微服务治理下的RSocketEnvoy IstioKnative
Posted 工匠小猪猪的技术世界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微服务治理下的RSocketEnvoy IstioKnative相关的知识,希望对你有一定的参考价值。
每天分享一个技术知识点,推荐一篇值得阅读的好文,我们一起终身学习。
之前的这篇文章读者朋友们非常喜欢,今天,我们一起继续聊聊这个话题,让大家能够迅速了解RSocket、Envoy、 Istio、Knative是什么以及技术选型的对比。

© Nathan Dumlao
很多同学看到这个题目,一定会提这样的问题:RSocket是个协议,Envoy是一个 proxy,Istio是service mesh control plane + data plane。 这三种技术怎么能放在一起比较呢?
的确,从技术定位的角度来讲,它们确实是有很大的差距。但是,如果我们用RSocket来治理微服务,会有哪些不同呢?
RSocket
RSocket是一种应用层协议,不是一个传输层的协议。一方面,它可以包容和支持不同的传输层协议和相关技术,比如tcp 和 proto buf。另一方面,它的重点是把反应流的实现,提升到应用层上来。
其实在底层的协议中,就有反应流的实现,tcp的滑动窗口就是很好的例子。但是往上,这种好的机制不见了,给编程的工作造成很多的麻烦。很大一部分的线上故障是由于阻塞链接造成的。另一方面,很多应用层的网络软件,从设计的时候就开始避免这样的麻烦,造成结构臃肿,通讯效率底下。简单的例子是如果所有的通讯都是反应式的,那就不用熔断了。
基于RSocket 的应用不止是端到端通讯,Broker也是对这个协议水到渠成的应用。作为一个反应式的Broker,它同样是异步,非阻塞的通讯方式,主要维护与就近的各个应用的链接以及和其它Broker的链接。与其它协议相比,它是多路复用,同时支持长链接。
经过这样的解释,不难理解,本文主要是针对RSocket应用通过RSocket Broker联结而形成的Mesh,与其它Service Mesh项目在不同层次和方面的对比。

RSocket vs .Envoy
Envoy作为一个proxy,它主要是基于HTTP2/HTTP1.1的协议,当然这样做是符合市场的口味,但是这个协议的局限性也限制了Envoy的性能。这就是我们比较的第一点,
1. Envoy不支持多路复用,非阻塞和有限支持长链接。说是有限,其实就是不支持,因为你的链接只要不能一直开着,就得依靠第三方做health check。这绝对增加开发难度。不支持多路复用,就无法对每个服务都开个链接,那么就要靠第三方作service registry。
这样的限制,不但使得Envoy必须依靠一个control plane,自己无法独立担负weave mesh的重担,而且也大大限制了它的性能,比如新版本Istio Proxy(就是Envoy)用的联接池管理就占了很多的内存。
而对于RSocket来说,
2. RSocket的主要障碍是应用程序之间必须要用RSocket通讯。随着Spring Cloud的推出,Spring Framework 5.2 即将要把RSocket作为缺省的反应通讯协议,以及Dubbo和RSocket 的整合,大家接触RSocket的机会也会越来越多。
另外,
3. 很多场合中会听到Envoy支持Polygoat,好像用了Envoy就不用SDK了。这种说法显然是错觉。SDK是一定要的,为了支持Polygoat,就要选多语言支持的SDK。因为调用另一个服务的代码还是发生在自己的程序中,这不是Envoy可以替代的。Envoy所说的省却SDK开发,是指所谓的“胖SDK”, 就是包括了服务发现和路由功能的SDK,类似大家现在用的Dubbo,那的确是会让SDK瘦身的。但是如果用了RSocket的Broker,这些SDK同样也不用再“胖”了,而且RSocket协议也有不同语言的SDK。
RSocket vs .Istion
除了上述的简化和高效等特性外,相比Istio,RSocket Broker 有一个主要的优势,那就是不依赖Kubernets 。虽然Istio也号称不依赖Kubernets,但是在Kubernets外部署和管理sidecar proxy可不是一件容易的事,而RSocket Broker却是哪里都能部署。
作为一个Service Mesh solution, Istio其实是很难在 data center外应用的。那么对于众多的IoT设备怎么办?每一台手机上装个sidecar?而RSocket是很小且高效的SDK,这也是像Facebook这样的主要手机应用商选择RSocket的原因。
Istio主打的特性是observability, security and control。从observability和control方面来说,RSocket Broker虽然有接口,但是实现还不够,特别是API的部分。这也是社区要努力的一个方向。从security来说,如果是单纯RSocket的服务是不用开端口的,这是又一项由先进协议带来的对特性的简化,以后会有更多的介绍。
结论
很早以前,在分布程序中访问另一个服务是很直观,透明的事。微服务普及后,其为了“简化”微服务之间的通讯,引入了很多层的技术栈。这当然是好事,但是很多的决定是由于收到上一代的通讯协议的技术所限制。
RSocket的反应流技术,简化了程序间通讯对其它部件的依赖。我们可以享受Service Mesh提供的便利而不用那么复杂的技术栈。当然RSocket带来的好处不只是简单。在我们的初步实验中,RSocket Broker的service mesh比Istio带来将近10倍的速度提升。如果大家有兴趣,可以去了解一下RSocket.(阅读http://rsocket.io/)
Istio

Istio 1.0 于北京时间8月1日0点正式发布!虽然比原本官网公布的发布时间晚了9个小时,但这并未影响到Istio在社区的热度。
Istio 是 Service Mesh概念的具体实现。2018年被称为 Service Mesh 原年,誉为新一代的微服务架构,有了Service Mesh,像Docker和Kubernetes标准化部署操作一样来标准化我们的应用程序运行时的操作便成为可能。Istio是其中最成熟和被广泛接受的开源项目。它是连接、管理和保护微服务的开放平台。今天发布的1.0 版本是一个重要的里程碑。这意味着Istio的所有核心功能都已经可以落地部署,不再只是演示版了。
从功能上说,1.0版本是对0.8版本的补充和加强。从0.8之前版本到1.0版本,改变的部分从网络,策略和遥测,适配器,到安全等几大模块,都有补充和增强。
1.0版本中的新功能大致如下:
➤ 网络
使用 Virtual Service 进行 SNI 路由
流式 gRPC 恢复
旧版本(v1alpha1)的网络 API 被移除
Istio Ingress 被gateway替代
➤ 策略和遥测
属性更新
缓存策略检查
遥测缓冲
进程外适配器
客户端遥测
➤ Mixer 适配器
SignalFX
Stackdriver
➤ 安全
RPC 级授权策略
改进的双向 TLS 认证控制
JWT 认证
在众多的改变中,下面几点和之前版本相比,有较大的增强和改动,在这里我们展开介绍下:
➤ IstioGateway 替代 IstioIngress
在 istio 1.0 之前,Istio Ingress 直接使用 Kubernetes Ingress,因此受到 Kubernetes 的 Ingress 本身只有 L7 的网络控制功能的限制,很多功能无法实现。这些功能包括:
L4-L6的LB
对外的mTLS
对SNI(服务器名称指示)的支持
以及其它在Pilot已经实现的对内部网络的功能,比如Traffic splitting,fault injection, mirroring, header match等。
为了解决这些问题,Istio 在 1.0 版本提出了 Istio Gateway 的概念,从而摆脱了对 Kubernetes Ingress 的依赖,可以实现更多的功能,例如: L4-L6的LB,对外的mTLS,对SNI(服务器名称指示)的支持等。
如果我们希望给一个 Kubernetes 的 guestbook ui Service 做一个 Istio Ingress 的话,在 0.8 版本以前我们需要如下定义一个 Istio Ingress Resourse:
apiVersion:extensions/v1beta1
kind:Ingress
metadata:
annotations:
kubernetes.io/ingress.class:istio
name:simple-ingress
spec:
rules:
- http:
paths:
- path:/.*
backend:
serviceName:guestbook-ui
servicePort:80
这里面是我们对 L7 的策略配置。但是可以看到,基于这种 Ingress 并不能支持 mTLS 等高级功能。现在在 Istio 1.0 版本,我们可以使用新的 Istio Gateway 来完成类似的配置。这种配置会分两部分:
L4-L6 的配置在 Gateway 这种资源中;
L7 的配置在绑定的 Virtual Services 配置资源中。
对于上面同样的例子,Istio Gateway 资源的定义是这样的:
apiVersion:networking.istio.io/v1alpha3
kind:Gateway
metadata:
name:simple-gateway
spec:
servers:
- port:
number:80
name:http
protocol:HTTP
- port:
number:443
name:https
protocol:HTTPS
hosts:
- sample.default.example.com
tls:
mode:SIMPLE
serverCertificate:/tmp/tls.crt
privateKey:/tmp/tls.key
通过 Gateway 这种资源,我们提供了对mTLS的支持。为了完成对 HTTP path 的匹配和对 Virtual Host 的支持,我们需要定一个新的 VirtualService 资源并且将它和 Gateway 资源绑定。Virtual Services 很像以前的 Virtual Host,它可以允许同一个IP对应不同的域名,所以即使同样的路径也不会产生重复。
它的配置和与 Gateway 的绑定如下:
apiVersion:networking.istio.io/v1alpha3
kind:VirtualService
metadata:
name:sample
spec:
hosts:
- guestbook-ui.default.example.com
gateways:
- simple-gateway
http:
- match:
- uri:
prefix:/get
route:
...
➤ Mixer 进程外适配器
适配器是让第三方用户来扩展Mixer功能的,比如和自己的 Logging 系统集成。以前的适配器,是与 Mixer 主进程在一起的。这样有些问题,比如如果适配器有用户的认证信息,那么上传的时候所有人都知道了。另外,如何对这些适配器做健康检查(health check)呢? 它们在同一个进程里。
新的版本,适配器在 Mixer 主进程之外,用户不但可以决定是否要把适配器上传,而且运行时也可以进行外部健康检查了。
不过由于适配器 和 Mixer 主进程不在同一个进程,需要进行进程间通讯,因此适配器要和主进程通讯会依赖 RPC。这里 Mixer 选用了比较流行的标准 RPC 框架 gRPC作为实现。
有了这个功能,在 Istio 的 Mixer 中开发外适配器功能只需要如下三个步骤:
编译适配器源代码
生成适配器模版
部署适配器镜像
如果有兴趣更深入的了解适配器的开发和使用,请参考这两个教程
第一部分:
https://github.com/istio/istio/wiki/Out-Of-Process-gRPC-Adapter-Dev-Guide
第二部分:
https://github.com/istio/istio/wiki/gRPC-Adapter-Walkthrough
➤ 支持可以使用身份验证策略配置的 JWT 身份验证
JWT(JSON Web Token)是一种基于token的鉴权机制。JWT很流行的原因主要是它的简单易用,特别是采用JSON格式,是大部分编程语言支持的。所以尽管出现的时间不长,但却是很多编程人员的鉴权首选。因此 Istio 对 JWT 进行了支持。
例如我们创建一个 JWT token payload来庆祝 Istio 1.0 GA :
{
"iss":"istio",
"sub":"1.0 GA",
"iat":1533073556
}
用户调用时,需要把 JTW token 来编码后,以 Bearer 形式进行传递:
GET http://35.45.16.16/api/v1/packages?packageNumber=MPDS-372766142-5899
Host: sample.default.example.com
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJpc3RpbyIsInN1YiI6IjEuMCBHQSIsImlhdCI6MTUzMzA3MzU1Nn0.SkgIHM5ecYsn_hWGewyPFgBAQw79g4hAMEtpXzidKaM
Istio 就用这个Bearer来作最终用户认证。是不是很简单呢?Istio 之前就支持基于 JWT 的Authentication。新的版本开始支持 Authorization。对用户来说,只是在同一个Authentication policy 的资源上扩展一部分而已。
Istio的 Authorization 是基于角色的访问控制,它提供命名空间级别, 服务级别和 method-level 的访问控制。
要实现Authorization,只需要如下几步:
首先要开启允许授权;
开启了特定级别(如:命名空间)的授权;
创建这个级别的访问控制策略。
更详尽的内容,可以参考 Istio 安全文档:
https://istio.io/zh/docs/concepts/security/
Knative
在今年的Google Cloud Next大会上,Google发布了Knative, 这是由Google、Pivotal、Redhat和IBM等云厂商共同推出的Serverless开源工具组件,它与Istio,Kubernetes一起,形成了开源Serverless服务的三驾马车。
有意思的是:上述几家公司是相互竞争的,但却能把各自擅长的技术贡献给同一个开源项目。另一个有意思的地方是对Serverless定义的转变。以前说到Serverless,大家就等同于FaaS,就感觉只要把function代码提交,然后定义event trigger就好了。现在Knative把Serverless这个概念转变成了免运维:用户还是要有server的,只是运维上比管理一个Kubernetes cluster更省心,而且不用的时候并不需要为server资源支付费用。除此之外,FaaS的应用场景很小,只有很小很快的函数才能比较容易部署。Knative以自助的方式实现部署,应用场景更广,且一般的应用都可以部署成Serverless。
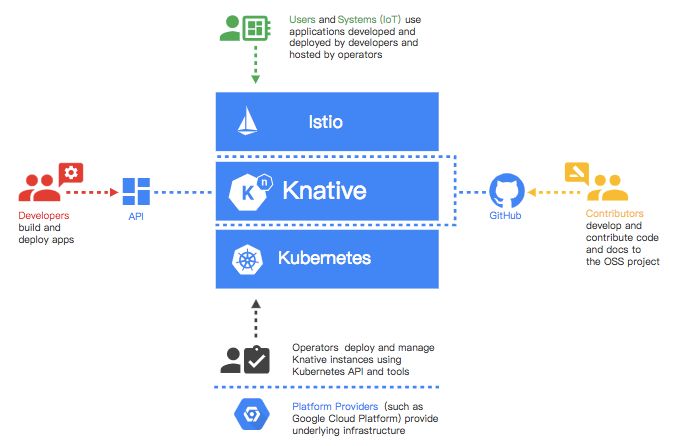
根据Knative提供的文档介绍,一个完整的Serverless分为Build,Serve和Eventing三个部分。在本文中,我们将在阿里云上按照Knative github的安装指南,逐步操作,以实现一个Knative应用。
准备
创建 Kubernetes cluster
在阿里云上创建一个Kubernetes cluster,用系统默认的设置就行,但要保证你有Admin权限。如果你用已有的 cluster,请确认Kubernetes的版本是1.10以上。
安装 Knative
这个过程分为两步:
1. 安装Istio: Knative的Istio有一些自己定义的资源,所以不要用Istio网站的缺省安装。但是Knative现有指南未更新,还是0.8,有些旧。我所用的是1.0:
curl https://raw.githubusercontent.com/knative/serving/master/third_party/istio-1.0.0/istio.yaml
这个安装需要一点时间,但是是必须的。因为Knative依赖Istio来联接Serverless,而不是直接通过Kubernetes。等到所有的安装完成后,我们要开启Istio 自动injection:
kubectl label namespace default istio-injection=enabled2. 安装 Knative组件: 执行下面的命令:
kubectl apply -f https://github.com/knative/serving/releases/download/v0.1.1/release.yaml安装后等待一会并确认:
kubectl get pods -n knative-serving -w
kubectl get pods -n knative-build -w细心的同学会发现这里只安装了两部分:Build 和 Serving,那么Eventing呢?是需要单独安装的。
kubectl apply -f https://storage.googleapis.com/knative-releases/eventing/latest/release.yaml同样的,运行这个命令来确认:
kubectl get pods -n knative-eventing -wBuild
Build是目前Knative项目中内容最丰富的部分。因为Pivotal拿出了压箱宝build packs加入Knative。而Google之前多年做app engine,也在这方面累计了很多经验。
在实现上,Build是一个Kubernetes Custom Resource Definition (CRD)。如同其它的Kubernetes CRD,定义的方式是通过YAML,调用的方式是API。用户可以选择不同的build template,比如Google的kaniko,Pivotal的build pack等。在本文中,我们选择kaniko build。
先安装Kaniko Build Template:
kubectl apply -f https://raw.githubusercontent.com/knative/build-templates/master/kaniko/kaniko.yaml
Kaniko build template和Docker build template最大的不同在于用户不需要本地安装Docker engine, Kaniko把代码搬到云上生成Image。源代码可以在远程的服务器上,还要指定相应的Dockerfile。
但是,这样做有个问题:Kaniko怎么访问用户的docker account呢?因此,我们需要创建一个secret,把用户的docker username和password存在里面。然后,还需要一个service account来绑定这个secret。 vim secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: docker-user-pass
annotations:
build.knative.dev/docker-0: https://index.docker.io/v1/
type: kubernetes.io/basic-auth
stringData:
username: <docker username in plain text>
password: <docker password in plain text>
把这里的username和password换成你自己的帐号信息,然后保存。 kubectl apply-f secret.yaml vim service-account.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: build-bot
secrets:
- name: docker-user-pass
保存后执行: kubectl apply-f service-account.yaml
然后我们创建Kubernetes manifest vim build.yaml:
apiVersion: build.knative.dev/v1alpha1
kind: Build
metadata:
name: docker-build
spec:
serviceAccountName: build-bot #service account created above
source:
git:
revision: master
url: "https://github.com/szihai/hello-go.git"
steps:
-
args:
- "--dockerfile=/workspace/Dockerfile"
- "--destination=docker.io/xxx/helloworld-go"
image: "gcr.io/kaniko-project/executor:v0.1.0"
name: build-and-push
本文所用的sample app是从Knative repo 上fork的。
在这里,我们指定了template用Kaniko。然后可以看到我们引用了前面的ServiceAccount 来访问secret。用这个之前把里面的 destination换成你自己的docker id,保存后用 kubectl apply-f build.yaml 来执行。
那么,如何知道远程的Kaniko到底做好了没有呢?Kubernetes 会为 kind:Build 创建一个job。用 kubectlgetpods 找到一个 docker-build-xxxx 的pod。然后运行: kubectl-ndefaultlogs docker-build-xxxx-c build-step-build-and-push 来观察build的情况。
我们也可以直接查看Kubetnetes build objects: kubectl describe builds。要找的信息是:

当然,最直接的方法是去自己的Docker hub上找到这个Image。
Serving
这个部分与普通的Kubetnetes服务发布差别不大。先定义一个服务: vim service.yaml
apiVersion: serving.knative.dev/v1alpha1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
runLatest:
configuration:
revisionTemplate:
spec:
container:
image: docker.io/{username}/helloworld-go
env:
- name: TARGET
value: "Go Sample v1"
运行 kubectl apply-f service.yaml。需要注意的是这里我们用了serving.knative.dev 的API。所以与其它部署有所不同:不需要deployment.yaml。这可理解为deployment被knative给包办了。如果运行 kubectlgetdeployments,就可以看到 helloworld-go-xxxx-deployment。
这里找到 EXTERNAL-IP。然后我们找到Domain name:
kubectl get service.serving.knative.dev helloworld-go -o=custom-columns=NAME:.metadata.name,DOMAIN:.status.domain
接着运行:
curl -H "Host: {DOMAIN}" http://{EXTERNAL-IP}
结果应该是: HelloWorld:GoSamplev1!如果有一段时间没访问该服务,就会发现运行 kubectlgetpods 的时候,这几个helloworld-go pod不见了。那是knative把replica数降为0。
Eventing
对于FaaS的来说,Eventing就是触发这个function的机制。上面我们用 curl去访问服务,其实是为了测试而已。在真实的部署过程中,这个function应该是有事件触发的。
Eventing是传统的FaaS的主要功能,也是除源代码外唯一与开发者真正相关的部分。正因为如此,其它FaaS,如Lambda, Openshift等,都可以通过这一层与Knative接口。
Knative设计的Eventing包括3个主要的概念:
Source: 就是事件发生的起源,可以理解为与其它系统的接口,目前支持的包括K8sevents,GitHub和GCP PubSub 。
Buses: 事件传输的途径,目前支持的有Stub,Kafka和GCP PubSub。
Flows: 定义对事件的反应。这可以是连锁的反应而不是单一的。 所以,我们要做的事就是,选一个Source,选一个Bus, 然后定义一个Flow,就可以啦。 本文中,我们选用K8events和Stub ClusterBus。先把它们装上:
kubectl apply -f https://storage.googleapis.com/knative-releases/eventing/latest/release-clusterbus-stub.yaml
kubectl apply -f https://storage.googleapis.com/knative-releases/eventing/latest/release-source-k8sevents.yaml
在生成flow之前,有一个小问题:K8 event是Kubernetes内部产生的,要接收的话,必须要通过一个Service Account 来授权。这是Kubernetes的要求,不是本文重点,如前面一样,保存后执行:
apiVersion: v1
kind: ServiceAccount
metadata:
name: feed-sa
namespace: default
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: create-deployment
namespace: default
rules:
- apiGroups: ["apps"]
resources: ["deployments"]
verbs: ["get", "list", "watch", "create", "update", "delete", "patch"]
---
# This enables the feed-sa to deploy the receive adapter.
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: feed-sa-deploy
namespace: default
subjects:
- kind: ServiceAccount
name: feed-sa
namespace: default
roleRef:
kind: Role
name: create-deployment
apiGroup: rbac.authorization.k8s.io
---
# This enables reading k8s events from all namespaces.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: feed-admin
subjects:
- kind: ServiceAccount
name: feed-sa
namespace: default
roleRef:
kind: ClusterRole
name: view
apiGroup: rbac.authorization.k8s.io
接下来是主要的一步,创建flow: vim flow.yaml :
apiVersion: flows.knative.dev/v1alpha1
kind: Flow
metadata:
name: k8s-event-flow
namespace: default
spec:
serviceAccountName: feed-sa
trigger:
eventType: dev.knative.k8s.event
resource: k8sevents/dev.knative.k8s.event
service: k8sevents
parameters:
namespace: default
action:
target:
kind: Route
apiVersion: serving.knative.dev/v1alpha1
name: helloworld-go
接着运行 kubectl apply-f flow.yaml就可以了。
我们来看一下是不是真的运行了呢?过一会儿运行: kubectlgetpods会看到k8s-event-flow-xxx的job运行完了。然后helloworld-go的pod都启动了。我们看一下日志: kubectl logs helloworld-go-xxxxx user-container,就会看到如下的结果:
Hello world received a request.
Hello world received a request.
Hello world received a request.
Hello world received a request.
...
这说明这条链路是起作用的。那么,这个flow的定义说了什么呢?首先是用了刚刚定义的service account。然后在 trigger中定义什么样的event可以符合条件,这里我们说所有在 default namespace 的k8events 都符合。在action中我们定义有什么样的处理方式,本例中就直接调用了helloworld-go service。
结论
Knative是今年最新的云计算演进方向之一。阿里云支持Kubernetes,可以成功运行Knative和Istio等应用,大家也可以到阿里云上自己体验一番。
当然,作为一个新的备受瞩目的项目,Knative也会经历其成长的烦恼。我们会持续跟进,并提供和Knative相关、但不限于实践的分享,敬请期待。
Andy Shi:阿里巴巴中间件硅谷团队 Istio 技术专家,Andy长期关注Service Mesh,在Cloud Foundry,Kubernetes,Envoy上有着丰富的实践和开发经验。

▽
关注猪猪
以上是关于微服务治理下的RSocketEnvoy IstioKnative的主要内容,如果未能解决你的问题,请参考以下文章
Istio微服务治理网格的全方面可视化监控(微服务架构展示资源监控流量监控链路监控)
Spring Cloud vs Istio微服务治理框架对比