Hadoop之Apache Kafka
Posted 程序猿的修身养性
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop之Apache Kafka相关的知识,希望对你有一定的参考价值。
1、Kafka概述
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编程语言编写,它是一个高吞吐量、支持分区(partition)的、多副本(replica)的、基于Zookeeper协调的、采用发布者-订阅者模型的分布式消息系统,最大的特点是可以实时处理大量数据以满足各种应用场景,诸如基于Hadoop的批处理系统、低延迟的实时系统、Storm/Spark流式处理引擎、Web/nginx日志、消息服务等等。
在大数据系统中,常常会碰到一个问题,整个大数据系统由多个子系统组成,数据需要在各个子系统之间高效率、低延迟地不停流转。传统的企业级消息系统并不是很适合大规模的数据处理,为了同时解决在线应用(消息)和离线应用(数据文件、日志)的需求,Kafka应运而生,它在这之中可以起到两个作用:
(1)降低各个系统之间组网的复杂度;
(2)降低编程复杂度,各个系统不再需要相互之间协商接口,而更像是插口插在插座上,Kafka承担了高速数据总线的作用。
2、Kafka的特性
Kafka作为一个分布式消息系统,它具有非常多优良的特性,其中几个最主要的列举如下:
高吞吐量、低延迟:Kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个Topic可以分成多个partition(分区),而consumer group(消费者组)对partition进行consume(消费)操作;
可扩展性:Kafka集群支持热扩展;
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失;
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败);
高并发:支持数千个客户端同时读写。
3、Kafka的应用场景
Kafka是一个非常优秀的消息系统,它拥有的众多特性为其广泛应用打下了坚实的基础,主要应用领域列举如下:
日志收集:日志收集方面,其实开源产品有很多,包括Scribe、Apache Flume等,很多人使用Kafka代替日志聚合(log aggregation)。日志聚合,一般来说是从服务器上收集日志文件,然后放到一个集中的位置(如文件服务器或HDFS)进行处理。然而,Kafka忽略掉文件的细节,将其更清晰地抽象成一个个日志或事件的消息流。这就让Kafka的处理过程延迟更低,更容易支持多数据源和分布式数据处理。比起以日志为中心的系统,如Scribe或者Flume来说,Kafka提供同样高效的性能和因为复制导致的更高的耐用性保证,以及更低的端到端延迟;
消息队列:比起大多数的消息系统来说,Kafka有更好的吞吐量,内置的分区、冗余及容错性等,让Kafka成为一个很好的大规模消息处理的解决方案。消息系统一般吞吐量相对较低,但是需要更小的端到端延时,并常常依赖于Kafka提供的强大的持久性保障,在这个领域,Kafka足以媲美传统消息系统,如ActiveMR或RabbitMQ;
行为跟踪:Kafka的另一个应用场景是跟踪用户的浏览页面、搜索及其他行为,然后以发布-订阅的模式实时记录到对应的Topic里。那么这些结果被订阅者拿到后,就可以做进一步的实时处理,或实时监控,或放到Hadoop/数据仓库中做离线分析和数据挖掘等;
元信息监控:这通常是作为操作记录的监控模块来使用,即汇集记录一些操作信息,可以理解为运维性质的数据监控;
流式处理:这个的应用场景非常多,也很好理解,保存采集的流数据,以提供之后对接的Storm或其他流式计算框架进行处理。很多用户会将那些从原始Topic来的数据进行阶段性处理、汇总、扩充或者以其他的方式转换到新的Topic下再继续后面的处理,比如一个文章推荐的处理流程,可能是先从RSS数据源中抓取文章的内容,然后将其丢入一个叫做“文章”的Topic中,后续操作可能是需要对这个内容进行清理,比如回复正常数据或者删除重复数据,最后再将内容匹配的结果返还给用户。这就在一个独立的Topic之外,产生了一系列的实时数据处理的流程,Storm和Samza是非常著名的实现这种类型数据转换的框架;
事件源:事件源是一种应用程序设计的方式,该方式的状态转移被记录为按时间顺序排序的记录序列,Kafka可以存储大量的日志数据,这使得它成为一个对使用这种方式的应用来说绝佳的后台,比如动态汇总。
持久性日志(commit log):Kafka可以为一种外部的持久性日志的分布式系统提供服务,这种日志可以在节点间备份数据,并为故障节点数据恢复提供一种重新同步的机制。Kafka中日志压缩功能为这种用法提供了条件,在这种用法中,Kafka类似于Apache Zookkeeper项目。
4、Kafka的基本架构
一个典型的Kafka体系结构包括若干Producer(可以是服务器日志、业务数据、网页前端产生的page view等等),若干Broker(Kafka支持水平扩展,一般Broker数量越多,集群吞吐率也越高),若干Consumer(支持消费者组Group),以及一个Zookeeper集群。这些部件组成的体系结构如下图所示:
Kafka的整体结构非常简单,是显示的分布式结构,Producer、Broker(Kafka主体)和Consumer都可以有多个。Producer和Consumer实现Kafka注册的接口,数据从Producer发送到Broker,Broker起到一个中间缓存和分发的作用,然后再由Broker分发给注册到系统中的Consumer。Broker的作用类似于缓存,即活跃的数据和离线处理系统之间的缓存,客户端和服务器端的通信,是基于简单、高性能且与编程语言无关的TCP协议。下面稍加解释这几个概念:
Topic:特指Kafka处理的消息源的不同分类,Kafka根据Topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个Topic;
Broker:消息中间件处理节点,也可以叫做缓存代理,一个Kafka节点就是一个Broker,一个或者多个Broker可以组成一个Kafka集群;
Producer:消息或数据的生产者,向Kafka的一个Topic发布消息的过程叫做Producer,可简单看作是向Broker发送消息的客户端;
Consumer:消息或数据的消费者,订阅Topics并处理发布的消息的过程叫做Consumer,可简单看作是从Broker读取消息的客户端;
Message:消息,通信的基本单位,每个Producer可以向一个Topic(主题)发布一些消息;
Partition:Topic物理上的分组,一个Topic可以分为多个Partition,每个Partition是一个有序的队列,Partition中的每条消息都会被分配一个有序的id(offset);
ConsumerGroup:每个Consumer属于一个特定的ConsumerGroup,一条消息可以发送到多个不同的ConsumerGroup,但是一个ConsumerGroup中只能有一个Consumer能够消息某个消息。
5、Kafka消息发送流程
Kafka中的消息发送流程同样非常简单,如下图所示:
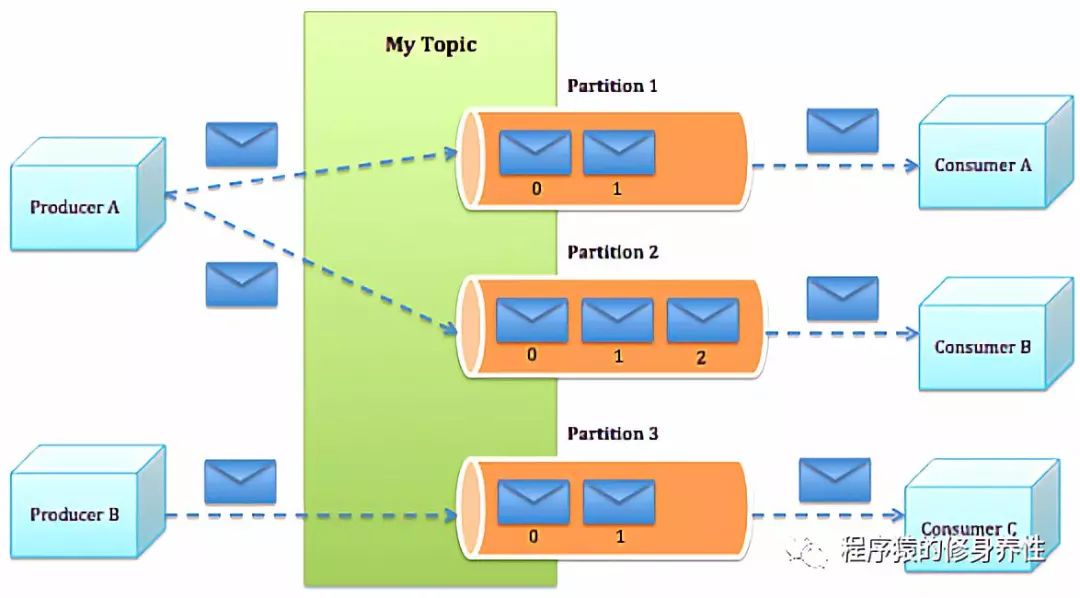
Producer根据指定的Partition方法(如round-robin、hash等),将消息发布到指定的Topic的Partition里面;
Kafka集群接收到Producer发送过来的消息后,将其持久化到磁盘,并保留消息指定的时间(该数值可通过参数进行配置),而不关注消息是否被消费;
Consumer从Kafka集群pull数据,并控制获取消息的offset。
6、Kafka操作实践
总体来说,Kafka有三种安装模式,分别是单机单Broker方式、单机多Broker方式以及多机多Broker方式。下面分别进行介绍。
A、单机单Broker方式
将Kafka安装包kafka_2.9.2-0.8.1.1.tgz上传到主机hadoop221的/root/tools目录下,运行命令tar -zxvf kafka_2.9.2-0.8.1.1.tgz -C /root/training/,将Kafka安装包解压到/root/training/目录下,然后为Kafka配置环境变量,运行命令vi /root/.bash_profile进行编辑,在文件末尾添加如下内容:
KAFKA_HOME=/root/training/kafka_2.9.2-0.8.1.1
export KAFKA_HOME
PATH=$KAFKA_HOME/bin:$PATH
export PATH
保存退出,然后运行命令source /root/.bash_profile,使环境变量生效。接下来配置Kafka的核心配置文件server.properties,该文件位于config目录下,进入到/root/training/kafka_2.9.2-0.8.1.1/config目录下,运行命令vi server.properties编辑文件,将参数log.dirs的内容修改为:log.dirs=/root/training/kafka_2.9.2-0.8.1.1/logs,将参数zookeeper.connect修改为:zookeeper.connect=hadoop221:2181,保存退出;最后运行命令mkdir logs创建logs目录,用于存放Kafka运行过程中产生的log。
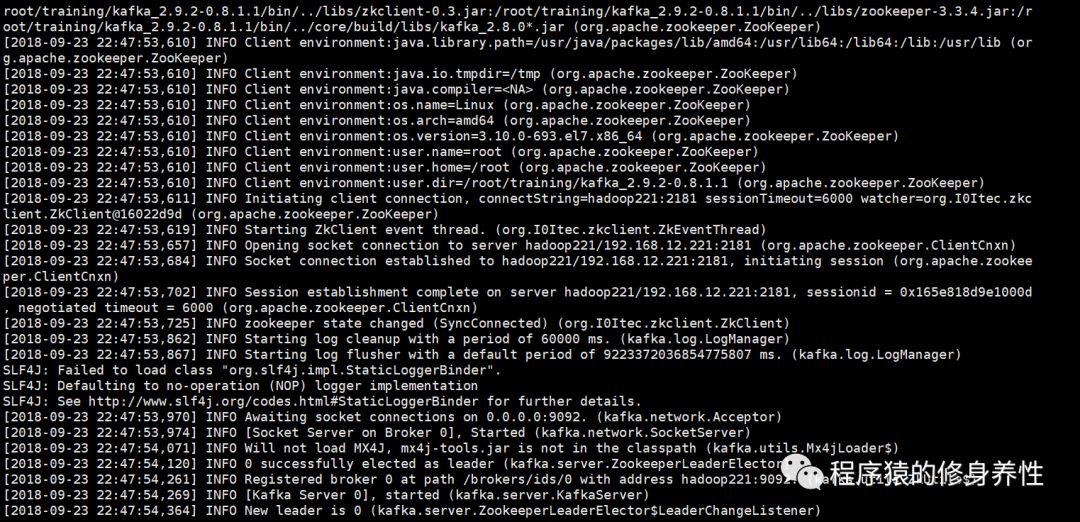
至此,Kafka的单机单Broker方式配置完成。下面进行实践操作,测试下Kafka的运行效果。首先,确保单机模式的Zookeeper已经启动起来,若还没有启动,则运行命令zkServer.shstart,启动Zookeeper;然后运行命令kafka-server-start.shconfig/server.properties &,以后台方式启动Kafka。输出的部分关键log,如下图所示:
创建Topic
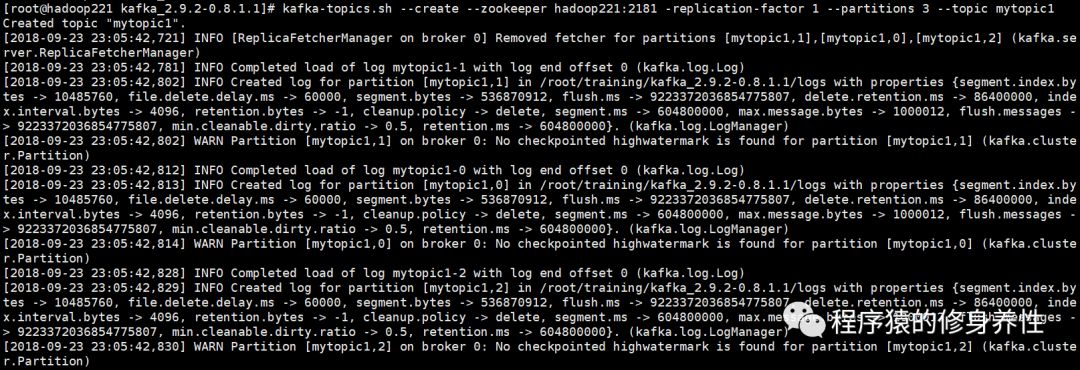
运行命令:kafka-topics.sh --create --zookeeper hadoop221:2181-replication-factor 1 --partitions 3 --topic mytopic1,创建名称为mytopic1的Topic,输出的log如下图所示:
发送消息
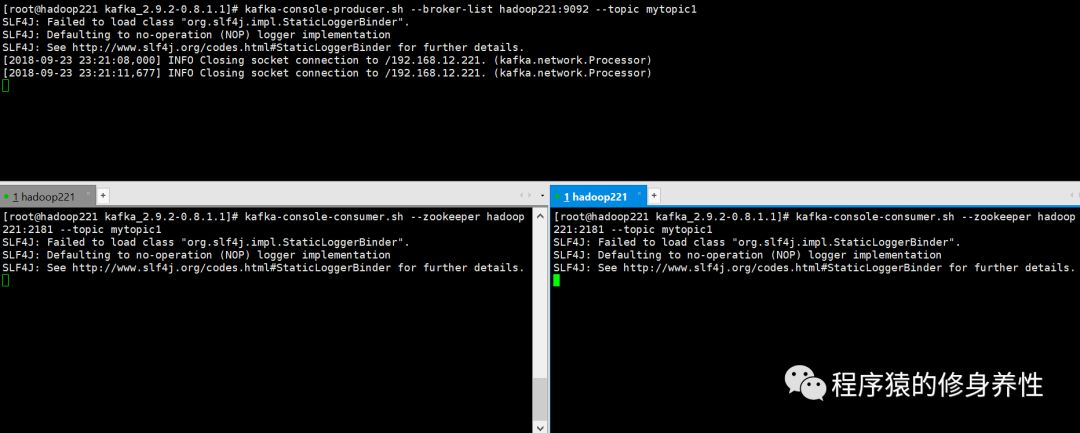
运行命令:kafka-console-producer.sh --broker-list hadoop221:9092 --topic mytopic1,启动生产者线程。
接收消息
运行命令:kafka-console-consumer.sh --zookeeper hadoop221:2181--topic mytopic1,启动消费者线程。
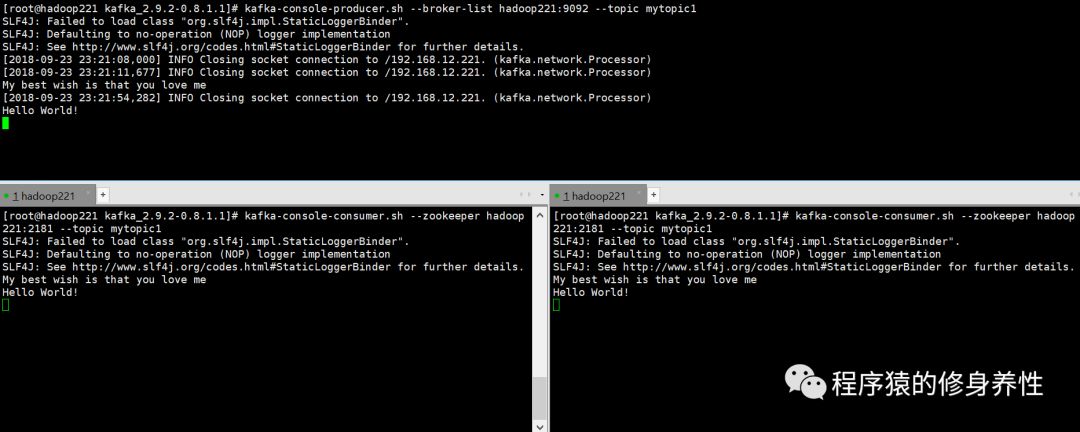
在一个连接窗口中启动生产者线程,在另外两个连接窗口中启动分别启动消费者线程,如下图所示:
在生产者窗口中相继输入两行字符串,My best wishis that you love me(输完按回车键)和Hello World!(输完按回车键),在两个消费者窗口中相继显示出了这两条消息,如下图所示:
B、单机多Broker方式
前面已经安装和配置好了Kafka的单机单Broker方式,在其基础之上,现在来配置Kafka的单机多Broker方式。停止Kafka的运行,进入到/root/training/kafka_2.9.2-0.8.1.1/config目录下,依次运行命令:
cp server.properties server0.properties
cp server.properties server1.properties
cp server.properties server2.properties
cp server.properties server3.properties
保持配置文件server0.properties中的配置不变;配置文件server1.properties中相应修改如下:
broker.id=1
port=9093
log.dirs=/root/training/kafka_2.9.2-0.8.1.1/logs1
并在目录/root/training/kafka_2.9.2-0.8.1.1下创建logs1目录;
配置文件server2.properties中相应修改如下:
broker.id=2
port=9094
log.dirs=/root/training/kafka_2.9.2-0.8.1.1/logs2
并在目录/root/training/kafka_2.9.2-0.8.1.1下创建logs2目录;
配置文件server3.properties中相应修改如下:
broker.id=3
port=9095
log.dirs=/root/training/kafka_2.9.2-0.8.1.1/logs3
并在目录/root/training/kafka_2.9.2-0.8.1.1下创建logs3目录;
最后,依次运行如下四条命令:
kafka-server-start.sh config/server0.properties &
kafka-server-start.sh config/server1.properties &
kafka-server-start.sh config/server2.properties &
kafka-server-start.sh config/server3.properties &
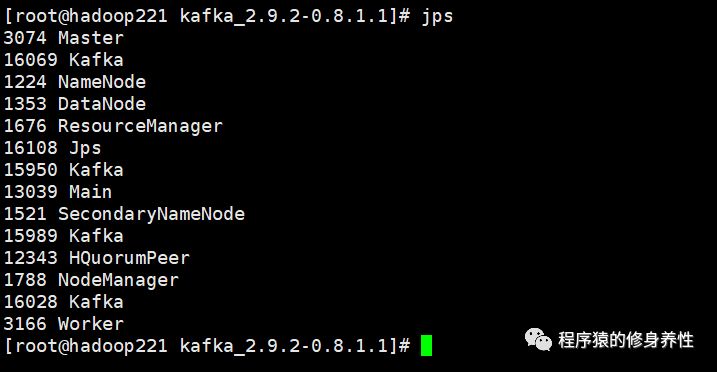
然后运行命令jps,如下图所示,可以看到启动了4个Kafka实例Broker。接下来创建主题,创建生产者线程及消费者线程完全同前面一致,这里不再赘述。
C、多机多Broker方式
这里先在主机hadoop222上进行Kafka的安装和配置,然后将配置好的Kafka目录通过网络拷贝到主机hadoop223和主机hadoop224上。
将Kafka安装包kafka_2.9.2-0.8.1.1.tgz上传到主机hadoop222的/root/tools目录下,运行命令tar -zxvfkafka_2.9.2-0.8.1.1.tgz -C /root/training/,将Kafka安装包解压到/root/training/目录下,然后配置Kafka的环境变量,运行命令vi /root/.bash_profile,在文件末尾添加如下内容:
KAFKA_HOME=/root/training/kafka_2.9.2-0.8.1.1
export KAFKA_HOME
PATH=$KAFKA_HOME/bin:$PATH
export PATH
保存退出,并运行命令source/root/.bash_profile,使环境变量生效。在主机hadoop223和主机hadoop224进行同样的操作,一并配置好Kafka的环境变量。
下面在主机hadoop222上配置Kafka的核心配置文件server.properties,进入到/root/training/kafka_2.9.2-0.8.1.1/config目录,依次运行命令:
cp server.properties server0.properties
cp server.properties server1.properties
cp server.properties server2.properties
配置文件server0.properties,修改如下:
broker.id=0
port=9092
log.dirs=/root/training/kafka_2.9.2-0.8.1.1/logs0
zookeeper.connect=hadoop222:2181,hadoop223:2181,hadoop224:2181
配置文件server1.properties,修改如下:
broker.id=1
port=9093
log.dirs=/root/training/kafka_2.9.2-0.8.1.1/logs1
zookeeper.connect= hadoop222:2181,hadoop223:2181,hadoop224:2181
配置文件server2.properties,修改如下:
broker.id=2
port=9094
log.dirs=/root/training/kafka_2.9.2-0.8.1.1/logs2
zookeeper.connect= hadoop222:2181,hadoop223:2181,hadoop224:2181
进入到/root/training/kafka_2.9.2-0.8.1.1目录,依次创建logs0,logs1,logs2三个目录。
最后依次运行如下两条命令,将配置好的Kafka分别拷贝到主机hadoop223和主机hadoop224的/root/training目录下:
scp -r/root/training/kafka_2.9.2-0.8.1.1/ root@hadoop223:/root/training
scp -r/root/training/kafka_2.9.2-0.8.1.1/ root@hadoop224:/root/training
注意,在同一台主机上,端口号port不能相同,因此依次配置为9092,9093,9094;同时,在不同主机上,broker.id均不能相同,因此在主机hadoop223上的三个配置文件server.properties中的broker.id依次配置为3,4,5,在主机hadoop224上的三个配置文件server.properties中的broker.id依次配置为6,7,8。
下面在三台主机上依次启动配置好的3个Kafka Broker实例,在主机hadoop222上,在主机hadoop223上,在主机hadoop224上依次运行命令:
kafka-server-start.sh config/server0.properties &
kafka-server-start.sh config/server1.properties &
kafka-server-start.sh config/server2.properties &
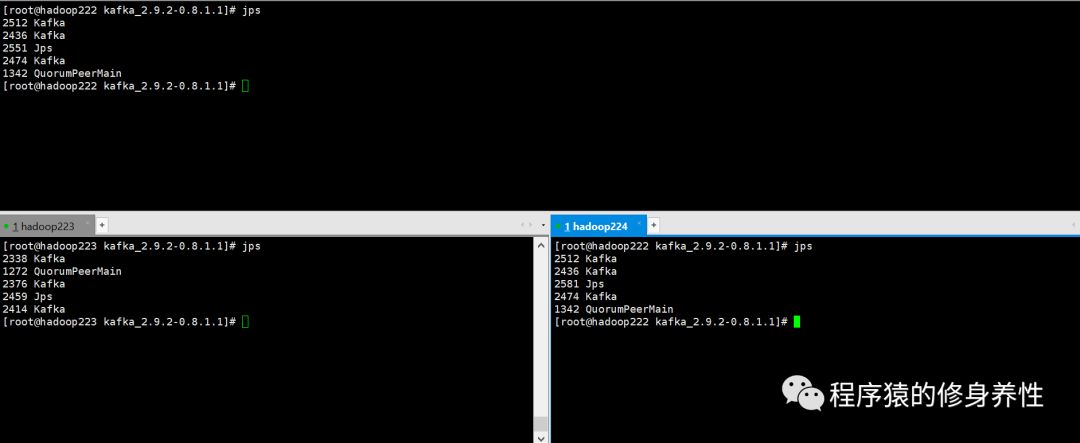
运行结束后,三台主机上运行进程的情况如下图所示:
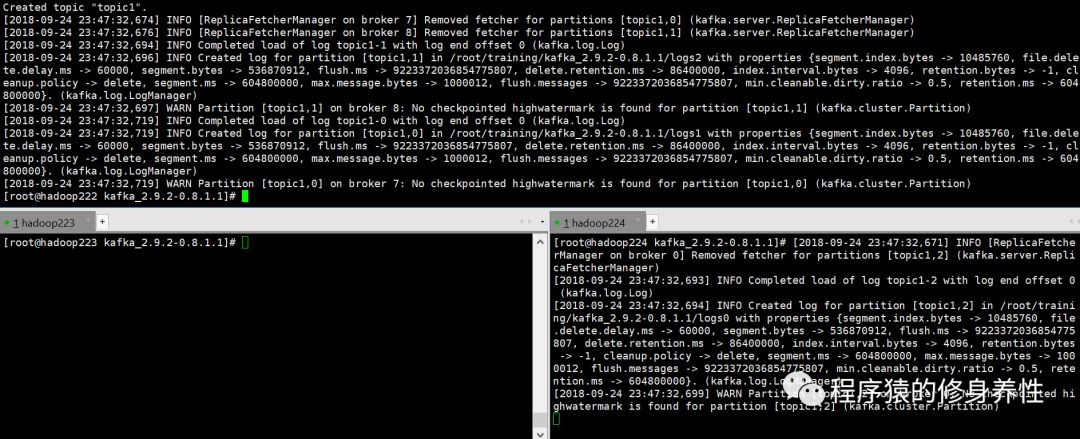
在主机hadoop222上创建主题mytopic235,运行命令kafka-topics.sh --create--zookeeper hadoop222:2181 -replication-factor 1 --partitions 3 --topic topic1,界面输出log如下图所示,注意下面的两个窗口有时候会有log输出,有时候不输出,搞不懂,但不影响。
再在主机hadoop222上创建生产者线程,运行命令:kafka-console-producer.sh--broker-list hadoop222:9092 --topic topic1,在主机hadoop223和主机hadoop224上分别创建消费者线程,运行命令:kafka-console-consumer.sh--zookeeper hadoop222:2181 --topic topic1,输出log如下图所示:
最后在主机hadoop222窗口中输入字符串:Best wishes to you!,按回车键发送;接着再输入字符串:I missyou!,按回车键发送,界面运行效果如下图所示:
以上是关于Hadoop之Apache Kafka的主要内容,如果未能解决你的问题,请参考以下文章