数说(之四)·大话大数据技术之Hadoop(上)
Posted 数据工匠俱乐部
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数说(之四)·大话大数据技术之Hadoop(上)相关的知识,希望对你有一定的参考价值。
刚入行要低调,懂不懂?低调!
——电影《疯狂的石头》
小伙伴们,大家好!
过完国庆节,大家是不是还想继续给祖国母亲庆祝生日呢?
我:“谁说的?我就很爱工作,因为——”

又到了数说系列的环节,从本期开始进入大数据的技术环节。
说到技术,很多人觉得晦涩难懂,但是今天我们要说的是围绕技术的一些有关话题,技术细节本身并不多过多讨论。
一大数据的定义
关于什么是“大数据”,业界至今还没有一个统一的定义,但是其含义基本一致,例如:

研究机构Gartner给出了这样的定义:大数据是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
根据维基百科的定义:大数据是指无法在可承受的时间范围内用常规软件工具进行捕捉、管理和处理的数据集合。
二大数据的特征
2001年麦塔集团(META Group)分析师莱尼在一份报告中对大数据提出了“3D数据管理”的观点,即认为大数据将往高速、多样、海量3个方向发展,提出了3个特性:高速性(Velocity)、多样化(Variety)、规模化(Volume),统称3V。
在莱尼的理论基础上,国际数据公司(IDC)再加上了价值(Value)的维度,主要强调大数据的总体价值大,但价值密度低。于是,规模性(Volume)、多样性(Varity)、高速性(Velocity)和价值性(Value),合称大数据的“4V”, 4V也是广受认可的大数据特性。
后来阿姆斯特丹大学又提出了大数据体系架构框架的5V特征:在原有4V基础上增加了真实性(Veracity)特征,包括数据可信性、真伪性、来源和信誉、有效性和可审计性等特性。
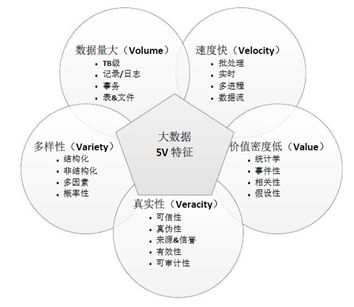
大数据5V特征,引自《大数据标准化白皮书》
三大数据的起源
一般来说,人们通常认为大数据起源于谷歌公司发表的三篇论文。
2003–The Google File System ——阐述如何存储大数据文件 2004–MapReduce:Simplified Data Processing on Large Clusters ——阐述如何处理大数据 2006–Bigtable:A Distributed Storage System for Structured Data ——阐述如何存储结构化的大数据 |
但大数据技术中最为人熟知的,还是Hadoop。这里,就不得不提到Doug Cutting(道格·卡丁),他先领导创立了Apache的项目Lucene,然后Lucene又衍生出子项目Nutch,Nutch又衍生了子项目Hadoop。Lucene是一个功能全面的文本搜索和查询库,Nutch目标就是要视图以Lucene为核心建立一个完整的搜索引擎,并且能达到提到Google商业搜索引擎的目标。Doug Cutting看到了谷歌的论文的价值并带领他的团队便实现了这个框架,并将Nutch移植上去,于是Nutch的可扩展性得到极大的提高。后来Doug Cutting逐渐认识到急需要成立一个专门的项目来充实这上述技术,于是就诞生了Hadoop。

四Hadoop生态圈的壮大
最初Hadoop还不是很出名,用一句流行的话说,就是“非常低调”。但是2008年时,Hadoop赢得1TB排序基准评估第一名,在那次活动上,除了Cutting所在的雅虎公司参加外,Facebook、Linkin和Twitter的人也都出席了,因此引起了这些大公司的注意,后来越来越多的大型互联网公司加入进来,形成了庞大的Hadoop生态圈。
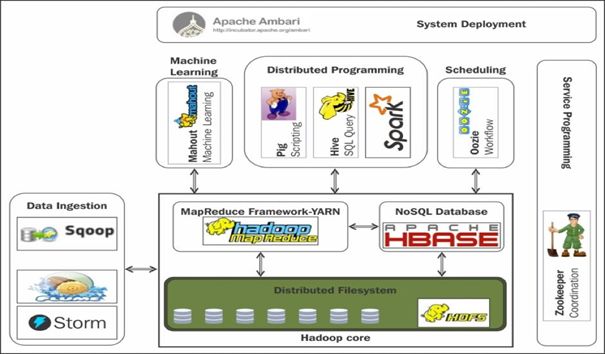
Hadoop初期的生态圈
有些小伙伴可能注意到了,接下来的这张图上的产品已经不完全是Apache软件基金会下的开源产品了。没错,随着Hadoop的影响力越来越大,很多传统软件厂商,如Oracle、SAP、IBM等,也加强了对Hadoop的支持。
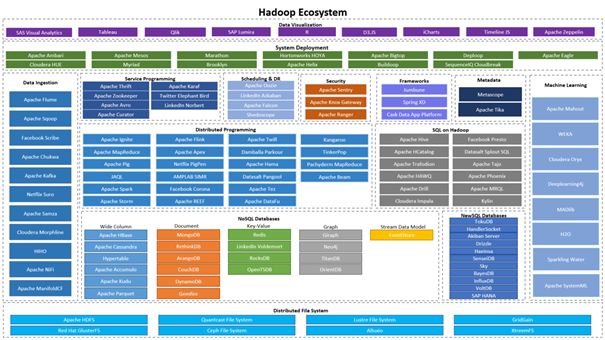
Hadoop最新的生态圈
五Hadoop的特点
让我们回到Hadoop产品本身, Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方面的特性:

Hadoop的核心组件
Hadoop1.X版本包括Hadoop Distributed File System(分布式文件系统,HDFS)和Hadoop MapReduce(分布式计算模型)两个最重要的核心组件,它们为Hadoop用户提供了系统底层细节透明的分布式基础架构。

Hadoop 2.X及以上版本有加入了YARN(Yet Another Resource Negotiator,另一种资源协调者),它是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
有了HDFS、MapReduce、YARN这三剑客的帮助,人们处理起巨大量的数据起来,犹如把大象塞进冰箱那么容易。
时间不早了,小编我又该敲(QU)代(BAN)码(ZHUAN)了,欲知Hadoop内部组件的工作原理,请期待《大话大数据技术之Hadoop》下集。

汪晋,某软件公司数据业务部项目总监,曾先后在联想集团、神华集团工作,长期从事数据仓库、智能分析和大数据项目的建设,熟悉能源行业(煤炭、电力、化工)和制造行业。
END
热门文章


微信:DaasCai
邮箱:ccjiu@163.com
QQ:174856958

我们的使命:发展数据治理行业、普及数据治理知识、改变企业数据管理现状、提高企业数据质量、推动企业走进大数据时代。
我们的愿景:打造数据治理专家、数据治理平台、数据治理生态圈。
我们的价值观:凝聚行业力量、打造数据治理全链条平台、改变数据治理生态圈。
了解更多精彩内容
数据工匠俱乐部
专注数据治理,推动大数据发展。
以上是关于数说(之四)·大话大数据技术之Hadoop(上)的主要内容,如果未能解决你的问题,请参考以下文章
大数据技术之_03_Hadoop学习_01_入门_大数据概论+从Hadoop框架讨论大数据生态+Hadoop运行环境搭建(开发重点)