小米Hadoop YARN平滑升级3.1实践
Posted 小米技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小米Hadoop YARN平滑升级3.1实践相关的知识,希望对你有一定的参考价值。
小米之前生产环境的Hadoop YARN是基于社区2.6版本修改的内部版本,我们最大规模集群已经数千台,而且还在不断增长。在目前2.6版本,我们主要面临两个问题:
-
滞后社区多个大版本, 很多新特性以及bug修复没法使用或者需要重新开发; -
集群规模增长很快,经历了多次机房迁移,当前版本不能很好地支持跨机房部署方案来实现作业透明迁移;
我们调研3.1过程中发现,基于YARN Federation(YARN-2915)的跨机房部署方案已经很成熟。同时,为了和社区保持同步,减少代码的维护成本。我们决定升级到Hadoop 3.1(注:在我们开始调研的时候3.2还没release)。
在升级到Hadoop 3.1之后,我们会基于YARN Federation这个特性来落地跨机房部署方案。同时,在3.1版本我们会和社区一起推进落地基于公有云的Auto Scaling方案。
小米Hadoop YARN在生产环境有数十个集群(包括国内和海外),服务于小米所有业务线,包含大量的批处理和流式计算作业(>10w/天)。本次升级到Hadoop 3.1希望能做到对业务透明,尽量减少对业务的影响:
-
升级期间,不需要停服; -
升级期间历史作业不失败; -
升级期间可以持续提交新作业; -
升级期间,作业日志能够正常查看;
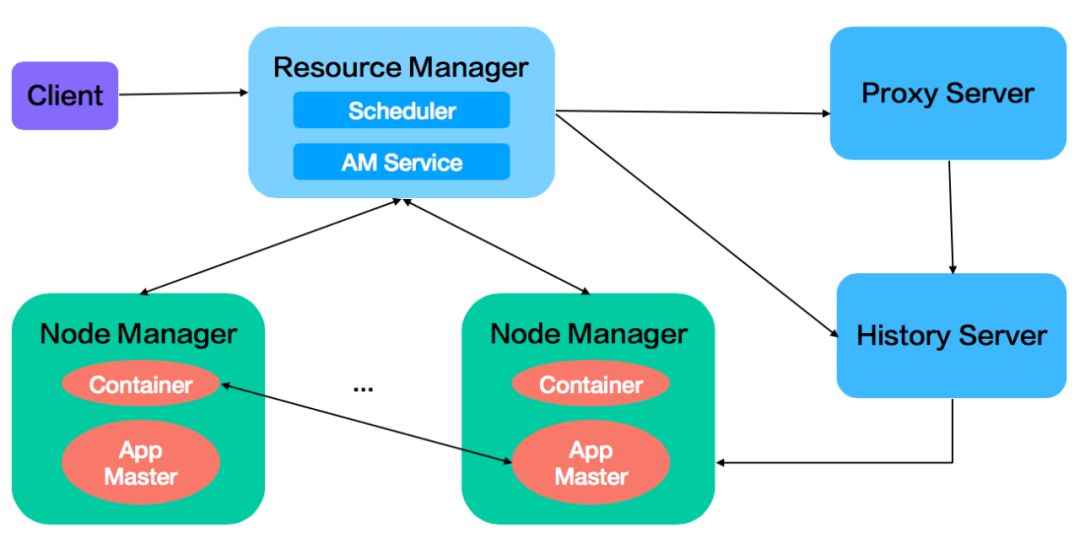
Hadoop YARN的架构组成包括ResourceManager(简写RM)、NodeManager(简写NM)、HistoryServer、ProxyServer等多个组件,这些组件之间需要进行RPC通信,如下图所示:
>>>>
patch合并/重构
patch合并/重构
-
稳定性优化,如基于ZK的client配置管理,实现了RM等服务的平滑迁移( YARN-9605 ),NM隔离优化( YARN-9977 ),HistoryServer稳定性优化( YARN-9973 )等; -
调度优化,如延时调度,缓存resource usage提升排序效率,事件处理优化( YARN-9979 )等; -
易用性优化,如支持MR作业查看实时jstack信息( YARN-10069 ),支持ui kill app,支持mysql的StateStore等; -
多集群管理和多租户管理,我们主要进行了资源管理服务产品化,提供统一的infra-client和web化的资源管理(支持计量计费等);
>>>>
兼容性/回归测试
兼容性/回归测试
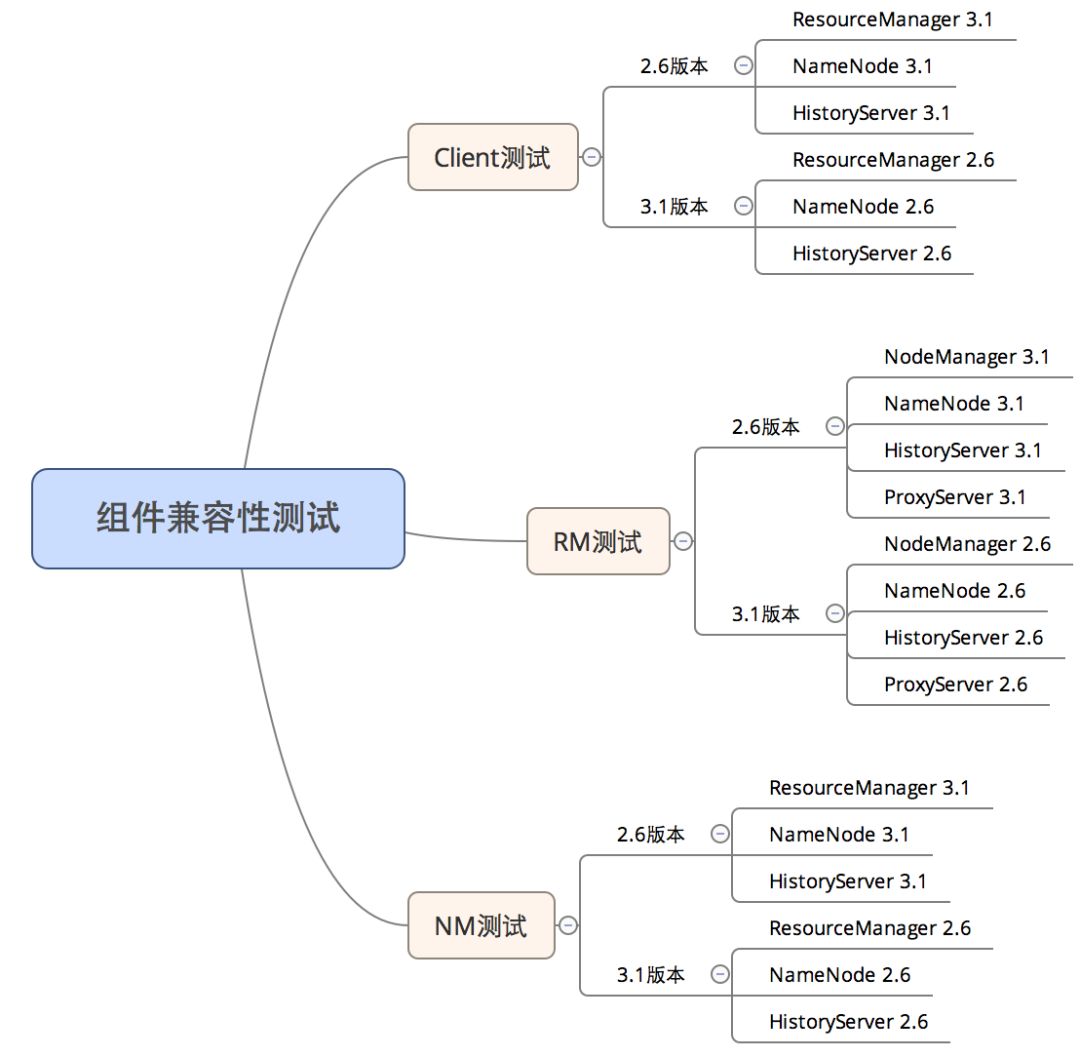
-
Hive 1.2; -
Hadoop MapReduce 2.6/3.1; -
Spark 1.6/2.1/2.3; -
Flink 1.8;
>>>>
调度器测试
调度器测试
-
线上生产集群的FairScheduler相关队列配置已经使用了很长一段时间,需要平滑切换到CapacityScheduler; -
我们的资源管理服务之前是针对FairScheduler设计的,需要对CapacityScheduler进行适配;
maximum-am-resource-percentuser-limit-factorintra-queue-preemption.disable_preemptiondisable_preemptionmaximum-capacity
>>>>
升级/回滚方案
升级/回滚方案
-
准备好回归测试作业(包括Hive/MR/Spark等),作业类型包含基本的TeraSort、WordCount以及一些用户的作业 -
升级资源管理服务 -
支持同时更新FairScheduler和CapacityScheduler的配置,当CapacityScheduler出现问题的时候可以直接回滚到FairScheduler -
升级控制节点(RM/HistoryServer/ProxyServer) -
RM主节点使用3.1版本的CapacityScheduler,备节点使用2.6版本的FairScheduler,当调度出现问题的时候,可以做主备切换进行恢复 -
基于回归测试作业进行验证,同时确认日志查看、主备跳转是否正常 -
升级Hadoop客户端配置和包 -
升级测试机器,验证回归测试作业是否正常运行 -
升级监控机器,验证监控作业是否正常运行 -
分批逐步升级作业调度机器,观察用户作业是否正常运行 -
升级Hive到兼容3.1的版本 -
部署一个兼容3.1版本的Hive实例,然后验证回归作业和线上部分历史作业 -
分批逐步升级其他Hive实例,观察用户查询是否正常运行 -
分批升级NM(注: 我们修改了2.6版本NM的recovery模块,支持直接从3.1回滚到2.6) -
我们会按照5%->25%->50%->75%->100%的灰度策略对NM进行操作 -
每步更新都会对回归测试作业进行验证
>>>>
NM回滚2.6版本异常
NM回滚2.6版本异常
2019-xx-xx,17:06:12,797 FATAL org.apache.hadoop.yarn.server.nodemanager.NodeManager: Error starting NodeManagerorg.apache.hadoop.service.ServiceStateException: java.io.IOException: Unexpected container state key:ContainerManager/containers/container_e36_1558337587778_0027_01_000002/starttime
>>>>
MR RPC协议修改导致作业执行异常
MR RPC协议修改导致作业执行异常
2019-xx-xx 16:49:49,306 WARN [main] org.apache.hadoop.mapred.YarnChild:Exception running child : org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.ipc.RPC$VersionMismatch):Protocol org.apache.hadoop.mapred.TaskUmbilicalProtocol version mismatch. (client = 19, server = 21)
>>>>
FileOutputCommitter版本改变导致数据丢失
FileOutputCommitter版本改变导致数据丢失
<name>mapreduce.fileoutputcommitter.algorithm.version</name><value>1</value>
public static final String FILEOUTPUTCOMMITTER_ALGORITHM_VERSION ="mapreduce.fileoutputcommitter.algorithm.version";public static final int FILEOUTPUTCOMMITTER_ALGORITHM_VERSION_DEFAULT = 1;
>>>>
日志配置文件不存在
日志配置文件不存在
log4j:ERROR setFile(null,true) call failed.java.io.FileNotFoundException: /home/work/hdd3/yarn/c4prc-preview/nodemanager/application_1559618566050_0070/container_e18_1559618566050_0070_01_000001 (Is a directory)
>>>>
容量调度器配置不对
容量调度器配置不对
2019-06-25,16:07:19,266 FATAL org.apache.hadoop.yarn.server.resourcemanager.ResourceManager: Error starting ResourceManagerjava.lang.IllegalArgumentException: Parent queue 'root.production' and child queue 'root.production.xiaoqiang_group' should use either percentage based capacityconfiguration or absolute resource together for label
-
落地Yarn Federation支持超大规模联邦集群,支持同城跨机房部署(>1w台); -
在海外落地基于公有云的Auto Scaling方案( YARN-9548 ),系统化地优化公有云集群成本; -
探索落地离在线混部的方案,打通在线/离线计算资源;
文末福利
评论区获赞数量最多的粉丝将获得小米90分双肩背包一个
以上是关于小米Hadoop YARN平滑升级3.1实践的主要内容,如果未能解决你的问题,请参考以下文章