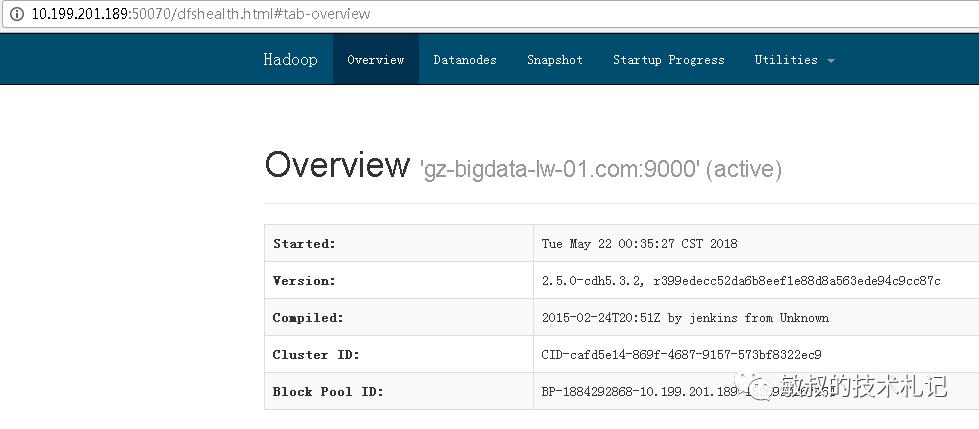
图十八:UI页面
至少我第一次见到这个页面的时候是比较开心的,事情还没完,趁着这股劲,我们把DataNode也启动起来:

图十:JPS进程
可以在页面中找到

已经有一个数据节点了,到这里,最简单的伪分布就算启动完成了。
三、hdfs的初体验
hadoop启动完成,肯定都是希望试一试这个新鲜玩意,hdfs这部分呢,全称叫做分布式文件系统,归根到底,其实就是用来存储的,既然是存储的自然我们想到我们磁盘文件怎么玩的,目录,文件,由此把对文件的操作迁移过来,很容易就可以用起我们的hdfs。
首先hadoop上面的命令都是bin/hdfs操作的,一般是bin/hadoop fs 打头来着,后面接的命令是我们很熟悉的linux命令,比如:文件列表 hadoop fs -ls /、建立目录:hadoop fs -mkdir -p /dat之类的,fs是就是文件系统的意思。下面体验几把,依次完成以下动作,创建目录,上传文件,查看文件内容,查看文件列表 :
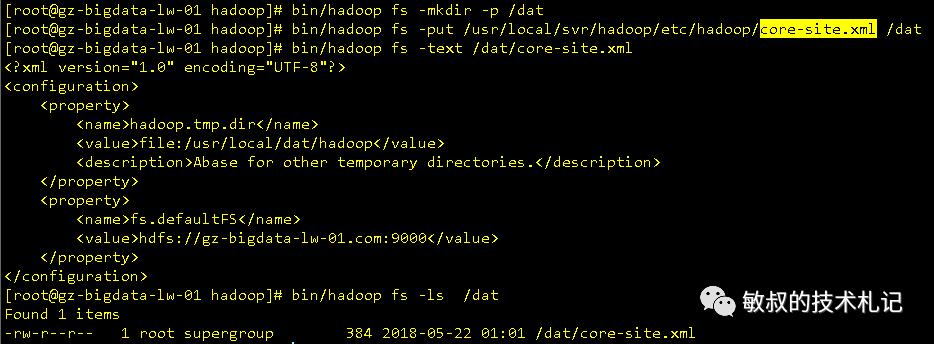
图二十:hdfs操作
我们从浏览器中也可以更直观看到
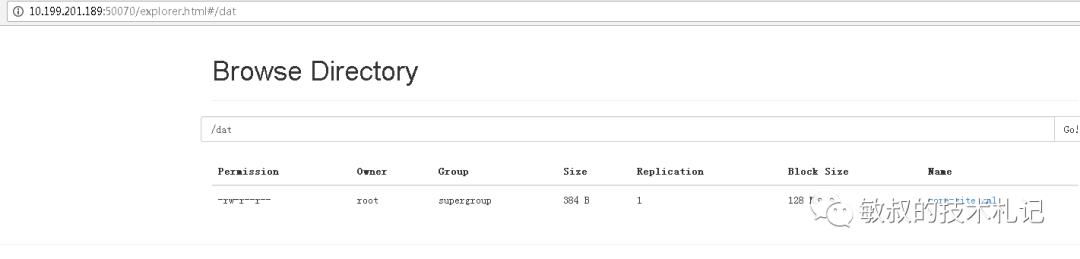
图二十一:ui中直观看到目录结构
其实就是一个磁盘。。。其他命令查看hadoop官网文档,有专门的命令解释
图二十二:官网中的命令
四:配置完善总结篇
1.一键启动的实现
hadoop的各个节点,从根本上来说就是用java命令调用了main函数进行启动,所以实际的命令其实单独启动namenode和datanode就可以了,但是单独启动效率过低,当想一次性进行启动的时候,需要配置etc/slaves文件,这里是表示从节点的配置,单机下面配置本机(gz-bigdata-lw-01.com),然后我们可以使用start-dfs.sh的命令一键进行启动。

图二十三:初尝一键启动
同时我们还看到了secondarynamenode在0.0.0.0上面启动,这也是默认配置导致的,secondarynamenode是早期的备份nn数据的一种机制,后续由ha进行代替,我们在配置项中加入针对secondarynamenode的配置端口就行,在hdfs-site.xml中配置以下数据:
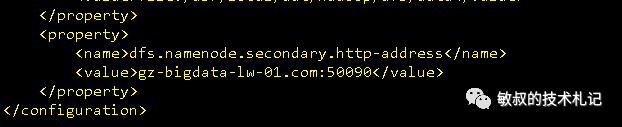
图二十四:secondarynamenode配置
参考的配置是hdfs-default.xml
然后再执行sbin/start-dfs.sh,我们就可以一键进行启动了,酷酷的

图二十五:一键启动
2. 完善命令环境
在前文没有提到jps命令,java程序除了配置在hadoop-env.sh中,还要配置在linux环境变量中才可以使用jps;另外,我们操作hadoop的时候不想每次都去hadoop目录项目去执行命令,这种时候需要把hadoop的命令配置在环境变量中,所以最终我这边的环境变量变成如下:
图二十六:环境变量
然后对应的操作也简化了很多:
图二十七:秀一下
未完待续~
以上是关于初体验Hadoop-伪分布环境的搭建的主要内容,如果未能解决你的问题,请参考以下文章