如何选择满足需求的SQL on Hadoop/Spark系统
Posted 大数据文摘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何选择满足需求的SQL on Hadoop/Spark系统相关的知识,希望对你有一定的参考价值。
作者|梁堰波
感谢“明略数据”的投稿,只要是“干货”大数据文摘就愿意发表,也欢迎各位读者参与评论,点击文末右下角“写评论”即可。
在批处理时代,Hive一枝独秀;在实时交互式查询时代,呈现出的是百花齐放的局面。Hive onTez, Hive on Spark, Spark SQL, Impala等等,目前看也没有谁干掉谁的趋势。引用今年图灵奖得主Michael Stonebraker的话说,现在的数据库领域已经不是”one size fit all”的时代了。那么面对这么多系统,我们改如何选择呢?这里谈谈这些系统的区别和优缺点。
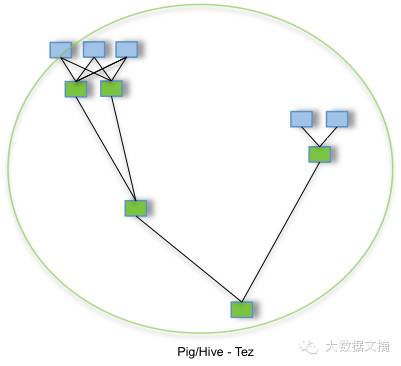
Hive/Tez/Stinger目前的主要推动者是hortonworks和Yahoo!。刚刚结束的2015 Hadoop Summit(San Jose)上,Yahoo分享了他们目前生产环境中Hive on Tez的一些情况。显示和Hive 0.10(RCFile)相比,目前的Hive on Tez在1TB的数据量查询的加速比平均为6.2倍。目前的Hive on Tez已经是production-ready。Tez是Apache开源的支持DAG作业的计算框架,它直接源于MapReduce框架,核心思想是将Map和Reduce两个操作进一步拆分,即Map被拆分成Input、Processor、Sort、Merge和Output, Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等,这样这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。如下图所示,将复杂的map reduce过程(图 pig/Hive MR), 转化成一个大作业形式(图 pig/Hive Tez)。除此之外还有一些进一步优化Hive执行效率的工作,例如Vectorized Execution和ORCFile等。Dropbox也透露他们的Hive集群下一步的升级目标就是Hive on Tez。
Hiveon Spark目前的主要推动者是Cloudera,可以认为是Hive社区这边搞的”Hive on Spark”。刚刚release了第一个使用版本,目前不能用于生产环境。Hive on Spark既能利用到现在广泛使用的Hive的前端,又能利用到广泛使用的Spark作为后端执行引擎。对于现在既部署了Hive,又部署了Spark的公司来说,节省了运维成本。
对于上面提到的Hive on Tez和Hive on Spark两种系统都具备的优点是:
1,现存的Hive jobs可以透明、无缝迁移到Hive on ***平台,可以利用Hive现有的ODBC/JDBC,metastore,hiveserver2, UDF,auditing, authorization, monitoring系统,不需要做任何更改和测试,迁移成本低。
2,无论后端执行引擎是MapReduce也好,Tez也好,Spark也好,整个HiveSQL解析、生成执行计划、执行计划优化的过程都是非常类似的。而且大部分公司都积累了一定的Hive运维和使用经验,那么对于bug调试、性能调优等环节会比较熟悉,降低了运维成本。
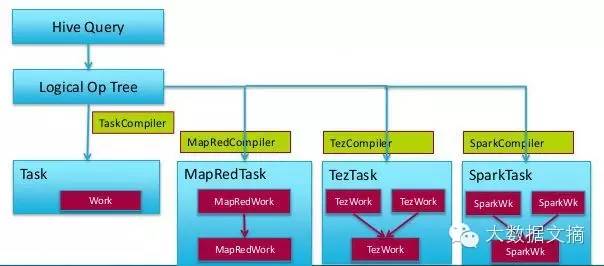
Spark SQL主要的推动者是Databricks。提到Spark SQL不得不提的就是Shark。Shark可以理解为Spark社区这边搞的一个”Hive on Spark”,把Hive的物理执行计划使用Spark计算引擎去执行。这里面会有一些问题,Hive社区那边没有把物理执行计划到执行引擎这个步骤抽象出公共API,所以Spark社区这边要自己维护一个Hive的分支,而且Hive的设计和发展不太会考虑到如何优化Spark的Job。但是前面提到的Hiveon Spark却是和Hive一起发布的,是由Hive社区控制的。
所以后来Spark社区就停止了Shark的开发转向Spark SQL(“坑了”一部分当时信任Shark的人)。SparkSQL是把SQL解析成RDD的transformation和action,而且通过catalyst可以自由、灵活的选择最优执行方案。对数据库有深入研究的人就会知道,SQL执行计划的优化是一个非常重要的环节,Spark SQL在这方面的优势非常明显,提供了一个非常灵活、可扩展的架构。但是SparkSQL是基于内存的,元数据放在内存里面,不适合作为数据仓库的一部分来使用。所以有了Spark SQL的HiveContext,就是兼容Hive的Spark SQL。它支持HiveQL, Hive Metastore, HiveSerDes and Hive UDFs以及JDBC driver。这样看起来很完美,但是实际上也有一些缺点:Spark SQL依赖于Hive的一个snapshot,所以它总是比Hive的发布晚一个版本,很多Hive新的feature和bug fix它就无法包括。而且目前看Spark社区在Spark的thriftserver方面的投入不是很大,所以感觉它不是特别想朝着这个方向发展。还有一个重要的缺点就是Spark SQL目前还不能通过分析SQL来预测这个查询需要多少资源从而申请对应的资源,所以在共享集群上无法高效地分配资源和调度任务。
特别是目前Spark社区把Spark SQL朝向DataFrame发展,目标是提供一个类似R或者Pandas的接口,把这个作为主要的发展方向。DataFrame这个功能使得Spark成为机器学习和数据科学领域不可或缺的一个组件,但是在数据仓库(ETL,交互式分析,BI查询)领域感觉已经不打算作为他们主要的发展目标了。
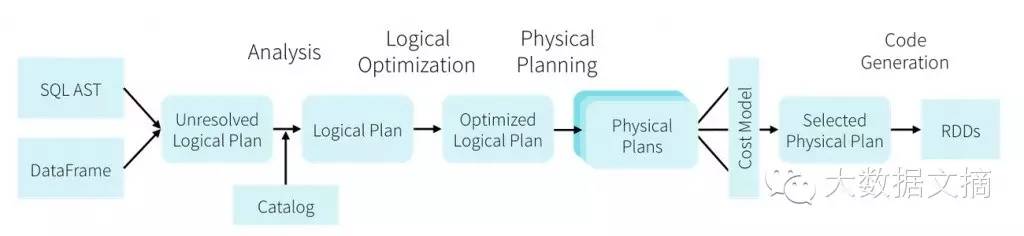
SparkSQL/DataFrame架构(
Impala主要的推动者是Cloudera,自从推出以来一直不温不火。Impala的系统架构如图所示。Impala表的元数据信息存储在Hive的Metastore中。StateStore是Impala的一个子服务,用来监控集群中各个节点的健康状况,提供节点注册,错误检测等功能。Impala在每个节点运行了一个后台服务impalad,impalad用来响应外部请求,并完成实际的查询处理。Impalad主要包含Query Planner,Query Coordinator和Query Exec Engine三个模块。QueryPalnner接收来自SQL APP和 ODBC的查询,然后将查询转换为许多子查询,Query Coordinator将这些子查询分发到各个节点上,由各个节点上的QueryExec Engine负责子查询的执行,最后返回子查询的结果,这些中间结果经过聚集之后最终返回给用户。
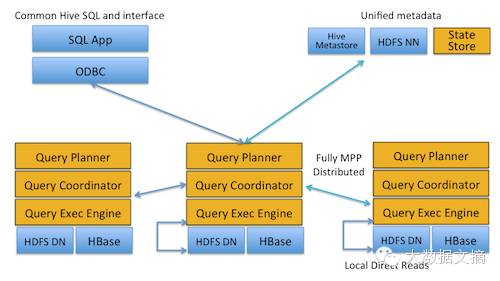
Impala是一种MPP架构的执行引擎,能够查询存储在Hadoop的HDFS和HBase中的PB级数据,查询速度非常快,是交互式BI查询最好的选择,即使是在并发性非常高的情况下也能保证查询延迟,所以在multi-tenant,shared clusters上表现比较好。Impala的另外一个重要的优点就是支持的SQL是在以上这些系统中是最标准的,也就是跟SQL99是最像的,所以对于传统企业来说可能是个不错的选择。Impala的主要缺点是社区不活跃,由C++开发,可维护性差,目前系统稳定性还有待提高。
Presto是Facebook开发的,目前也得到了Teradata的支持。目前Presto的主要使用者还是互联网公司,像Facebook,Netflix等。Presto的代码用了Dependency Injection, 比较难理解和debug。另外还有一些系统,像Apache Drill,Apache Tajo等,都是非常小众的系统了。
总的来说,目前来看Hive依然是批处理/ETL 类应用的首选。Hive on Spark能够降低Hive的延迟,但是还是达不到交互式BI查询的需求。目前交互式BI查询最好的选择是Impala。SparkSQL/DataFrame是Spark用户使用SQL或者DataFrame API构建Spark pipeline的一种选择,并不是一个通用的支持交互式查询的引擎,更多的会用在基于Spark的机器学习任务的数据处理和准备的环节。
作者简介:

大数据文摘精彩文章:
回复【金融】 看【金融与商业】专栏历史期刊文章
回复【可视化】感受技术与艺术的完美结合
回复【安全】 关于泄密、黑客、攻防的新鲜案例
回复【算法】 既涨知识又有趣的人和事
回复【谷歌】 看其在大数据领域的举措
回复【院士】 看众多院士如何讲大数据
回复【隐私】 看看在大数据时代还有多少隐私
回复【医疗】 查看医疗领域文章6篇
回复【征信】 大数据征信专题四篇
回复【大国】 “大数据国家档案”之美国等12国
回复【体育】 大数据在网球、NBA等应用案例
长按指纹,即可关注“大数据文摘”
专注大数据,每日有分享
覆盖千万读者的WeMedia联盟成员之一
以上是关于如何选择满足需求的SQL on Hadoop/Spark系统的主要内容,如果未能解决你的问题,请参考以下文章
SQL Partitioning,如何在分区组中选择满足一定条件的记录?