Spark PK Hadoop 谁是赢家?
Posted IT有得聊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark PK Hadoop 谁是赢家?相关的知识,希望对你有一定的参考价值。
数据已经从四面八方包围了我们的生活。随着每两年数据量增加一倍,数字宇宙正在快速追赶物理宇宙。据估计,到2020年,数字宇宙将达到44 ZB,与宇宙中的恒星一样多。
在确定这两个框架中的哪一个最适合您时,根据一些基本参数进行比较非常重要。
性能
Spark快如闪电,并且发现它的性能优于Hadoop框架。Spark在内存中的运行速度比Hadoop快100倍,在磁盘上的运行速度快 10倍。而且技术人员发现,使用10倍以下的机器,Spark对100 TB数据进行排序的用时只有Hadoop的三分之一。
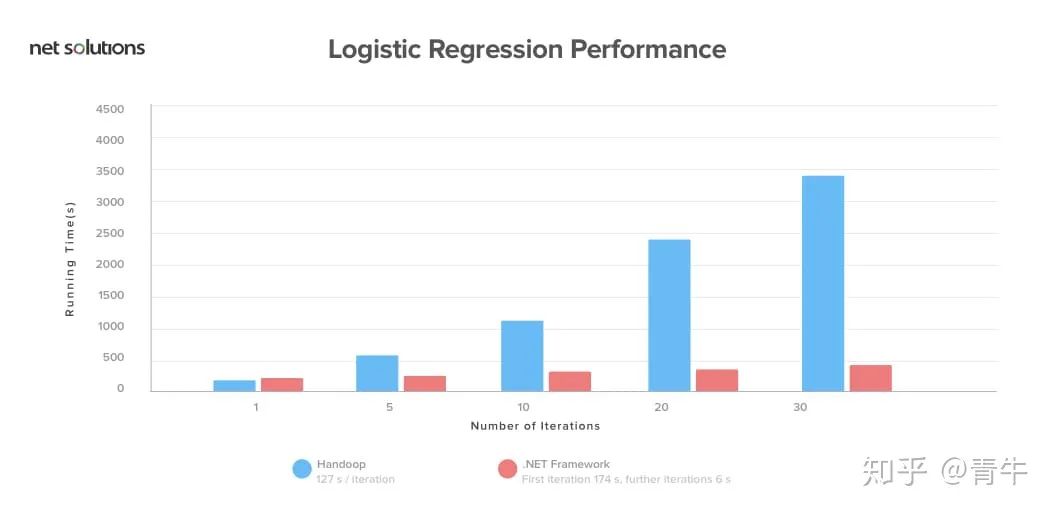
Spark之所以快,是因为它处理内存中的所有内容。得益于Spark的内存处理功能,它可以对来自营销活动,IoT传感器,机器学习和社交媒体站点的数据进行实时分析。
但是,如果Spark和其他共享服务一起在YARN上运行,其性能可能会下降。这可能会导致RAM开销内存泄漏。另一方面,Hadoop则可以轻松处理这类问题。如果用户倾向于批处理,则Hadoop比Spark效率更高。
底线:Hadoop和Spark都有不同的处理方式。因此,在Hadoop与Spark的性能之战中,是否继续使用Hadoop或Spark完全取决于项目的需求。
Facebook及其使用Spark框架的过渡之旅
Facebook上的数据每过一秒就会增加。为了处理这些数据并使用它做出明智的决定,Facebook使用了分析功能。为此,它利用了以下多个平台:
Hive平台执行Facebook的一些批处理分析。
用于自定义MapReduce实现的Corona平台。
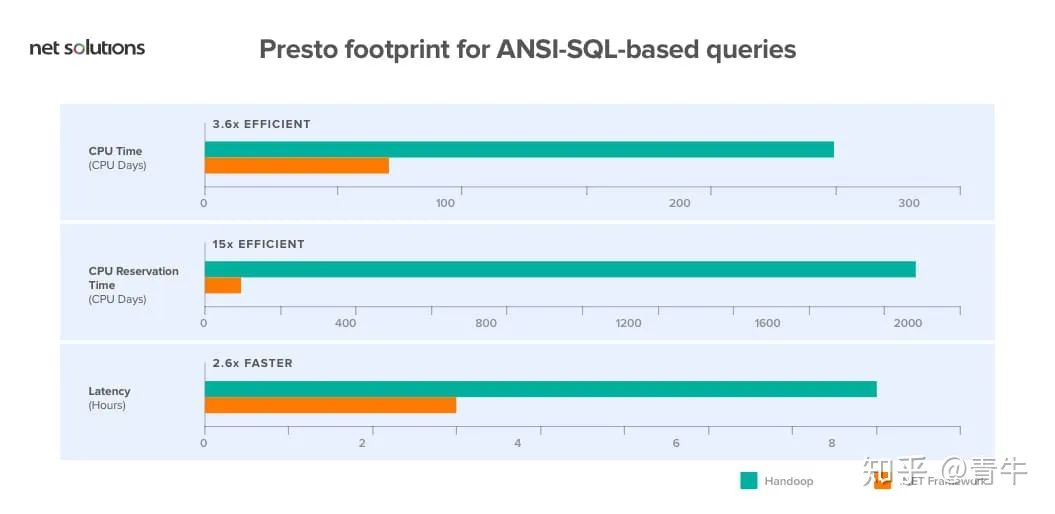
Presto足迹,用于基于ANSI-SQL的查询。
上面讨论的Hive平台在计算上是“资源密集型”的。因此,维护它是一个巨大的挑战。因此,Facebook决定改用Apache Spark框架来管理其数据。如今,Facebook通过集成Spark为实体实现了更快的数据处理。
安全
Spark的安全性仍有待提升,因为它目前仅支持通过共享机密进行身份验证(密码身份验证)。甚至Apache Spark的官方网站都声称:“存在许多不同类型的安全问题。Spark不一定能抵御一切。”
另一方面,Hadoop具有以下安全功能:Hadoop身份验证,Hadoop授权,Hadoop审核和Hadoop加密。所有这些都与Hadoop安全项目(如Knox Gateway和Sentry)集成在一起。
在Hadoop与Spark安全性之战中,Spark的安全性比Hadoop低。但是,在将Spark与Hadoop集成时,Spark可以使用Hadoop的安全功能。
成本
首先,Hadoop和Spark都是开源框架,因此是免费提供的。两者都使用商品服务器,在云上运行,并且对硬件的要求似乎有些相似:
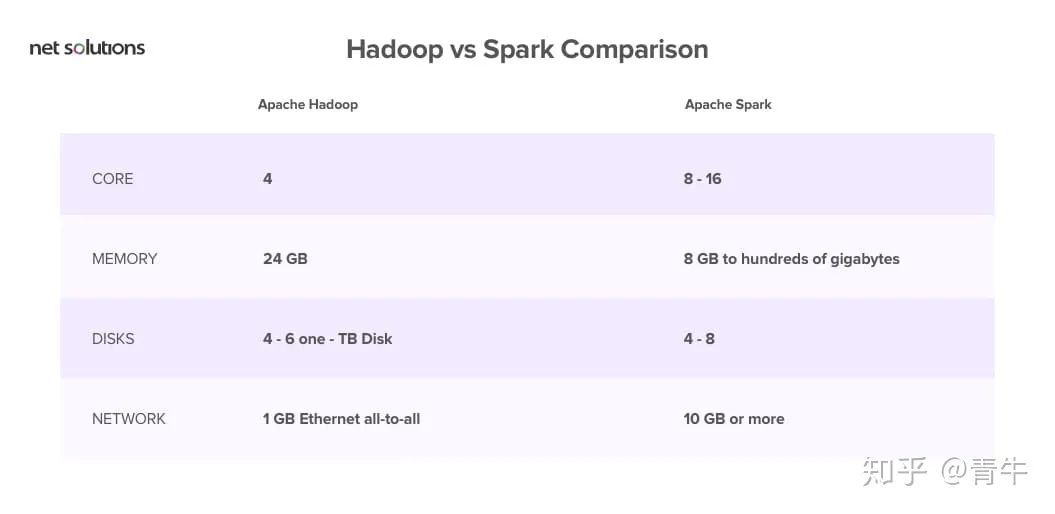
那么,如何根据成本进行评估呢?
请注意,Spark利用大量RAM来运行内存中的所有内容。考虑到RAM的价格比硬盘高,这可能会影响成本。
另一方面,Hadoop是磁盘绑定的。因此,节省了购买昂贵的RAM的成本。但是,Hadoop需要更多系统来分发磁盘I / O。
因此,在比较Spark和Hadoop框架的成本参数时,使用者将不得不考虑其需求。
如果需求倾向于处理大量的大历史数据,则Hadoop是首选,因为硬盘空间的价格要比内存空间便宜得多。
另一方面,当我们处理实时数据选项时,Spark可能具有成本效益,因为它使用较少的硬件以更快的速度执行相同的任务。
底线:在Hadoop与Spark的成本战中,Hadoop的成本肯定更低,但是当使用者必须处理少量实时数据时,Spark具有成本效益。
使用方便
Spark框架最大的优点之一是其易用性。Spark具有适用于Scala,Java,Python和Spark SQL用户的友好且舒适的API。
Spark的简单构建使编写用户定义的函数变得容易。此外,由于Spark允许批处理和机器学习,因此简化数据处理基础结构变得容易。它甚至包括一种交互式模式,用于运行具有即时反馈的命令。
Hadoop是用Java编写的,在没有交互模式的情况下编写程序有困难。尽管Pig(附加工具)使编程更容易,但它需要一些时间来学习语法。
底线:在Hadoop与Spark的“易用性”之战中,两者都有自己的使用户友好的方法。但是,如果我们必须选择一个,Spark更容易编程,并且包含交互模式。
Apache Hadoop和Spark是否可能具有协同关系?
是的,这很有可能,我们建议您这样做。让我们详细了解它们如何协同工作。
Apache Hadoop生态系统包括HDFS,Apache Query和HIVE。让我们看看Apache Spark如何利用它们。
Apache Spark和HDFS的合并
Apache Spark的目的是处理数据。但是,为了处理数据,引擎需要从存储中输入数据。为此,Spark使用HDFS。(这不是唯一的选择,而是最受欢迎的选择,因为Apache是两者背后的大脑)。
Apache Hive和Apache Spark的融合
Apache Spark和Apache Hive具有高度的兼容性,因为它们可以一起解决许多业务问题。
例如,假设一家企业正在分析消费者行为。现在,该公司将需要从各种来源收集数据,例如社交媒体,评论,点击流数据,客户移动应用程序等等。
该组织可以利用HDFS来存储数据,并使用Apache配置单元作为HDFS和Spark之间的桥梁。
为了处理消费者数据,大多数公司使用Spark和Hadoop的组合。
Q:Hadoop与Spark:赢家是……
A:尽管Spark快速且易于使用,但Hadoop具有强大的安全性,庞大的存储容量和低成本的批处理功能。从两个中选择一个完全取决于您的项目要求。两者的结合将产生更优的效果。
-End-
以上内容转载自:海牛大数据

那么,关于Spark学习中的痛点、难点和实战解析想了解更多么?

开放时间:2020年8月6日(周四)20:00
主讲老师:文艾(艾叔)
课程类型:视频直播
进入直播间路径:
路径一:识别下方二维码可进入九州云播平台直播间:

路径二:识别下方二维码可进入京东旗舰店直播间:

路径三:识别下方二维码可进入天猫云聚算图书专营店直播间:

路径四:识别下方二维码进入机械工业出版社腾讯直播间:

路径五:识别下方二维码可进入机械工业出版社百度百家号直播间:
微信扫描下方二维码,添加小编微信,发送“Spark”给小编(注意,一定要发送“Spark”),加入直播交流群。
入群有福利:
☆直播期间,入群读者的提问,专家会在直播间内优先解答。
☆直播结束后,本次分享的课件会分享到群中。
☆可获取更多优质课程分享
以上是关于Spark PK Hadoop 谁是赢家?的主要内容,如果未能解决你的问题,请参考以下文章