赵丽颖固然漂亮,可这份Hadoop核心教程也不差啊!
Posted 蓝桥云课精选
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了赵丽颖固然漂亮,可这份Hadoop核心教程也不差啊!相关的知识,希望对你有一定的参考价值。
阿里巴巴采用了 15 个节点组成的 Hadoop 集群,用于处理从数据库中导出的商业数据的排序和组合。
Ebay 使用了 32 个节点组成的集群,包括 8 * 532 个计算核心以及 5.3 PB 的存储。该公司大量使用了 Java 编写的 MapReduce 应用,以及 Pig 、 Hive 和 HBase 的组合应用以研究搜索优化。
Facebook 主要使用 Hadoop 来存储内部日志和结构化数据源的副本,并且将其作为数据报告、数据分析和机器学习的数据源。
什么是Hadoop?
Apache Hadoop 是一款支持数据密集型分布式应用并以 Apache 2.0 许可协议发布的开源软件框架。
Hadoop 框架透明地为应用提供可靠性和数据移动。它实现了名为 MapReduce 的编程范式:应用程序被分割成许多小部分,而每个部分都能在集群中的任意节点上执行或重新执行。
此外,Hadoop 还提供了分布式文件系统,用以存储所有计算节点的数据,这为整个集群带来了非常高的带宽。
核心概念
Hadoop 项目主要包含了以下四个模块:
1. Hadoop 通用模块(Hadoop Common): 为其他 Hadoop 模块提供支持的公共实用程序。
2. Hadoop 分布式文件系统(HDFS, Hadoop Distributed File System):提供对应用程序数据的高吞吐量访问的分布式文件系统。
3. Hadoop YARN: 任务调度和集群资源管理框架。
4. Hadoop MapReduce: 基于 YARN 的大规模数据集并行计算框架。
对于初次学习 Hadoop 的用户而言,应重点关注 HDFS 和 MapReduce。作为一个分布式计算框架,HDFS 承载了该框架对于数据的存储需求,而 MapReduce 满足了该框架对于数据的计算需求。
下图是 Hadoop 集群的基本架构:
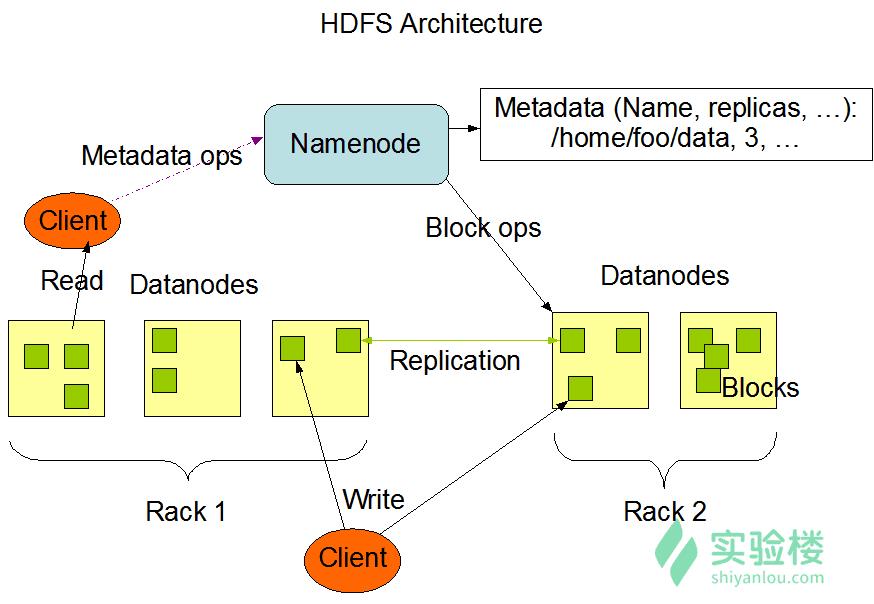
Hadoop 生态体系
如同 Facebook 在 Hadoop 的基础上衍生了 Hive 数据仓库一样,社区中还有大量与之相关的开源项目,下面列出了一些近期比较活跃的项目:
HBase:一个可伸缩的、支持大表的结构化数据存储的分布式数据库。
Hive:提供数据汇总和临时查询的数据仓库基础框架。
Pig:用于并行计算的高级数据流语言和执行框架。
ZooKeeper:适用于分布式应用的高性能协调服务。
Spark:一个快速通用的 Hadoop 数据计算引擎,具有简单和富有表达力的编程模型,支持数据 ETL(提取、转换和加载)、机器学习、流处理和图形计算等方面的应用。
值得特别关注的是,Spark 这一分布式内存计算框架就是脱胎于 Hadoop 体系的,它对 HDFS 、YARN 等组件有了良好的继承,同时也改进了 Hadoop 现存的一些不足。部分学习者可能会对 Hadoop 和 Spark 的使用场景重叠产生疑问,但学习 Hadoop 的工作模式和编程模型,将有利于加深对 Spark 框架的理解,这也是本系列课程首先学习 Hadoop 的原因。
部署 Hadoop
Hadoop 主要有以下三种部署模式:
单机模式:在单台计算机上以单个进程的模式运行。
伪分布式模式:在单台计算机上以多个进程的模式运行。该模式可以在单节点下模拟“多节点”的场景。
完全分布式模式:在多台计算机上分别以单个进程的模式运行。
具体的部署步骤以及详细的教程大家可以点击文末 阅读原文 进行学习,因为内容还是比较广泛和充实的:
实验1:Hadoop 简介与安装部署
挑战1:Hadoop 系统部署
实验2:HDFS 架构与操作
实验3:MapReduce 原理与实践
挑战2:使用 MapReduce 进行日志分析
实验4:YARN 架构
挑战3:用 Hadoop 计算圆周率
实验5:HBase 基础
挑战4:HBase 数据导入
实验6:Sqoop 数据迁移
挑战5:HBase 实现 Web 日志场景数据处理
实验7:Solr 基础实战
实验8:Hive 基础实战
挑战6:导入数据到 Hive
实验9:Flume 基础实战
实验10:Flume、HDFS 和 Hive 实现日志收集和分析
挑战7:用 Flume 和 MapReduce 进行日志分析
实验11:Kafka 基础实战
挑战8:按需部署 Kafka
实验12:使用 Flume 和 Kafka 实现实时日志收集
实验13:Pig 基础实战
只要是你有一定的计算机基础和 Java 基础,并且对 Hadoop 感兴趣,相信都是可以完整地学下来的,大家加油!
相关阅读
以上是关于赵丽颖固然漂亮,可这份Hadoop核心教程也不差啊!的主要内容,如果未能解决你的问题,请参考以下文章