hadoop-spark-zk集群安装
Posted 胡晨欢迷弟的自我修养
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop-spark-zk集群安装相关的知识,希望对你有一定的参考价值。
集群搭建
一、 centos7虚拟机的安装及配置
(1)、虚拟机创建
准备工具:VMvare 14.0pro,CentOS7iso文件
(典型)推荐 -> 安装光盘映像文件(找到要安装的CentOS7iso文件)->输入用户名和密码(个人设置,没啥影响)->选择虚拟机安装位置和名字->调整磁盘容量,选择存储为单个或者是多个文件(建议选择多文件,多文件可以减轻压力,单文件容易造成系统负载大。)->然后点击完成,具体设置可以等安装后一起设置
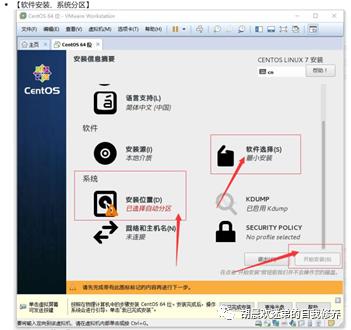
(2)、虚拟机配置
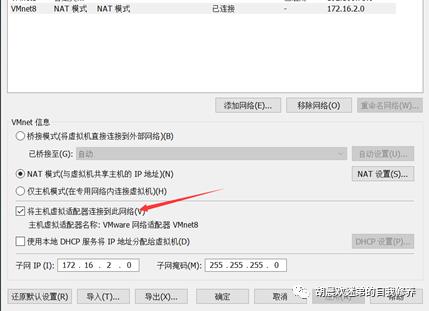
设置ip网段和网关,主机虚拟适配器要千万记得点,不点会无法连接外部网络。网关要设置为网段.2(虚拟机默认为.2)
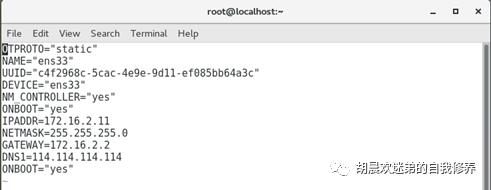
vim /etc/sysconfig/network-scripts/ifcfg-ens33
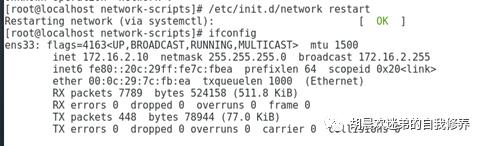
接着重启网卡查看配置结果
对其他两台机器做同样的配置,网络方面就配置好了,照着配置做基本就可以虚机联网了,如果没有连上可以先检查电脑本身是否联网了(我就被这个绊了一下,哈哈),如果已连接就看看之前的配置有没有问题。(切记切记,所有配置英文字母要全部大写)
(3)、互信配置
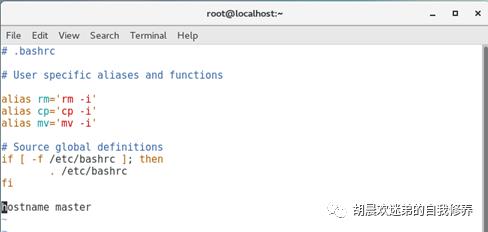
1、设置三台机器的hostname
Vim ~/.bashrc->加入hostname master->返回-> (个人感觉为刷新,重新加载~/.bashrc文件)bash ->hostname(查看命令查看主机名)
三台机器分别为master slave1slave2(名字自取,有区分度即可)
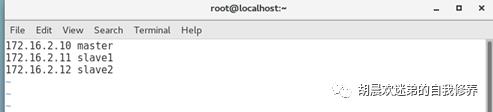
2、配置dns
Vim /etc/hosts
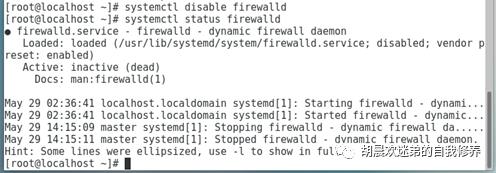
3、关闭防火墙
Systemctl stopfirewalld -> Systemctl disable firewalld -> Systemctl status firewalld
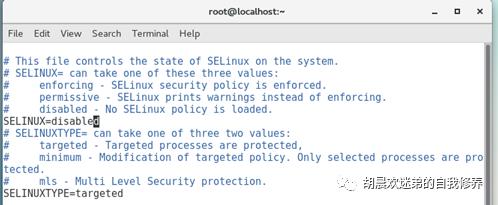
getenforce ->setenforce 0(暂时关闭)->vim /etc/selinux/config ,将selinux=enforcing改为disabled,保存之后重启。
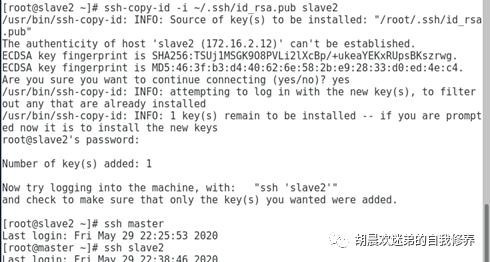
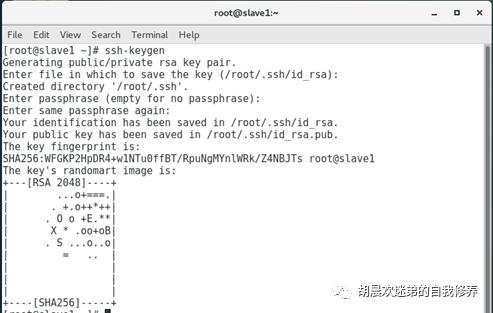
4、免密登陆
ssh-keygen ->ssh-copy-id -I ~/.ssh/id_rsa.pub master ssh-copy-id -I ~/.ssh/id_rsa.pub slave1 ssh-copy-id -I ~/.ssh/id_rsa.pub slave2 (三台机器都进行配置) ->互相ssh测试结果
二、 hadoop集群和Java jdk的安装
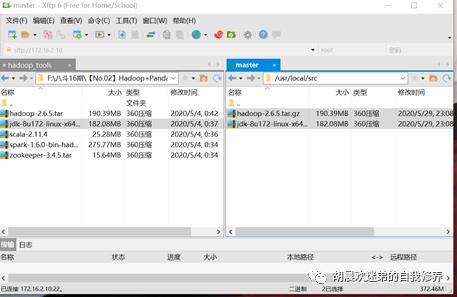
(1)、向集群上传并解压文件
我采用的是xftp方式上传,
tar -xzvf hadoop.tar.gz javajdk
(2)、系统环境变量的配置
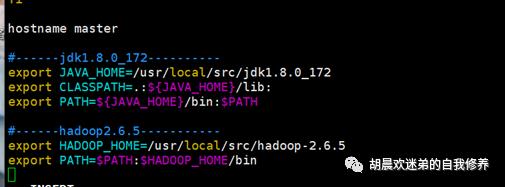
vim ~/.bashrc ->输入环境变量 (要记得三台都进行配置)
刷新环境变量 source ~/.bashrc->可以输入 java -version hadoop version 等命令去查看是否安装正确。
(3)、修改hadoop配置文件
1、修改 hadoop.env.sh文件
cd /usr/local/src/Hadoop-2.6.5/etc/Hadoop
vim hadoop.env.sh (对应路径即可)

2、修改yarn.env.sh文件
vim yarn.env.sh

3、修改slaves文件
这里要写和从节点对应的hostname
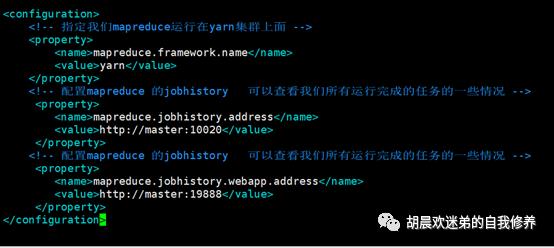
4、修改core-site.xml hdfs-site.xml mapred-site.xmlyarn-site.xml文件
vim core-site.xml

vim hdfs-site.xml

cp mapred-site.xml.templatevim mapred-site.xml
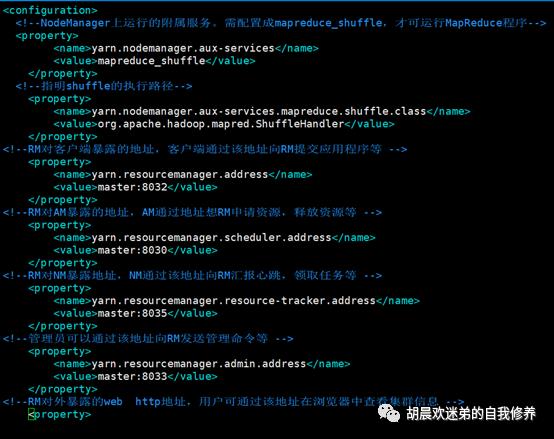
vim yarn-site.xml(以下图片不全)
5、创建配置中提到的文件

6、拷贝安装包
scp -r/usr/local/src/hadoop-2.6.5 root@slave1:/usr/local/src/hadoop-2.6.5
scp -r/usr/local/src/hadoop-2.6.5 root@slave2:/usr/local/src/hadoop-2.6.5
scp -r/usr/local/src/jdk1.8.0_172/ root@slave1:/usr/local/src/jdk1.8.0_172/
scp -r/usr/local/src/jdk1.8.0_172/ root@slave2:/usr/local/src/jdk1.8.0_172/

(4)、启动集群
hadoop namenode-format
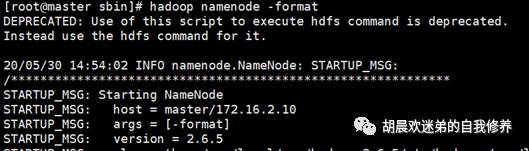
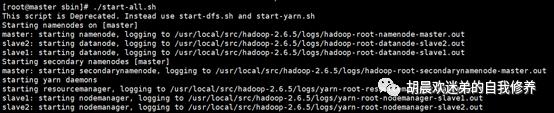
cd /usr/local/src/hadoop-2.6.5/sbin-> ./start-all.sh
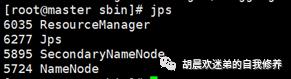
jps查看启动情况
三、 spark集群的安装配置
(1)、上传并解压文件

(2)、系统环境变量的配置
vim ~/.bashrc->source ~/.bashrc
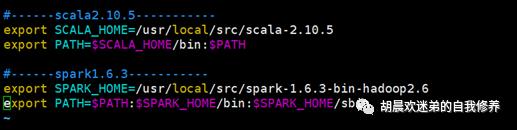
(3)、spark配置文件修改
cpspark-env.sh.template spark-env.sh vimspark-env.sh
cp slaves.templateslaves vim slaves

(4)、拷贝至从节点中
scp -r/usr/local/src/spark-1.6.3-bin-hadoop2.6 root@slave1:/usr/local/src/spark-1.6.3-bin-hadoop2.6
scp -r/usr/local/src/spark-1.6.3-bin-hadoop2.6 root@slave2:/usr/local/src/spark-1.6.3-bin-hadoop2.6
scp -r/usr/local/src/scala-2.10.5 root@slave2:/usr/local/src/scala-2.10.5
scp -r/usr/local/src/scala-2.10.5 root@slave1:/usr/local/src/scala-2.10.5
(5)、启动集群验证
多出一个sparksubmit进程,不清楚怎么回事,正在求证。尝试杀掉进程之后重启,无此进程。

没有跑任务验证,其实应该跑一下任务验证一下集群安装的正确性。
四、 zookeeper的安装配置
(1)、上传并解压文件

(2)、系统环境变量的配置

(3)、zookeeper的配置
1、创建日志文件夹和数据文件夹
mkdir data/ mkdir logs/

2、修改配置文件
cp zoo_sample.cfgzoo.cfg vim zoo.cfg
(4)、拷贝安装包
scp -r /usr/local/src/zookeeper-3.4.10root@slave1:/usr/local/src/zookeeper-3.4.10
scp -r /usr/local/src/zookeeper-3.4.10 root@slave2:/usr/local/src/zookeeper-3.4.10
(5)、分别添加ID
#Master
echo "1"> /usr/local/src/zookeeper-3.4.5/data/myid
#Slave1
echo "2"> /usr/local/src/zookeeper-3.4.5/data/myid
#Slave2
echo "3"> /usr/local/src/zookeeper-3.4.5/data/myid
(6)、启动集群验证
当挂掉leader时,节点间会通过3888端口选举leader。
以上是关于hadoop-spark-zk集群安装的主要内容,如果未能解决你的问题,请参考以下文章