hadoop
Posted 卡尼慕
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop相关的知识,希望对你有一定的参考价值。
这是卡尼慕的第n篇文章
这段时间不光在复习数据结构,也在学习搭建hadoop,了解hadoop,这是对我来说没有像其它的的推文那样好写,而且这个模块更新的时间间隔会比较长,因为一个新知识是要消化吸收的。我也不可能把错误的知识接受给你们吧,所以一般来说,我会在周末更新数据结构。见谅哈~

Hadoop
Hadoop肯定很多人都听过他的大名,近几年因为人工智能也火得不得了,那么Hadoop是什么能?他能做什么呢?为什么学习大数据需要使用到Hadoop呢?
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的硬件上;而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。HDFS放宽了POSIX的要求,可以以流的形式访问文件系统中的数据。(来源于百度百科)
ok,我们再来看看官方文档。
The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
大致翻译了一下,是这个意思。
apache项目开发了用于可靠,可扩展的分布式计算的开源软件。
Hadoop软件库是一个框架,允许使用简单的编程模型跨计算机集群分布式处理大型数据集。它旨在从单个服务器扩展到数千台计算机,每台计算机都提供本地计算和存储。库本身不是依靠硬件来提供高可用性,而是设计用于检测和处理应用程序层的故障,从而在计算机集群之上提供高可用性服务,每个计算机都可能容易出现故障。
OK,如果你说没心情看,或者看了还模模糊糊,云里雾里,那么你只要记好下面几个关键词:Apache Hadoop,分布式系统架构,HDFS,MapReduce。
Hadoop是在分布式服务器集群上存储海量数据并运行分布式分析应用的一个平台,其核心部件是HDFS与MapReduce。
其中HDFS是分布式文件系统,传统文件系统的硬盘寻址慢,通过引入存放文件信息的服务器Namenode和实际存放数据的服务器Datanode进行串接。对数据系统进行分布式储存读取。
MapReduce是一个计算框架:MapReduce的核心思想是把计算任务分配给集群内的服务器里执行。通过对计算任务的拆分再根据任务调度器对任务进行分布式计算。
架构
Hadoop在2.0将资源管理从MapReduce中独立出来变成通用框架后,就从1.0的三层结构演变为了现在的四层架构。
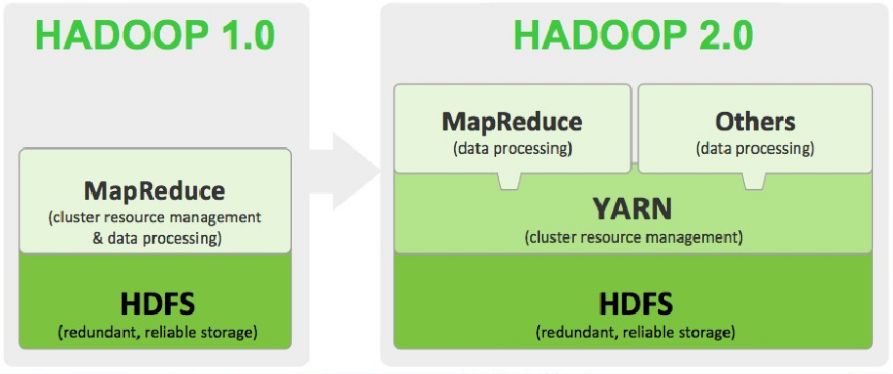
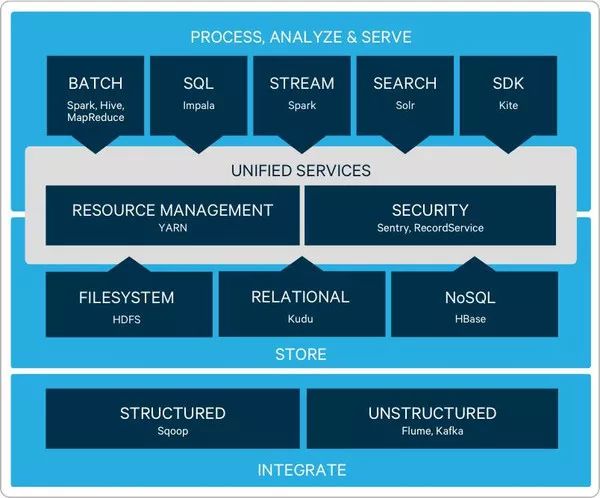
底层——存储层,文件系统HDFS
中间层——资源及数据管理层,YARN以及Sentry等
上层——MapReduce、Impala、Spark等计算引擎
顶层——基于MapReduce、Spark等计算引擎的高级封装及工具,如Hive、Pig、Mahout等等
架构—存储层
HDFS已经成为了大数据磁盘存储的事实标准,用于海量日志类大文件的在线存储。
经过这些年的发展,HDFS的架构和功能基本固化,像HA、异构存储、本地数据短路访问等重要特性已经实现,在路线图中除了Erasure Code已经没什么让人兴奋的feature。
随着HDFS越来越稳定,社区的活跃度也越来越低,同时HDFS的使用场景也变得成熟和固定,而上层会有越来越多的文件格式封装:列式存储的文件格式,如Parquent,很好的解决了现有BI类数据分析场景;以后还会出现新的存储格式来适应更多的应用场景,如数组存储来服务机器学习类应用等。未来HDFS会继续扩展对于新兴存储介质和服务器架构的支持。
2015年HBase 发布了1.0版本,这也代表着 HBase 走向了稳定。未来HBase不会再添加大的新功能,而将会更多的在稳定性和性能方面进化,尤其是大内存支持、内存GC效率等。
Kudu是Cloudera在2015年10月才对外公布的新的分布式存储架构,与HDFS完全独立其出现将进一步把Hadoop市场向传统数据仓库市场靠拢。
Apache Arrow项目为列式内存存储的处理和交互提供了规范。目前来自Apache Hadoop社区的开发者们致力于将它制定为大数据系统项目的事实性标准。
架构—管理层
管控又分为数据管控和资源管控。
随着Hadoop集群规模的增大以及对外服务的扩展,如何有效可靠的共享利用资源是管控层需要解决的问题。脱胎于MapReduce1.0的YARN成为了Hadoop 2.0通用资源管理平台。
由于占据了Hadoop的地利,业界对其在资源管理领域未来的前景非常看好。传统其他资源管理框架如Mesos,还有现在兴起的Docker等都会对YARN未来的发展产生影响。
如何提高YARN性能、如何与容器技术深度融合,如何更好的适应短任务的调度,如何更完整的多租户支持、如何细粒度的资源管控等都是企业实际生产中迫在眉睫的需求,需要YARN解决。要让Hadoop走得更远,未来YARN需要做的工作还很多。
架构—计算引擎层
Hadoop生态和其他生态最大的不同之一就是“单一平台多种应用”的理念了。传的数据库底层只有一个引擎,只处理关系型应用,所以是“单一平台单一应用”;而NoSQL市场有上百个NoSQL软件,每一个都针对不同的应用场景且完全独立,因此是“多平台多应用”的模式。而Hadoop在底层共用一份HDFS存储,上层有很多个组件分别服务多种应用场景。
确定性数据分析:主要是简单的数据统计任务,例如OLAP,关注快速响应,实现组件有Impala等;
探索性数据分析:主要是信息关联性发现任务,例如搜索,关注非结构化全量信息收集,实现组件有Search等;
预测性数据分析:主要是机器学习类任务,例如逻辑回归等,关注计算模型的先进性和计算能力,实现组件有Spark、MapReduce等;
数据处理及转化:主要是ETL类任务,例如数据管道等,关注IO吞吐率和可靠性,实现组件有MapReduce等;
Hadoop的优点
1、高可靠性 Hadoop按位存储和处理数据的能力值得人们信赖。
2、高扩展性 Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
3、高效性 Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
4、高容错性 Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
5、低成本 与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
Hadoop带有用Java语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。Hadoop 上的应用程序也可以使用其他语言编写,比如 C++。

向左滑动


程序猿
改变世界
以上是关于hadoop的主要内容,如果未能解决你的问题,请参考以下文章