书籍推荐:大数据全家桶:Hadoop,Spark,Strom,Druid实战,机器学习算法
Posted Java架构师联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了书籍推荐:大数据全家桶:Hadoop,Spark,Strom,Druid实战,机器学习算法相关的知识,希望对你有一定的参考价值。
前言
大家都知道学习大数据要学习很多的知识点,而往往大家在学的时候没有技术文档作为技术指导学习。
这不小编就应运而生,给大家整理了一套学习大数据需要学习的技术文档,包括的内容有点多,大致有下面几大块:Hadoop、Spark、Strom,Druid实战,离线和实时大数据开发实战,大数据算法,机器学习等,希望大家能够喜欢。
因为内容有点多,所以小编就把部分知识点拿出来做一个简单的介绍,每部分知识点都有更加细化的内容。
Hadoop大数据开发案例教程与项目实战
本篇共11章,分为基础篇和提高篇两部分。基础篇包括第1~6章,具体包括Hadoop概述、Hadoop基础环境配置、分布式存储HDFS、计算系统MapReduce、计算模型Yarn、数据云盘。提高篇包括第7~11章,具体包括协调系统Zookeeper、Hadoop 数据库、Hbase、Hadoop 数据仓库Hive、Hadoop 数据采集Flume、OTA离线数据分析平台。全篇内容结构合理,知识点全面,讲解详细,重点难点突出。

Spark大数据集群计算的生产实践
本篇涵盖了开发及维护生产级Spark应用的各种方法、组件与有用实践。全篇分为6章,第1~2章帮助读者深入理解Spark的内部机制以及它们在生产流程中的含义;第3章和第5章阐述了针对配置参数的法则和权衡方案,用来调优Spark,改善性能,获得高可用性和容错性;第4章专门讨论Spark应用中的安全问题;第6章则全面介绍生产流,以及把一个应用迁移到一个生产工作流中时所需要的各种组件,同时对Spark生态系统进行了梳理。

实时大数据分析基于Storm、Spark技术的实时应用
本篇详细阐述了实时大数据分析的实现过程,主要包括大数据技术前景及分析平台,Storm 的熟悉,用Storm处理数据,Trident 概述和Storm性能优化,Kinesis 的熟悉,Spark 的熟悉,使用RDD编程,Spark的SQL查询引擎,用Spark Streaming分析流数据以及Lambda架构等内容。此外,还提供了相应的示例、代码,以帮助读者进一步理解相关方案的实现过程。

Druid实时大数据分析-原理与实践
Druid作为一款开源的实时大数据分析软件,最近几年快速风靡全球互联网公司,特别是对于海量数据和实时性要求高的场景,包括广告数据分析、用户行为分析、数据统计分析、运维监控分析等,在腾讯、阿里、优酷、小米等公司都有大量成功应用的案例。本篇的目的就是帮助技术人员更好地深入理解Druid技术、大数据分析技术选型、Druid的安装和使用、高级特性的使用,也包括一些源代码的解析, 以及一些常见问题的快速回答。
Druid的生态系统正在不断扩大和成熟,Druid也正在解决越来越多的业务场景。希望能帮助技术人员做出更好的技术选型,深度了解Druid的功能和原理,更好地解决大数据分析问题。适合大数据分析的从业人员、IT人员、互联网从业者阅读。

大数据算法
大数据算法是大数据得以有效应用的基础,也是有志于从事大数据以及相关领域工作必须学习的课程。本篇由从事大数据研究的专家撰写,系统地介绍了大数据算法设计与分析的理论、方法和技术。本篇共分为10章,第1章概述大数据算法,第2章介绍时间亚线性算法,第3章介绍空间亚线性算法,第4章概述外存算法,第5章介绍大数据外存查找结构,第6章讲授外存图数据算法,第7章概述MapReduce算法,第8章通过一系列例子讲授MapReduce算法,第9章介绍超越MapReduce的算法设计方法,第10章讨论众包算法。


离线和实时大数据开发实战
内容分为三篇,共12章。
第一篇为数据大图和数据平台大图(第1章和第2章),主要站在全局的角度,基于数据、数据技术、数据相关从业者和角色、离线和实时数据平台架构等给出整体和大图形式的介绍。
第1章站在数据的全局角度,对数据流程以及流程中涉及的主要数据技术进行介绍,还介绍了主要的数据从业者角色和他们的日常工作内容,使读者有个感性的认识。
第2章是本书的纲领性章节, 站在数据平台的角度,对离线和实时数据平台架构以及相关的各项技术进行介绍。同时给出数据技术的整体骨架,后续的各章将基于此骨架,具体详述各项技术。
第二篇为离线数据开发:大数据开发的主战场(第3~7章),离线数据是目前整个数据开发的根本和基础,也是目前数据开发的主战场。这一部分详细介绍离线数据处理的各种技术。
第3章详细介绍离线 数据处理的技术基础Hadoo MapReduce和HDFS。本章主要从执行原理和过程方面介绍此项技术,是第4章和第5章的基础。
第4章详细介绍 Hive。Hive 是目前离线数据处理的主要工具和技术。本章主要介绍Hive的概念、原理、架构,并以执行图解的方式详细介绍其执行过程和机制。
第5章详细介绍Hive的优化技术,包括数据倾斜的概念、join无关的优化技巧、join相关的优化技巧,尤其是大表及其join操作可能的优化方案等。
第6章详细介绍数据的维度建模技术,包括维度建模的各种概念、维度表和事实表的设计以及大数据时代对维度建模的改良和优化等。
第7章主要以虚构的某 全国连锁零售超市FutureRetailer为例介绍逻辑数据仓库的构建,包括数据仓库的逻辑架构、分层、开发和命名规范等,还介绍了数据湖的新数据架构。
第三篇为实时数据开发:大数据开发的未来(第8~ 12章),主要介绍实时数据处理的各项技术,包括Storm、Spark Streaming、Flink、 Beam以及流计算SQL等。
第8章详细介绍分布式流计算最早流行的Storm技术,包括原生Storm以及衛生的Trident框架。
第9章主要介绍Spark生态的流数据处理解决方案SparkStreaming,包括其基本原理介绍、基本API、可靠性、性能调优、数据倾斜和反压机制等。
第10章主要介绍流计算技术新 贵Flink技术。Flink 兼顾数据处理的延迟与吞吐量,而且具有流计算框架应该具有的诸多数据特性,因此被广“泛认可为下一代的流式处理引擎。
第11章主要介绍Google力推的Beam技术。Beam的设计目标就是统一离线批处理和实时流处理的编程范式,Beam抽象出数据处理的通用处理范式BeamModel,是流计算技术的核心和精华。
第12章主要结合 Flink SQL和阿里云Stream SQL介绍流计算SQL,并以典型的几种实时开发场景为例进行实时数据开发实战。


机器学习算法大集结
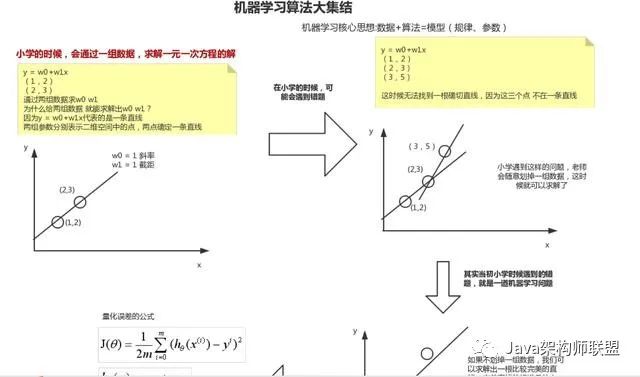
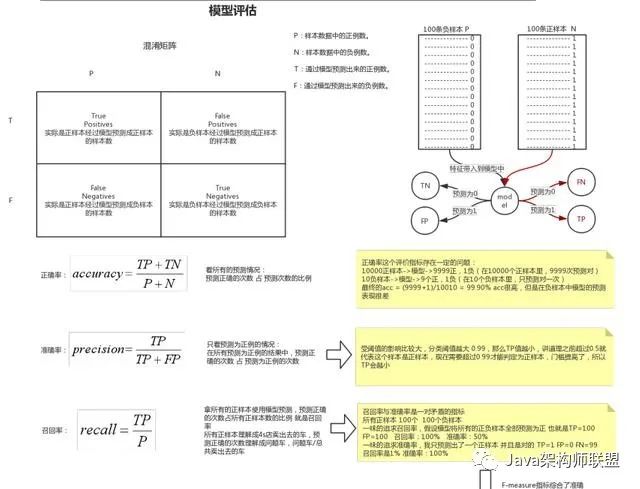
大数据全家桶:Hadoop,Spark,Strom,Druid实战,机器学习算法,离线和实时大数据开发实战,大数据算法,机器学习到此就已经整理完毕,希望大家能够喜欢。

大家如果需要这些大数据全家桶技术文档的话,可以私信小编“书籍”查看获取方式
以上是关于书籍推荐:大数据全家桶:Hadoop,Spark,Strom,Druid实战,机器学习算法的主要内容,如果未能解决你的问题,请参考以下文章
大数据最全的大数据Hadoop|Yarn|Spark|Flink|Hive技术书籍分享/下载链接,持续更新中...
下载基于大数据技术推荐系统实战教程(Spark ML Spark Streaming Kafka Hadoop Mahout Flume Sqoop Redis)
O'Reilly精品图书推荐:数据算法:Hadoop/Spark大数据处理技巧