学习笔记 | Apache Hadoop Ozone 浅析
Posted 道比伯尔DaoBBoy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习笔记 | Apache Hadoop Ozone 浅析相关的知识,希望对你有一定的参考价值。
元数据的扩展性:NameNode是一个中央元数据服务节点,也是集群管理节点,文件系统的元数据以及块位置关系全部在内存中。NameNode对内存的要求非常高,需要定制大内存的机器,内存大小也限制了集群扩展性。京东的NameNode采用内存512GB的机器,字节跳动的NameNode采用内存1TB的机器。此外,NameNode的堆分配巨大,京东的NameNode需要360GB的堆大小,对GC的要求比较高,京东定制化的JDK11+G1GC在GC时性能良好,但是一般规模的公司不具备维护JDK能力,该方案不具备普遍性。字节跳动把NameNode修改成C++版本,这样分配、释放内存都由程序控制,也达到了不错的性能,该方案仍然不具普遍性,因为开发和维护C++版本的NameNode也需要不小规模的团队。
GC是垃圾收集的意思(Gabage Collection), 内存处理是编程人员容易出现问题的地方,忘记或者错误的内存回收会导致程序或系统的不稳定甚至崩溃
块汇报风暴:HDFS块大小默认128M,启动几百PB数据量的集群时,NameNode需要接受所有块汇报才可以退出安全模式,因此启动时间会达数小时。当集群全量块汇报、下线节点、balance集群存储,也会对集群元数据服务的性能造成影响,这些根本原因都是DataNode需要把所有块汇报给NameNode。
全局锁:NameNode有一把FSNamesystem全局锁,每个元数据请求时都会加这把锁。虽然是读写分开的,且有部分流程对该锁的持有范围进行了优化,但依然大问题。同时FSNamesystem内部的FSDirectory(Inode树)还存在一把单独的锁,用来保护整棵树以及BlockMap的访问和修改。
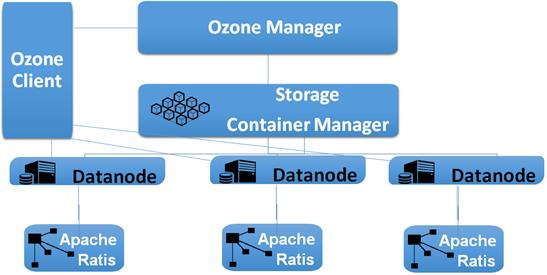
HDFS的三个局限,Ozone采用如下方式解决:
Ozone把Namespace元数据服务和Block Manager拆分为两个服务。OzoneManager负责元数据服务;StorageContainerManager负责数据块管理、节点管理、副本冗余管理。两个服务可以部署在两台机器,各自利用机器资源。Ozone的元数据不像NameNode存储在内存中,不管是OzoneManager的元数据,还是StorageContainerManager中的Container信息都维护在RocksDB中,极大降低对内存的依赖,理论上元数据可以无限扩展。
StorageContainerManager无须管理默认128MB的Block,只需管理默认5GB的Container。极大地减少了StorageContainerManager管理的数据量,从而提升StorageContainerManager的服务性能。因为StorageContainerManager是以Container作为汇报单位,汇报数量比HDFS大大减少。无论是全量块汇报,增删副本,balancer集群存储,都不会给StorageContainerManager性能造成很大影响。
OzoneManager内部的锁是Bucket级别,可以达到Bucket级的写并发。Ozone是对象存储,对象语义的操作,不存在目录和树的关系,因此不需要维护文件系统树,可以达到高吞吐量。
Raft协议中会有3个角色身份:Leader,Follower和Candidate。Split Vote投票过程会在Candidate中选出Leader和Follower的身份,Follower可以变成Candidate竞选Leader。
Raft协议本质上是通过本地的RaftLog和在Leader与Follower之间同步状态来保证数据的一致性,同时StateMachine会记录集群的状态。RaftLog使用了write ahead log (WAL) 的理念,Leader将过程记录在Log里面,同时日志的更新内容会同步到Follower上,然后日志会apply log到StateMachine中记录状态,当有足够的Quorum宣布成功,整体操作就成功了。这样能保证集群所有节点的状态机变化是相对同步的,同时RaftLog会在节点重启时做replay回放操作,重新建立起重启前的StateMachine状态,让节点恢复到与重启前相对同步的状态。
Pipeline和Container分配写入数据跟数据的副本数有关,Ozone现在主要支持三副本的方式,数据Pipeline创建时会关联三个数据节点,然后相关的Container会在这三个数据节点上分配Block来完成写入空间分配,三个数据节点会分别记住Pipeline和Container信息,异步发送Report到SCM上报Pipeline和Container的状态。三副本的数据Pipeline是通过Raft协议保证多副本一致性,在Ozone中也叫Ratis Pipeline,相关的三个数据节点会根据Raft协议组成一个Leader和2个Follower的组合,数据写入时会利用RaftLog把数据从leader发到Followers。所以Ozone的数据写入的性能依赖RaftLog的写入吞吐量和传输速度。
Ozone的数据节点写入磁盘的部分,一定程度上延续了HDFS单节点写入的方式,同时也保留了一些可待优化的部分。例如比起单纯在数据节点上做IO栈层面的优化,可以利用数据Pipeline的节点复用和RaftLog的特点,加大了数据节点对于并发写入数据的参与度,这样通过元数据和管理成本的修改增大写入带宽的方式。
目前Apache Hadoop Ozone在企业服务中的商用案例并不多,随着社区的热度兴趣和各大厂牌对其进行优化探索和内部验证,在今后的道路上或许值得我们期待。
以上是关于学习笔记 | Apache Hadoop Ozone 浅析的主要内容,如果未能解决你的问题,请参考以下文章