解决Hadoop的短板,实时大数据分析引擎ClickHouse解析
Posted 京东技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解决Hadoop的短板,实时大数据分析引擎ClickHouse解析相关的知识,希望对你有一定的参考价值。
来这里找志同道合的小伙伴!
一、背景
提到大数据不得不提Hadoop,当下的Hadoop已不仅仅是当初的HDFS + MR(MapReduce)这么简单。基于Hadoop而衍生的Hive、Pig、Spark、Presto、Impala等一系列组件共同构成了Hadoop生态体系。Hadoop生态为今天的大数据领域提供着稳定可靠的数据服务。
Hadoop生态体系解决了大数据界的大部分问题,当然其也存在缺点。Hadoop体系的最大短板在于数据处理时效性。基于Hadoop生态的数据处理场景大部分对时效要求不高,按照传统的做法一般是 T + 1 的数据时效。即 Trade + 1,数据产出在交易日 + 1 天。
ClickHouse的产生就是为了解决大数据量处理的时效性。
二、概述
Clickhouse,专为在线数据分析而设计。官方提供的文档表明,ClickHouse 日处理记录数“十亿级”。
1.特性
采用列式存储
数据压缩
基于磁盘的存储,大部分列式存储数据库为了追求速度,会将数据直接写入内存,按时内存的空间往往很小
CPU利用率高,在计算时会使用机器上的所有CPU资源
支持分片,并且同一个计算任务会在不同分片上并行执行,计算完成后会将结果汇总
支持SQL,SQL几乎成了大数据的标准工具,使用门槛较低
支持联表查询
支持实时更新
自动多副本同步
支持索引
分布式存储查询
2.性能
根据官方提供的数据,性能表现大致如下:
低延迟:对于数据量(几千行,列不是很多)不是很大的短查询,如果数据已经被载入缓存,且使用主码,延迟在50MS左右
并发量:虽然ClickHouse是一种在线分析型数据库,也可支持一定的并发。当单个查询比较短时,官方建议100 Queries / second
写入速度:在使用MergeTree引擎的情况下,写入速度大概是50 - 200M / s,如果按照1 K一条记录来算,大约每秒可写入50000 ~ 200000条记录每秒。如果每条记录比较小的话写入速度会更快
3.接口
对外提供Http,JDBC两种接口方式
对内各模块间使用TCP连接通信
4.与Hadoop的区别
Hadoop体系是一种离线系统,一般很难支持即席查询。ClickHouse可以支持即席查询
Hadoop体系一般不支持实时更新,都采用批量更新和写入。ClickHouse支持实时数据更新
Hadoop体系一般采用行记录存储,数据查询需要扫描所有列,当表很宽时会扫描很多用不到的列。ClickHouse是列式存储,查询只需要加载相关的列。
三、引擎
Clickhouse提供了丰富的存储引擎,存储引擎的类型决定了数据如何存放、如何做备份、如何被检索、是否使用索引。不同的存储引擎在数据写入/检索方面做平衡,以满足不同业务需求。
Clickhouse提供了十多种引擎,这里介绍两种最重要的引擎:MergeTree、Distributed。
1.MergeTree
MergeTree是ClickHouse中最先进的引擎,并由MergeTree衍生出了一系列的引擎,统称MergeTree系引擎。
特性
支持主键索和日期索引
可以提供实时的数据更新
MergeTree是ClickHouse数据库提供的最理想的引擎
MergeTree类型的表必须有一个Date类型列,因为默认情况下数据是按时间进行分区存放的
分区
MergeTree默认分区是以月为单位,同一个月的数据永远都不会被合并
同一个分区的数据会被切割到不同的文件夹中
当有新数据写入时,数据会被写入新的文件夹中,后台会有线程定时对这些文件夹进行合并
每个文件夹中包含当前文件夹范围内的数据,数据按照主码排序,并且每个文件夹中有一个针对该文件夹中数据的索引文件
分区新特性
在老版本的ClickHouse中只支持按月分区
在1.1.54310版之后,支持用户自定义分区
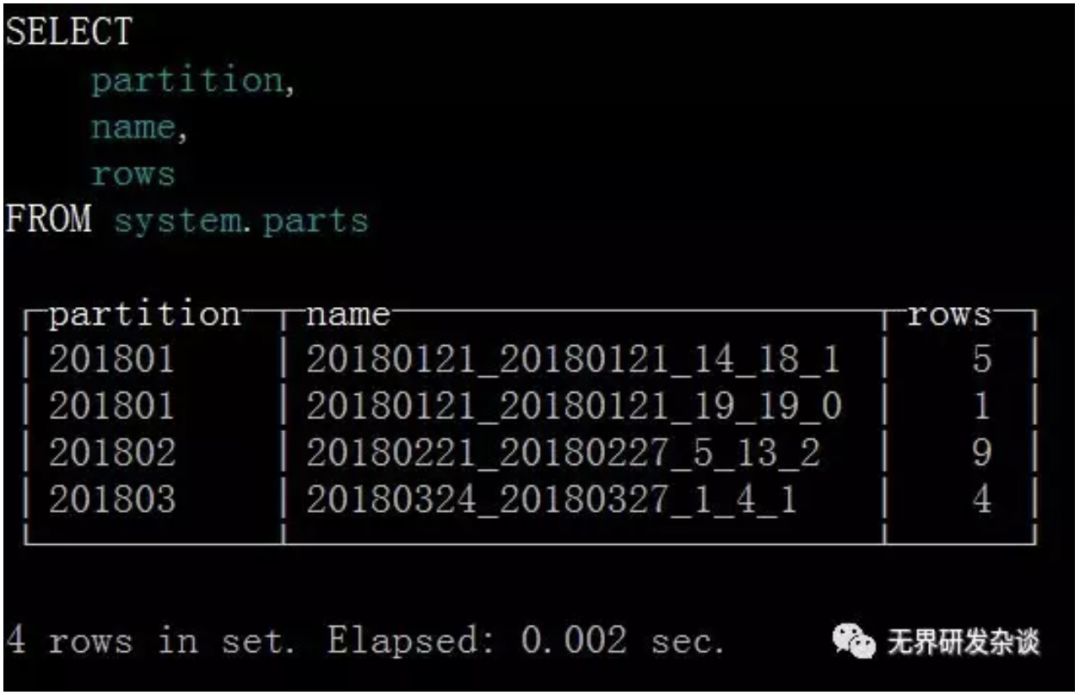
可以通过system.parts表查看表的分区情况
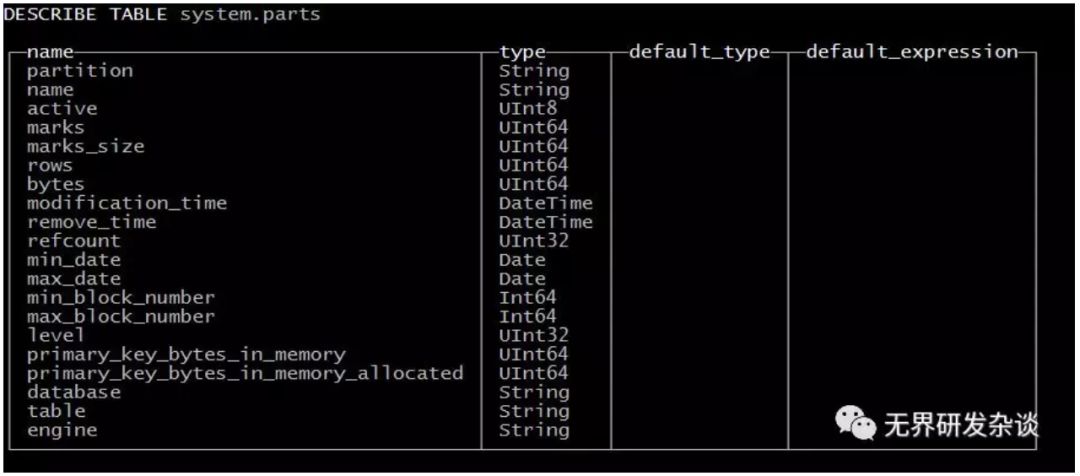
比如某个表存储了2018年1月、2月、3月的数据在同一张表里,数据在磁盘上分布如下图所示
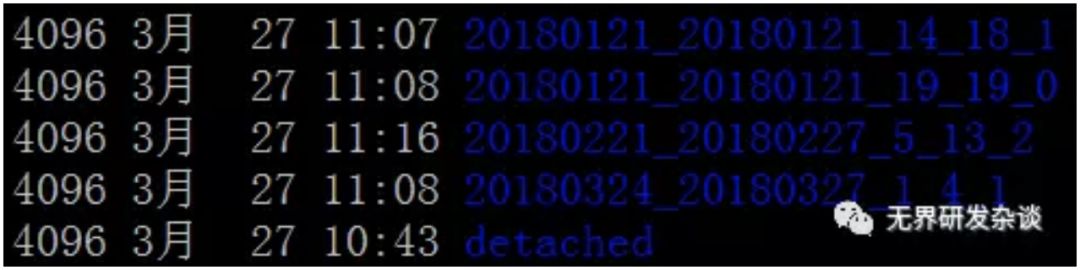
通过查询system.parts可以看出与文件夹一致,数据被分别存储到了4个文件夹中,共分为三个分区:201801、201802、201803
索引
每个数据分区的子文件夹都有一个独立索引
当where子句中在索引列及Date列上做了“等于、不等于、>=、<=、>、<、IN、bool判断”操作,索引就会起作用
Like操作不会使用索引如下面的SQL将不会用到索引
SELECT count()FROM table WHERE CounterID = 34 OR URL LIKE '%upyachka%'
对于日期索引,查询仅仅在包含这些数据的分区上执行
查询时最好指定主码,因为在一个子分区中,数据按照主码存储。所以,当定位到某天的数据文件夹时,如果这一天数据量很大,查询不带主码就会导致大量的数据扫描
2.Distributed
Distributed引擎并不存储真实数据,而是来做分布式写入和查询,与其他引擎配合使用。
比如:Distributed + MergeTree。
根据使用中的经验,一种合理的集群拓扑如下:
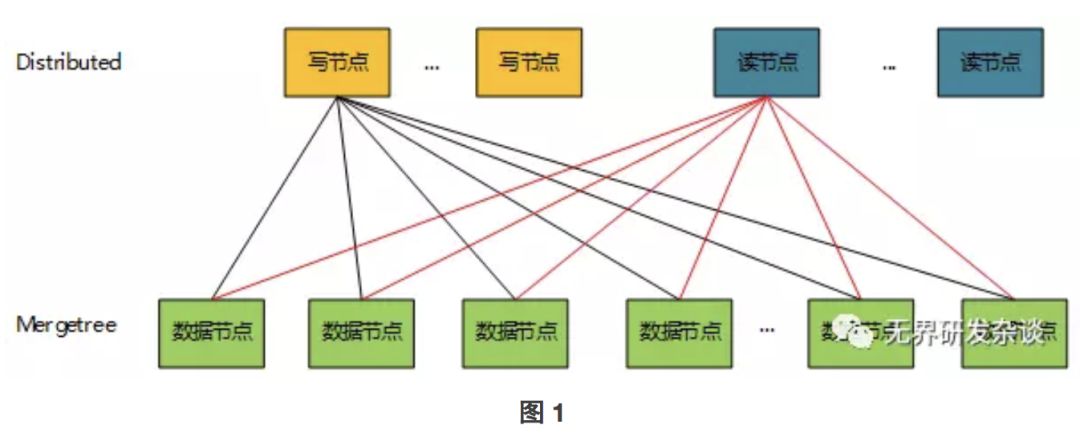
Distributed 引擎可以认为是 Proxy,仅仅存有表结构。
MergeTree 引擎可以认为是 DataNode,存储真实数据。
Distributed 引擎需要指定如下参数:<集群名称,远程数据库名,远程表名,分片规则>
集群名:即当前集群名称。
远程数据库名:比如存储具体数据的MergeTree引擎的数据库名
远程表名:存储真实数据的表的名字。
分片规则:可选。
分片:一个 Distributed 表可以被切成多个分片(shard),分片之间没有数据重合。
副本:一个 Distributed 分片可以有多个副本,副本的数据完全相同。
数据读取过程:
查询被分发到远程shards上去并行执行
当查询一个副本连接失败,会尝试其他副本
查询会使用远程服务器上引擎的索引
数据聚合之类的操作也会先在远程数据Node上进行,然后把中间结果发送到Distributed引擎所在服务器,做进一步聚合
数据写入过程:
有两种数据写入方式:
直接将数据写入数据节点。这是最优的方式,因为数据是被分布式的并发写到每台数据节点上,效率会更高。如图2所示
将数据写入distributed表。Distributed表再根据 shardingkey将数据分发到相应的shard上去。如图1方式
四、Clickhouse不足
不支持事务
聚合操作取决于单台机器的 RAM
资料及文档较少、运维困难
---------------------END---------------------
下面的内容同样精彩
点击图片即可阅读
以上是关于解决Hadoop的短板,实时大数据分析引擎ClickHouse解析的主要内容,如果未能解决你的问题,请参考以下文章