Hadoop必知必会一
Posted frost2
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop必知必会一相关的知识,希望对你有一定的参考价值。
HDFS
一、Hadoop
Hadoop介绍:
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
Hadoop的版本:
Hadoop1.0:HDFS和MapReduce。
Hadoop2.0:完全重构的一套系统,不兼容1.0。包含了HDFS、MapReduce和Yarn。
Hadoop3.0:包含了HDFS、MapReduce、Yarn以及Ozone。
Hadoop的模块:
Hadoop Common:基本模块。
Hadoop-Distributed-File-System(HDFS):进行数据的分布式存储。
Hadoop YARN:进行任务调度和节点资源管理
Hadoop MapReduce:基于Yarn对海量数据进行并行处理
Hadoop Ozone:基于HDFS进行对象的存储
二、HDFS
1、定义:
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统。是根据google发表的论文GFS(Google File System)Google 文件系统设计出的。
2、HDFS的优缺:
优点:
支持超大文件:将文件进行切块分别存储到不同的节点上存储。
检测和快速应对硬件故障:心跳机制。
流式数据访问。
简化的一致性模型:只要一个文件块写好,那么这个文件块就不允许在进行改动,只能读取。
高容错性:多复本。
可构建在廉价机器上:这就使得HDFS具有较好的扩展性。
缺点:
高延迟数据访问:不适合于交互式,也就意味着Hadoop不适合做实时分析,而是做的离线分析。
不适合存储大量的小文件:文件的存储要经过namenode,namenode中要记录元数据,元数据是存储在内存中。大量的小文件会产生大量的元数据,导致内存被大量占用,降低namenode的处理效率。
不支持多用户写入文件、修改文件:在hadoop2.0版本中,不支持修改,但是支持追加。
3、HDFS的存储时的一些基本知识:
datanode:存储数据的节点
namenode:管理数据的节点 ,管理dataname.
HDFS存储数据的时候会将文件进行切块,并且给每一个文件块分配一个递增的编号
HDFS会对数据进行备份,每一个备份称之为是一个复本。在伪分布式下,复本设置为1,但是在全分布式下,复本默认是3个
3个复本放到不同的datanode中。复本放置策略是机架感知策略,如下:
第一个复本:客户端连接的是哪一个datanode,复本就放到哪一个datanode上
第二个复本:要放到另一个机架的datanode上
第三个复本:放到和第二个复本同机架的另一个datanode上
如果有更多的复本数量,其他的复本随机放到其他的datanode
如果某一个datanode宕机,那么这个时候namenode就会将这个datanode上所存放的复本进行复制,保证整个hdfs中有指定的复本数量。
元数据(metadata):即namenode中存储管理信息。
存储的信息:FileName replicas block-Ids id2host
具体例如:/test/a.log,3,{b1,b2},[{b1:[h0,h1,h3]},{b2:[h0,h2,h4]}]
上面具体信息表示:存储的文件是a.log文件,存储在/test路径下,复本数量为3,切了2块,编号分别为b1,b2,b1存放在h0,h1,h3节点下,b2存放在h0,h2,h4节点下。
4、HDFS知识点解释:
A.Block(数据分块):
HDFS在存储数据的时候是将数据进行切块,分别存储到不同的节点上。
在Hadoop1.0版本中,每一个block默认是64M大小。
在Hadoop2.0版本中,每一个block默认是128M大小。
这样存储有利于大文件的存储、方便传输、便于计算。
B.NameNode:
负责datanode的管理以及元数据的存储。
元数据存储在内存中(为了快速查询)和磁盘中(用于崩溃恢复)中。
在NameNode中有两类文件以fsimage开头和以edits开头的文件。
其中fsimage负责存储元数据。但是其中的数据元数据与内存中的并不一定一致,也就意味着fsimage中的数据并不是实时更新的。而edits则是存储HDFS的操作的。至于为什么是这样,看完下面的NameNode的执行过程你就明白了。
C.NameNode的执行过程:
当你执行HDFS的命令hadoop fs -put a.txt /时,首先会将你执行的命令放在edits文件中。
成功放入edits中后,再将操作更新到内存中。这样做的目的是防止数据丢失,因为一旦namenode挂了,内存中的数据将会丢失,但如果我们先将操作存到磁盘中,则会避免这种问题。
再执行一个操作hadoop fs -mkdir /node1,此时重复上述步骤。
当edits中的操作增加,达到触发条件时,再将edits文件中的操作更新到fsimage中。这也就是为什么fsimage中的数据与元数据不一定一致的原因。
触发条件如下:
文件大小达到条件,默认为64MB。
定时更新,默认3600秒更新一次。这里有一个问题例如:在12点更行一次,但是在12点30分时文件大小达到64MB又更新了一次,那下次定时更新是什么时候呢?应该是上一次更新的一个小时后即1点30分。之所以可以这样实现,是因为HDFS将每次更新的时间都记录在fstime文件中,它与fsimage和edits都在namenode下。
重启hdfs的时候触发更新(实际中不常见),此时只提供读服务,不提供写服务。我们将HDFS重启时的更新阶段称为安全模式。
D.安全模式:
只能读不能写。
安全模式下会检查你设置的副本数量与副本数量是否一致,如果副本数量少于设置的数量,则会将副本备份以达到设置的数量。这也就导致伪分布式的副本数量必须设置为1,因为副本默认为3,当HDFS发现副本数量设置为3,但是伪分布式下又只有一个节点,HDFS就会一直处于安全模式。也就无法执行操作。
正常情况下,重启HDFS后,等它检查完数据没有问题就会自动退出安全模式。
E.SecondaryNameNode:
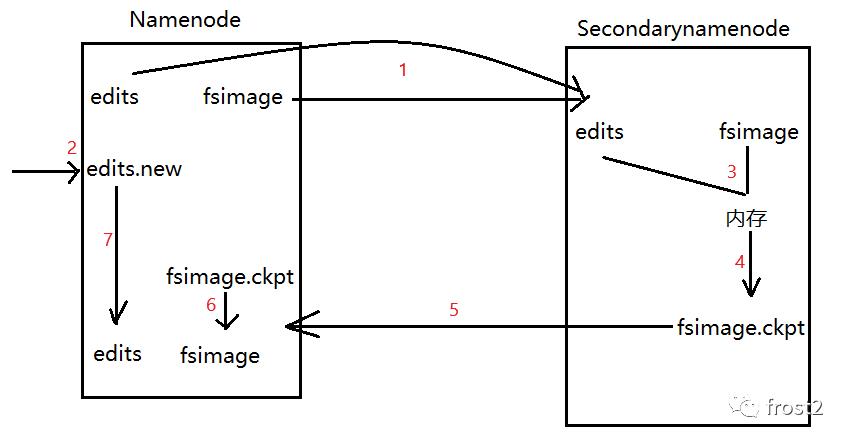
以上步骤讲述了NameNode的执行过程,但是还有一个细节没有说,就是edits文件是如何更新到fsimage中的。不卖关子直接告诉你这个更新操作是在SecondaryNameNode中进行的。
SecondaryNameNode流程如下:
将edits和fsimage文件通过网络拷贝到Secondarynamenode上。
在namenode产生一个edits.new记录合并期间执行的操作。
拷贝完成之后,会将fsimage和edits中的数据更到secondarynamenode的内存中。
更新完成之后,将内存中的数据写到fsimage.ckpt文件中。
通过网络将fsimage.ckpt拷贝到namenode中。
将fsimage.ckpt重命名为fsimage。
并且将edits.new也重命名为edits。
F.DataNode:
存储数据,并且是以数据块的形式来存储。
datanode存储namenode对应的clusterID以确定当前的datanode归哪一个namenode管理。
datanode每隔一段时间(3s)会主动向namenode发送心跳信息(节点状态,节点数据)。
如果namenode超过了10min没有收到datanode的心跳,则认为这datanode丢失(lost),那么namenode就会将这个datanode上的数据copy到其他节点上。
5、HDFS的操作流程
lient发送RPC请求给namenode。
namenode接收到请求之后,对请求进行验证,例如这个请求中的文件是否存在,再例如权限验证。
客户端在写完之后就会向namenode发送写完数据的信号,namenode会给客户端返回一个关闭文件的信号。
datanode之间将会通过管道进行自动的备份,保证复本数量。
Client发起RPC请求到namenode。
namenode收到请求之后,会将这个操作记录到edits中,然后将数据从内存中删掉,给客户端返回一个删除成功的信号。
客户端收到信号之后认为数据已经删除,实际上数据依然存在datanode上。
当datanode向namenode发送心跳消息(节点状态,节点数据)的时候,namenode就会检查这个datanode中的节点数据,发现datanode上的节点数据在namenode上的元数据中没有记录,namenode就会做出响应,命令对应的datanode删除指定的数据。
读操作:
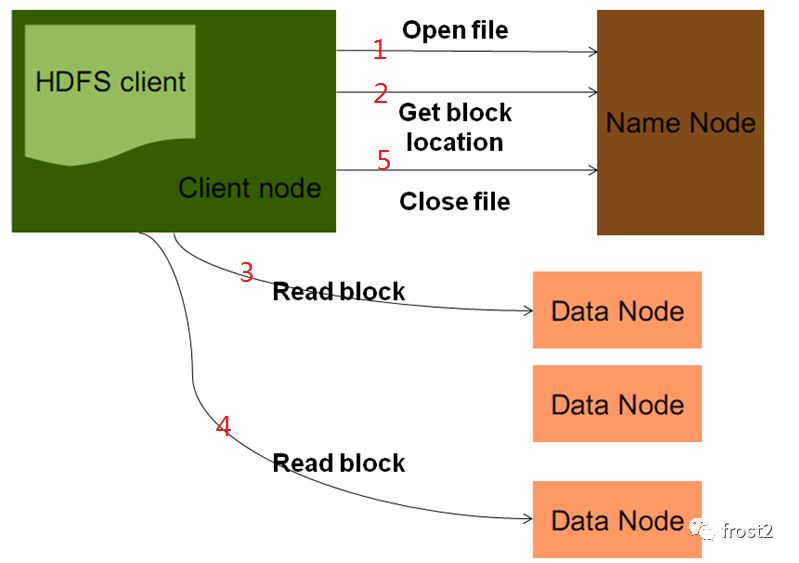
1.客户端发起RPC请求访问Namenode。
2.namenode会查询元数据,找到这个文件的存储位置对应的数据块的信息。
6.将Block读取之后,对Block进行checksum的验证,如果验证失败,说明数据块产生损坏,那么client会向namenode发送信息说明该节点上的数据块损坏,然后从其他节点中再次读取这个数据块。
8.当把文件全部读取完成之后,从client会向namenode发送一个读取完毕的信号,namenode就会关闭对应的文件。
写流程:
删除操作:
6、HDFS的基本命令
作者的话:
在电脑端浏览本文效果会更好,手机上格式会发生变动,我已经尽可能的调整,但有些地方还是不太美观,敬请谅解。
最后希望能帮助到大家,如果有问题请留言,或者直接给我发邮件,我的邮箱:1603153768@qq.com。
以上是关于Hadoop必知必会一的主要内容,如果未能解决你的问题,请参考以下文章