003-Ambari一键自动化脚本部署
Posted BearData
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了003-Ambari一键自动化脚本部署相关的知识,希望对你有一定的参考价值。
根据前两篇 “Ambari大数据平台搭建利器(一)&(二)”, 我们已经完成大数据平台的搭建,但是我们发现安装Ambari的步骤比较繁琐,并且手动部署存在以下的劣势:
1. 每个节点都要执行重复的命令,我们前两篇测试的节点只有三个,如果生产环境有上百个节点,这个工作量是比较大的。
2. 如果是基于项目的平台,可能会有几十甚至上百个客户,给每个与客户安装一套数十个节点的平台是比较繁琐的事。
3. 如果我们修改了源代码,在测试环境中,很有可能要来回卸载,安装,会花费很长的时间。
4. 人工操作会有一定的风险。
基于上述,我们打算写一套脚本,主要是安装Ambari server和agent,以及前期的环境检查,准备,修复,卸载。
注:如果只是个人测试学习,或者基于云端部署一套大数据平台,可以手动操作,这种场景是一次性的操作,并且之后很少再重新部署。
本篇主要是基于前两篇的基础上做的,因此需要对前两篇内容需要了解一下。
整体流程
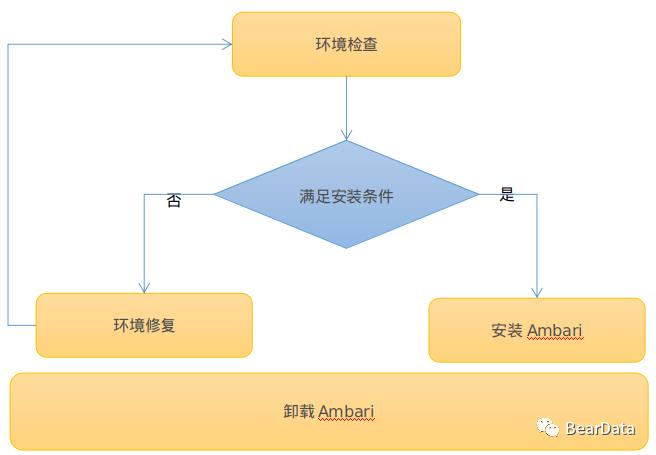
环境检查:检查服务安装的每个节点是否满足安装Ambari的条件,如JDK,OpenSSL,Ambari Server需要检查PostgreSQL等等。
环境修复:如果某些节点或者所有节点不满足安装条件,则需要通过修复来满足安装条件,如JDK没有安装,则需要安装JDK,并且设置环境变量。
安装Ambari:如果条件满足,则在指定的节点安装Ambari Server以及在每个节点安装Ambari agent。
卸载Ambari:卸载Ambari Server及Ambari agent。
技术选型
编程语言:Python
由于要在每个节点执行相同的命令(Server和Agent有区别),所以要选一种封装了SSH的库,我们选择Python中的Fabric。
脚本是运行在安装Ambari Server的节点上的,为了不影响原系统中的Python,我们需要在脚本中搭建Python虚拟环境。
技术实现
配置文件
配置文件主要配置了程序中需要读取的静态属性。
#配置安装agent的节点IP和主机名
#节点IP=主机名
[node_host]
192.168.163.130 = bigdata001
#域名配置后缀
#suffix = 域名后缀
[domain_name]
suffix = bdp.com
#操作用户名密码
[host_certification]:
host_user = root
host_password = root
# Ambari Server 安装主机IP
[server_host]
server_ip = 192.168.163.130
# 配置安装时的语言
[language]
language = zh_CN
#language = en_US
#配置ntp时间同步server,如果没有配置该项,并且在外网连通的情况下会读取网络时间
[ntp]
#ntp_server = 192.168.163.130
#源相关配置
[resource_path]
#Ambar大版本号
main_version = 2.6.2.0
#Ambari小版本号
min_version = 155
#yum源地址
yum_host_ip = 192.168.70.52
#Ambari源的文件夹
HDP = ambari,HDP,HDP-UTILS
#JDK 安装路径
[java_home]
java_home = /opt/jdk1.8.0_111
#Python虚拟环境路径
[python_virtual_path]
py_path = ~/py_virtual
#环境修复,虚拟环境所依赖的软件包
[software_package]
jdk = jdk-8u102-linux-x64.tar.gz
openssl = openssl-1.1.0a.tar.gz
postgresql = postgresql-9.2.15.tar.gz
httpd = httpd-2.2.31.tar.gz
python = Python-2.7.5.tgz
ruby = ruby-2.0.0.tar.gz
ntp = ntp-service-centos7.tar.gz
setuptools = setuptools-36.0.0.tar.gz
ecdsa = ecdsa-0.13.tar.gz
pycrypto = pycrypto-2.6.1.tar.gz
paramiko = paramiko-1.17.2.tar.gz
#卸载时所删除的包,目录,用户等信息
[remove]
remove_package = hadoop_2*,hdp-select*,ranger*,zookeeper*,bigtop*,atlas-metadata*,ambari-agent,postgresql*,spark*,smartsense-hst,ambari-metrics*,ambari-infra*,ambari-logsearch*,opentsdb*,redis*,hbase*,tez*,hive*,pig*,sqoop*,storm*,flume*,kafka*,zeppelin*,mahout*,slider*,cassandra*,phoenix*,extjs*,knox*,oozie*,accumulo*,elasticsearch_*,mysql_*,mycat_*,keepalived_*,haproxy_*,logstash_*,kibana_*,solr_*,rstudio-server_*,ceph*,kylin_*,greenplum_*
remove_user = ambari-qa,ams,falcon,flume,hbase,hcat,hdfs,hive,kafka,livy,mahout,mapred,oozie,opentsdb,redis,spark,sqoop,tez,yarn,zeppelin,zookeeper,cassandra,infra-solr,storm,livy,logsearch,knox,atlas,kms,ranger,accumulo,elasticsearch,mysqldb,mycat,keepalived,haproxy,logstash,kibana,solr,rstudio-server,ceph,kylin,gpadmin
remove_dir = /etc/,/var/lib/,/tmp/,/usr/lib/,/var/log/,/var/run/,/var/tmp/,/usr/bin/,/tmp/,/var/,/opt/,/data/
remove_file=ambari*,ams*,falcon*,flume*,hadoop*,hbase*,hive*,kafka*,oozie*,opentsdb*,postgresql,spark*,sqoop*,zeppelin,zookeeper*,storm*,smartsense,hadoop*,phoenix*,redis,slider,tez*,pig*,pgsql,cassandra,webhcat,mahout,hcat,accumulo*,hdfs*,mapred*,ranger*,slider*,atlas*,yarn*,worker-lanucher,beeline,logsearch*,knox*,ranger*,elasticsearch,mysqldb,mycat,keepalived,haproxy,logstash,kibana,solr,service_solr,rstudio-server,ceph,kylin,greenplum
spec_dir = /usr/hdp,/hadoop,/kafka*,/usr/share/HDP-oozie,/var/local/osd*,/etc/systemd/system/multi-user.target.wants/ceph-osd@*.service以上就是配置文件内容及说明。
Python虚拟环境
思路很简单,其实现就是将系统中的Python重新拷贝一份到指定目录下,然后将Fabric及依赖包进行安装,每次运行时都会去检查配置的虚拟环境路径是否存在,如果存在则直接使用,不存在则创建虚拟环境。
环境检查
我们在该脚本中环境检查项主要包括:JDK,Python,OpenSSL,Httpd,最大文件数,NTP,防火墙,SELinux,SSH,主机名,HOSTS文件,PGSQL,PackageKit。每项检查失败都有对应的修复。
我们以检查防火墙是否关闭为例,来说明环境检查的过程。
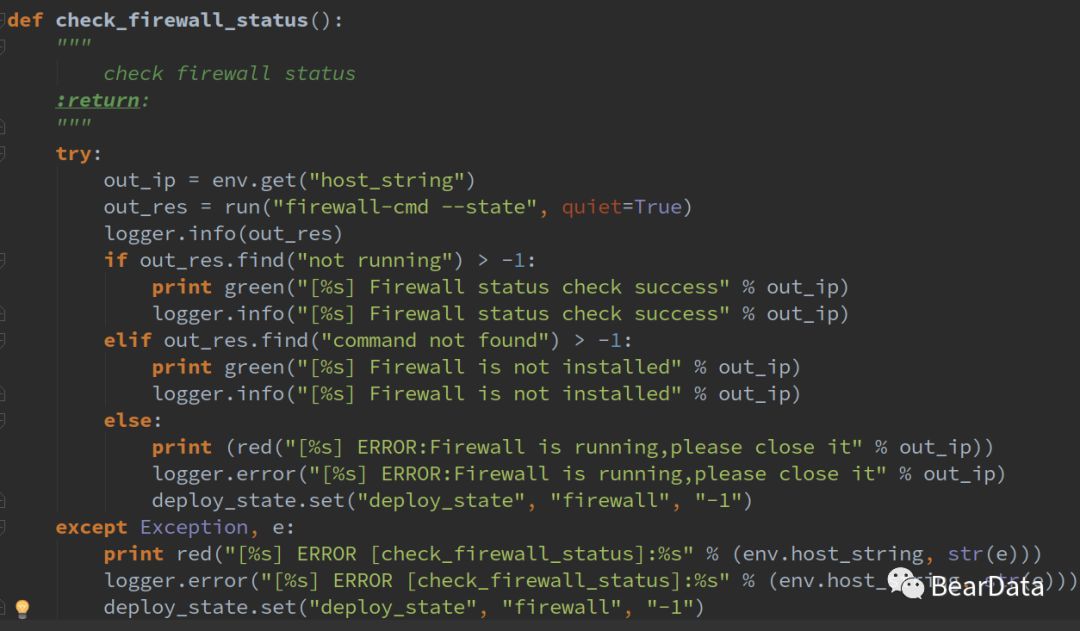
check_firewall_status()方法是整个检查的核心部分。
1. 在每个节点执行检查防火墙状态的命令:firewall-cmd status (不同的操作系统,检查的命令略微有区别)
2. 判断返回的内容,如果是 "not running" 则表示防火墙已处于关闭的状态。如果返回值为 “command not found” 则表示未安装防火墙指令(一般这种情况比较少,因为系统默认会有安装)。
3. 如果2中的条件都没有满足,则防火墙就处于 running 状态,将该信息写入到临时文件中,在后续修复环境时需要读取改文件。
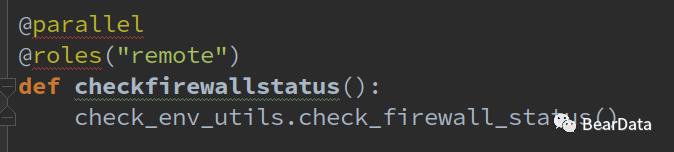
checkfirewallstatus()方法是利用Fabric的特性,在指定节点执行该方法。
@parallel :表示并行执行
@Roles("remote") : 表示在指定的角色上执行该方法,其中remote我们配置的所有机器的IP。
上述方法就表示在remote角色中配置的节点上并行执行该方法。
环境修复
我们还是接上面的关闭防火墙来说明环境修复的过程

首先判断firewall是否在临时文件中,如果存在则执行修复方法。
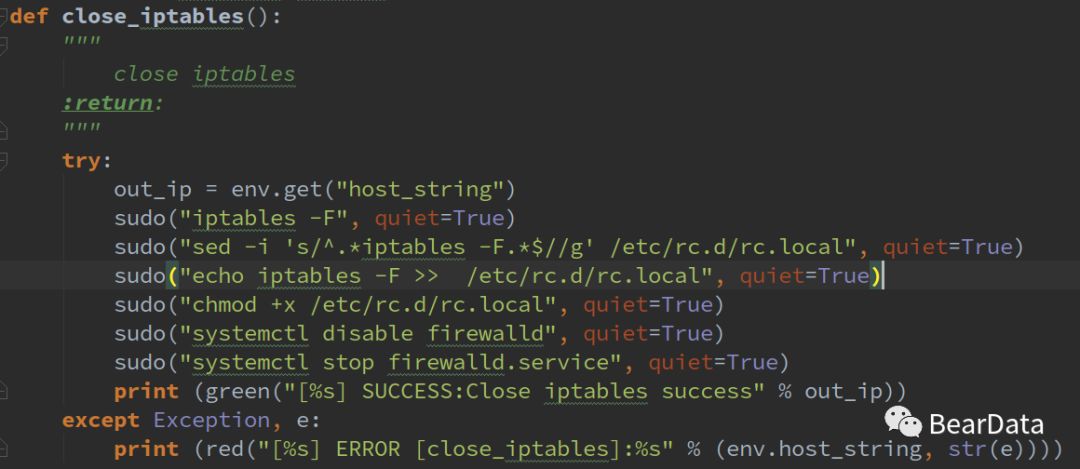
修复的过程也就是执行关闭防火墙的过程。
删除Ambari 及安装组件
删除的场景
1. 彻底删除Ambari及全部组件
2. 安装失败,某些节点安装失败,这时候需要删除安装失败的,保留安装成功的,我们在这称为回滚(roll-back)
删除Ambari Server
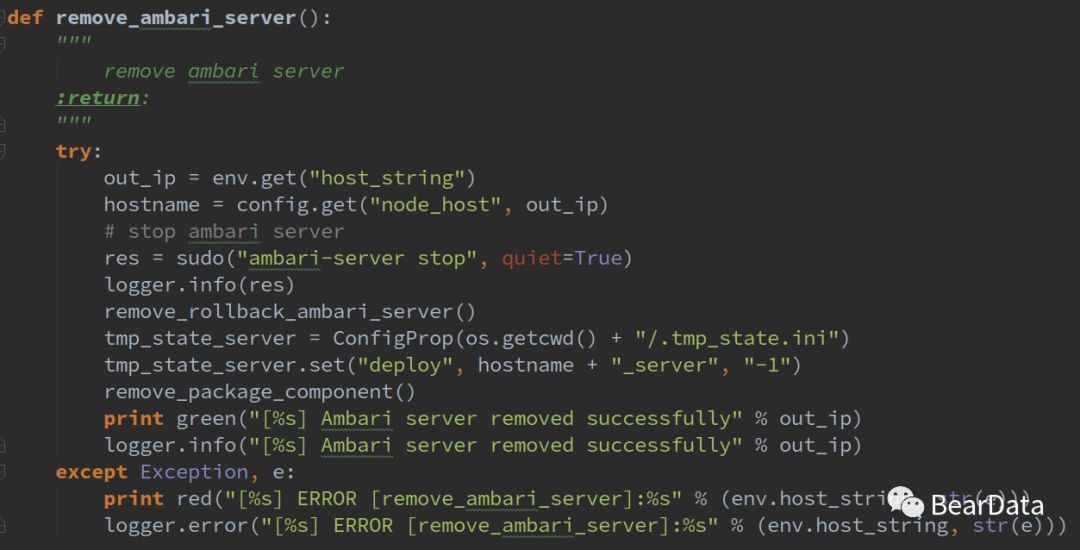
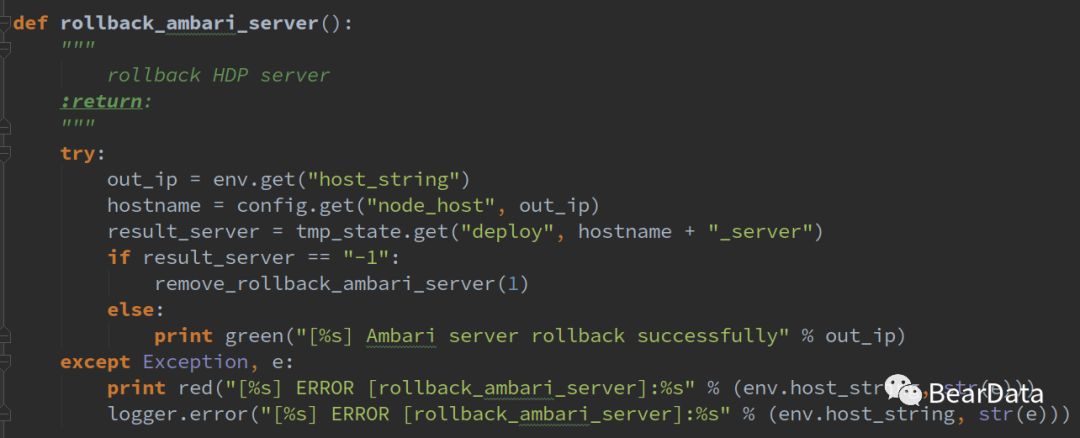
回滚删除,只删除server,已安装成功的节点不进行删除
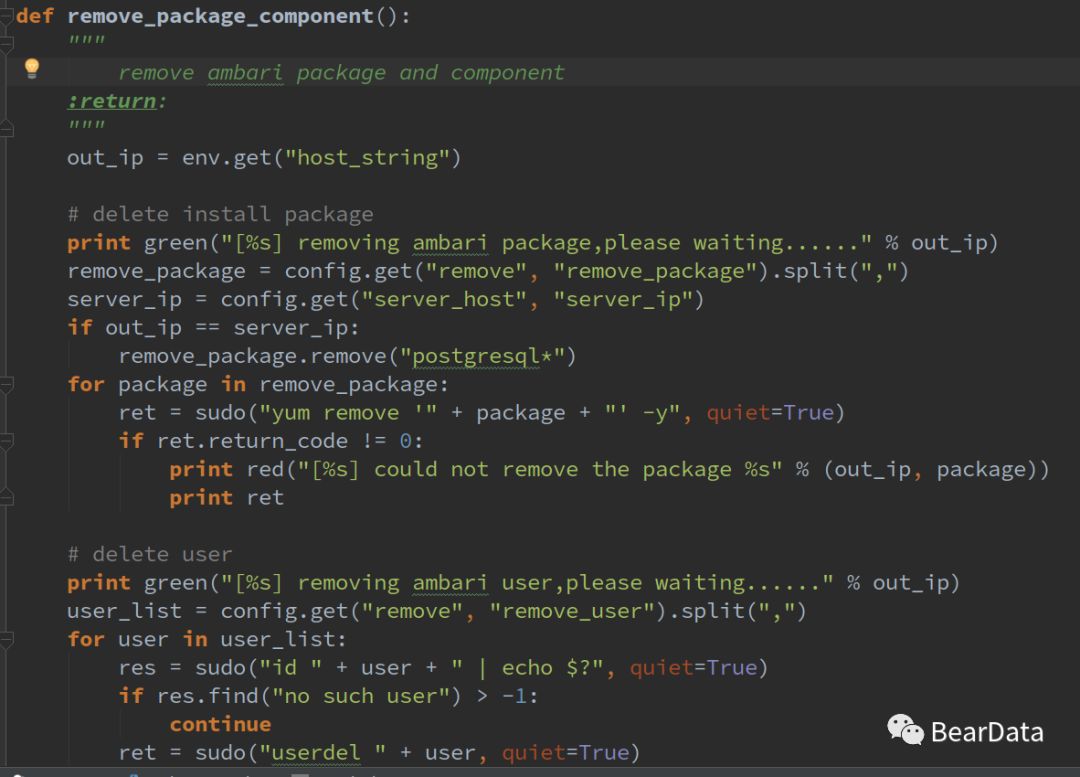
删除组件及用户信息
整体运行演示截图:
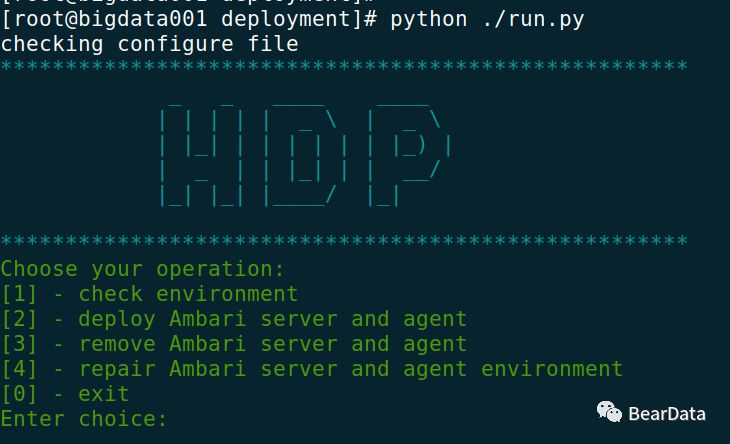
1. 环境检查,发现防火墙未关闭
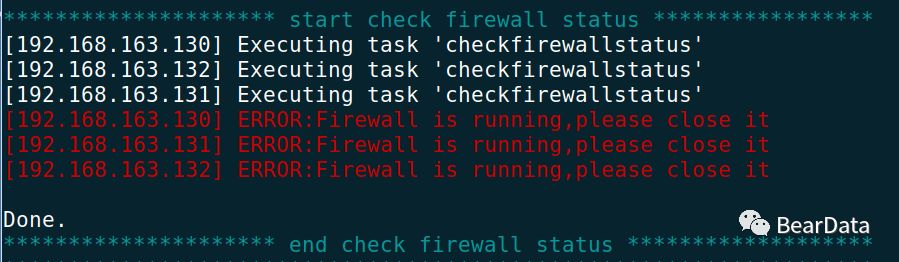
2. 修复环境
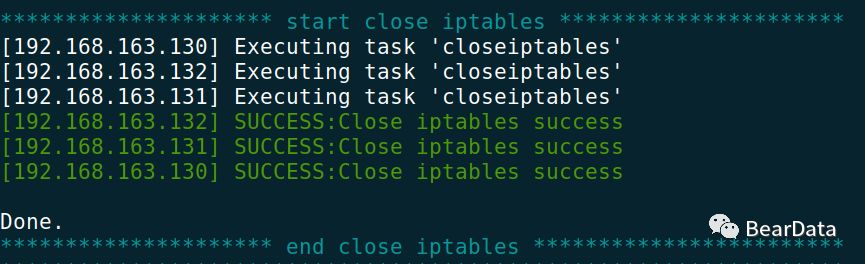
3.重新检查
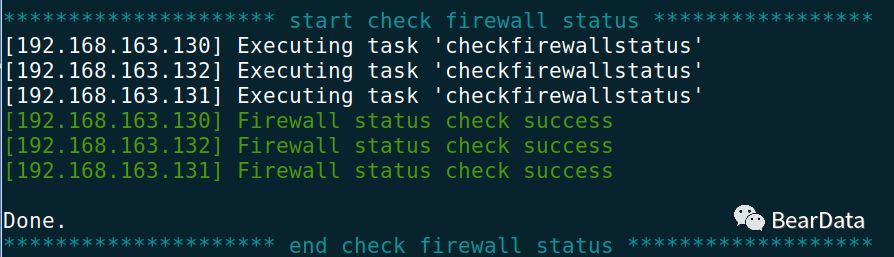
4.安装Ambari
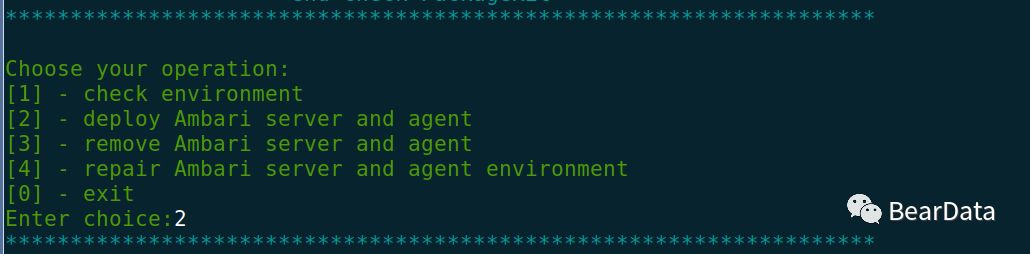
5. 安装过程
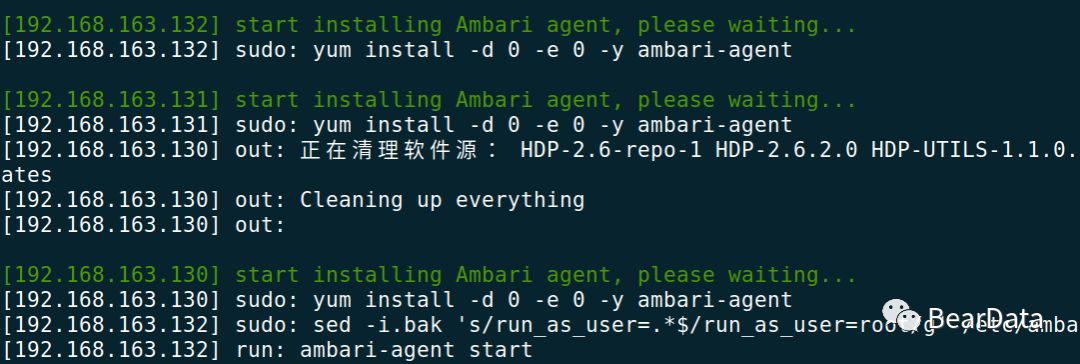
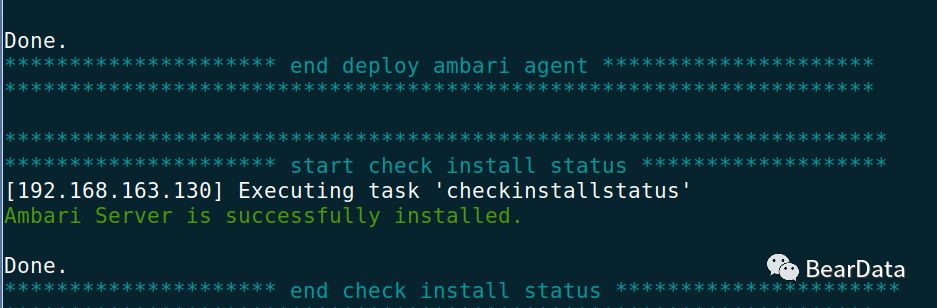
6. 安装完成
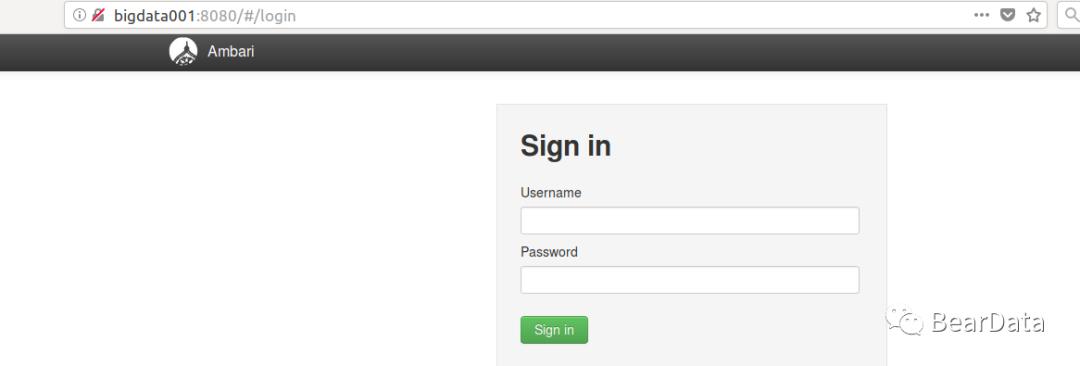
7. 访问http://bigdata001:8080 进行验证,安装组件
8. 卸载Ambari Server和Agent
以上就是Ambari一键自动化部署脚本的思路和演示,下一篇我们将对Ambari的源代码结构进行说明。
长按二维码,关注BearData
以上是关于003-Ambari一键自动化脚本部署的主要内容,如果未能解决你的问题,请参考以下文章