华尔街见闻Istio生产实践 Posted 2021-04-13 分布式实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了华尔街见闻Istio生产实践相关的知识,希望对你有一定的参考价值。
随着见闻业务不断增加,所涉及语⾔也越来越多。由于微服务化的引入,就需要为不同语言开发各自的服务发现、监控、链路追踪等组件,更新运维成本较高。同时应用的灰度部署也是见闻在着⼒解决的问题。Istio通过下沉基础设置,很好的解决了组件跨语言兼容问题, 同时带来了智能路由、服务熔断、错误注入等重要的特性。整个搭建过程中也遇到了很多坑和经验,希望和大家分享。
见闻开发团队以Golang为主,同时存在Python,Java服务,这就需要SRE提供更容易接入的微服务基础组件,常见的方案就是为每种语言提供适配的微服务基础组件,但痛点是基础组件更新维护的成本较高。
为了解决痛点,我们将目光放到服务网格,它能利用基础设施下沉来解决多语言基础库依赖的问题,不同的语言不需要再引入各种不同的服务发现、监控等依赖库,只需简单的配置并运行在给定的环境下,就能享有服务发现、流量监控、链路追踪等功能,同时网络作为最重要的通信组件,可以基于它实现很多复杂的功能,譬如智能路由、服务熔断降级等。
我们调研了一些服务网格方案,包括Istio、Linkerd。
对比下来,Istio拥有更多活跃的开源贡献者,迭代速度快,以及Istio架构可行性讨论,我们选择Istio作为实践方案。
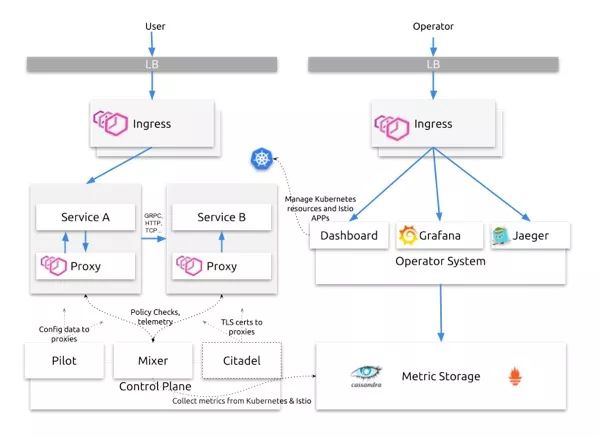
这张图介绍了华尔街见闻典型的服务网格架构,左半图介绍了用户请求是如何处理,右半图介绍运维系统是如何监控服务。
通过架构图,我们拆分出以下关键组件,经过评估,Istio高度模块化、可拓展,各个组件的可用性、拓展性都有相应的策略达到保障,我们认为Istio是具有可实施性的。
性能:Istio Ingress用来处理用户入流量,使用Envoy实现,转发性能高。
可用性:保证实例数量并使用服务探活接口保证服务可用性。
拓展性:挂载在负载均衡后,通过增加实例实现可拓展。
Istio Proxy随应用部署,轻微性能损耗,可随应用数量拓展
Istio Proxy以Sidecar形式随应用一起部署,增加2次流量转发,存在性能损耗。
性能:4核8G服务器,上面运行Proxy服务和API服务,API服务只返回ok字样。(此测试只测试极限QPS)
单独测试API服务的QPS在59k+,平均延时在1.68ms,CPU占用4核。通过代理访问的QPS6.8k+,平均延时14.97ms,代理CPU占用2核,API服务CPU占用2核。
CPU消耗以及转发消耗降低了QPS,增加了延时,通过增加机器核数并增加服务部署数量解决该问题,经过测试环境测试,延时可以接受。
可用性:基于Envoy,我们认为Envoy的可用性高于应用。依赖Pilot Discovery进行服务路由,可用性受Pilot Discovery影响。
Istio Policy服务可拓展,但同步调用存在风险
Istio Policy需要在服务调用前访问,是同步请求,会增加服务调用延时,通过拓展服务数量增加处理能力。属于可选服务,华尔街见闻生产环境未使用该组件。
可用性:若开启Policy,必须保证Policy高可用,否则正常服务将不可用。
性能:从监控上观察Report 5000qps,使用25核,响应时间p99在72ms。异步调用不影响应用的响应时间。
性能:服务发现组件(1.0.5版本)经过监控观察,300个Service,1000个Pod,服务变更次数1天100次,平均CPU消耗在0.04核左右,内存占用在1G以内。
可用性:在服务更新时需要保证可用,否则新创建的Pod无法获取最新路由规则,对于已运行Pod由于Proxy存在路由缓存不受Pilot Discovery关闭的影响。
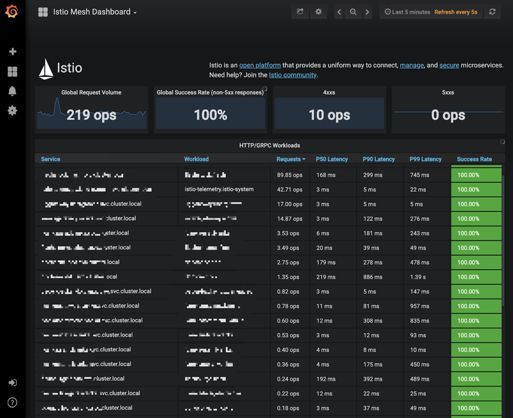
Istio通过mixer来搜集上报的遥测数据,并自带Prometheus、Grafana等监控组件,可方便的对服务状态进行监控。见闻目前监控在用Istio自带的,利用Prometheus拉取集群指标,经由Grafana看板展示,可直观展示出各种全局指标及应用服务指标,包括全局QPS、全局调用成功率、各服务延时分布情况、QPS及状态码分布等, 基本满足监控所需。
存储暂未做持久化操作,采用Prometheus的默认的内存存储,数据的存储策略可通过设定Prometheus的启动参数--storage.tsdb.retention来设定,见闻生产时间设定为了6h。
Prometheus服务由于数据存储原因会消耗大量内存,所以在部署时建议将Prometheus部署在专有的大内存node节点上,这样如果内存使用过大导致该node节点报错也不会对别的服务造成影响。Istio mixer担负着全网的遥测数据搜集任务,容易成为性能瓶颈,建议和Prometheus一样将其部署在专有节点上, 避免出现问题时对应用服务造成影响。
Envoy原生支持分布式链路追踪, 如Jaeger、Zipkin等,见闻生产选择了Istio自带的Jaeger作为自身链路追踪系统。默认Jaeger服务为all_in_one形式,包含jaeger-collect、jaeger-query、jaeger-agent等组件,数据存储在内存中。
见闻测试集群采用了此种部署形式。见闻生产环境基于性能与数据持久性考虑,基于Cassandra存储搭建了单独的jaeger-collect、jaeger-query服务。Jaeger兼容Zipkin,可以通过设定Istio ConfigMap中的zipkinAddress参数值为jaeger-collector对应地址,来设置Proxy的trace上报地址。同时通过设置istio-pilot环境变量PILOT_TRACE_SAMPLING来设置tracing的采样率,见闻生产采用了1%的采样率。
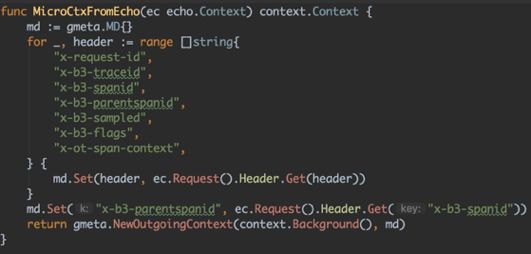
Tracing不像Istio监控系统一样对业务代码完全无侵入性。Envoy在收发请求时若发现该请求没有相关trace headers,就会为该请求自动创建。tracing的实现需要对业务代码稍作变动,这个变动主要用来传递trace相关的header,以便将一次调用产生的各个span串联起来。
见闻底层采用 grpc 微服务框架,在Gateway层面将trace header 加入到入口grpc调用的context中,从而将trace headers 逐级传递下去。
Istio通过向Pod注入Sidecar接管流量的形式实现服务治理,那么就会有Sidecar与业务容器状态不同步的可能,从而造成各种的调用问题,如下两方面:
Sidecar就绪时间晚于业务容器:业务容器此时若发起调用,由于Sidecar还未就绪, 就会出现类似no healthy upstream之类错误。若此时该Pod接收请求,就又会出现类似upstream connect error错误。
Sidecar就绪时间早于业务容器:例如某业务容器初始化时间过长导致Kubernetes误以为该容器已就绪,Sidecar开始进行处理请求,此时就会出现类似upstream connect error错误。
探活涉及Sidecar、业务容器两部分,只有两部分同时就绪,此Pod才可以正式对外提供服务,分为下面两方面:
Sidecar探活:v1.0.3及以上版本针对Pilot-agent新增了一个探活接口healthz/ready,涉及statusPort、applicationPorts、adminPort等三个端口。其基本逻辑为在statusPort上启动健康监测服务,监听applicationPorts设定的端口是否至少有一个成功监听,之后通过调用本地adminPort端口获取xDS同步状态。若满足至少一个applicationPort成功监听,且CDS、LDS都进行过同步,则该Sidecar才被标记为Ready。
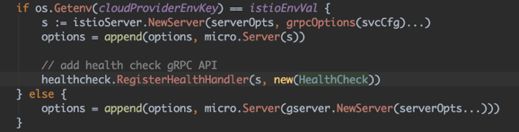
业务容器探活:见闻通过基本库,在所有Golang grpc后端服务中注册了一个用于健康检查的handler, 该handler可由开发人员根据自身业务自定义,最后根据handler返回值来判断业务容器状态(如下图)。
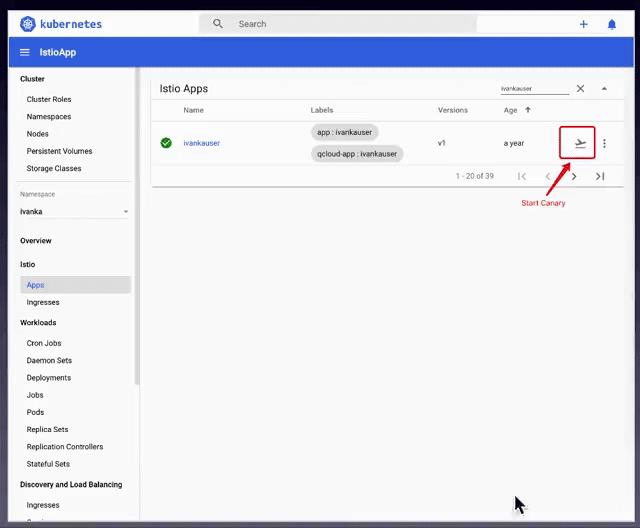
为了实现灰度部署,见闻基于Kubernetes Dashboard进行了二次开发,增加了对Istio相关资源的支持,利用Gateway、VirtualService、DestinationRule等crd实现了应用程序的灰度部署,实际细节如下:
更新流量控制将流量指向已有版本,利用VirtualService将流量全部指向v1版本(见下动图)。
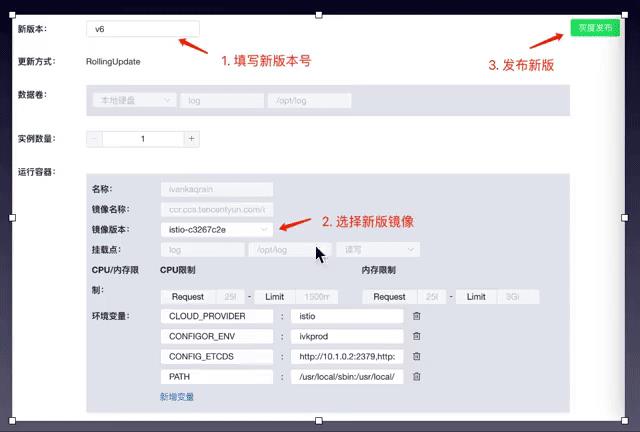
部署新版本的Deployment,查找旧的Deployment配置,通过筛选app标签符合应用名的Deployment,运维人员基于该Deployment创建v2版本的Deployment,并向destinationRule中增加v2版本。
更新流量控制将流量指向新版,本利用VirtualService将ServiceA的服务流量全部指向v2版本。
下线老版本的Deployment并删除对应DestinationRule。
利用Istio Dashboard来实现上述流程:
为了方便开发人员服务部署,开发了精简版后台,并对可修改部分进行了限定。最终,SRE提供两个后台,对Istio Dashboard进行精细控制:
Istio对Kubernetes的API有很强的依赖,诸如流量控制(Kubernetes资源)、集群监控(Prometheus通过Kubernetes服务发现查找Pod)、服务权限控制(Mixer Policy)。所以需要保障API server的高可用,我们曾遇到Policy组件疯狂请求Kubernetes API server使API server无法服务,从而导致服务发现等服务无法更新配置。
服务配置是Istio部署后的重头戏,避免使用手动方式更改配置,使用代码更新配置,将常用的几个配置更新操作做到运维后台,相信手动一定会犯错。
Pilot Discovery 1.0.0版本有很大的性能问题,1.0.4有很大的性能提升,但引入了一个新bug,所以请使用1.0.5及以上的版本,我们观察到CPU消耗至少是1.0.0版本的1/10,大大降低了Proxy同步配置的延时。
这个组件曾导致API server负载过高(很高的list pods请求),所以我们暂时束之高阁,慎用。
在使用Proxy、Telemetry时,默认它们会打印访问日志,我们选择在生产上关闭该日志。时刻观察Istio社区的最新版本,查看新版本各个组件的性能优化以及bug修复情况,将Istio当做高度模块化的系统,单独升级某些组件。上面就提到我们在Istio1.0的基础上使用了1.0.5版本的Policy、Telemetry、Pilot Discovery等组件。
Istio依靠Proxy来帮助APP进行路由,考虑几种情况会出现意外的状态:
APP启动先于Proxy,并开始调用其它服务,这时Proxy尚未初始化完毕,APP调用失败。
Service B关闭时,调用者Service A的Proxy尚未同步更新Service B关闭的状态,向Service B发送请求,调用失败。第一种情况要求APP有重试机制,能适当重试请求,避免启动时的Proxy初始化与APP初始化的时差,Istio提供了retry次数配置,可以考虑使用。第二种情况,一种是服务更新时,我们使用新建新服务,再切流量;一种是服务异常退出,这种情况是在客户端重试机制。希望使用Istio的开发人员有更好的解决方案。
A:Service Mesh是最近比较火的一个概念,和微服务、Kubernetes有密切关系。出于以后业务发展需要,可以学习下, 增加知识储备。见闻上Istio的主要目的在文章已说明,主要是基础服务的下沉,解决了语言兼容性问题, 还有一个就是灰度发布。
Q:
链路追踪的采集方式是怎样的,比如Nodejs,C++等多语言如何支持的?
A:Envoy本身支持链路追踪,也就是将Envoy会在请求head中增加链路追踪相关的数据头,比如x-b3-traceid,x-b3-spanid等等。业务要做的就是将这些head沿着调用链路传递下去即可。所以多语言的话需要在自己的业务侧实现该逻辑。所以Istio的链路追踪对业务代码还是有很小的侵入性的(这个分享中有说明)。
Q:
Istio与Spring Cloud两者的优缺点与今后的发展趋势会是怎么样?
A:见闻技术栈是Golang,所以没太认真对比过两者。从社区活跃度上将,Istio > Spring Cloud,稳定性方面,Spring Cloud是更有优势,更适合Java沉淀较深的企业。但个人感觉对于更多企业来讲,跨越了语言兼容性的Istio未来发展很值得期待。
Q:
Docker镜像部署可以做到代码保护吗,比如像Nodejs这种非二进制执行程序的项目?
A:代码保护可以通过将镜像上传至指定云服务商上的镜像仓库中,见闻是将自己的业务镜像提交保存在了腾讯云。如果镜像泄露,那么非二进制执行程序的代码还是有泄露风险的。
A:选型之初也调研了Linkerd, 对比下来,Istio拥有更多活跃的开源贡献者,迭代速度快,以及Istio架构相较于见闻有较大可行性,所以选择了Istio作为实践方案。
Q:
Istio在做运维部署时没有UI工具,你们如何实现运维人员更加便捷地使用?
A:见闻基于Kubernetes官方的Dashboard, 对内容进行了扩充,增加了对Gateway,VirtualService等Istio crd资源的支持, 同时增加了灰度部署等和见闻运维业务相关的功能,所以一定程度上解决了运维部署的问题。
Q:
流量从Sidecar代理势必会对请求响应时间有影响,这个有没有更详细案例的说明性能上的损耗情况?
A:Sidecar的转发其实带来了性能一定的性能损耗。4核8G服务器,上面运行Proxy服务和API服务,API服务只返回ok字样。(此测试只测试极限QPS)单独测试API服务的QPS在59k+,平均延时在1.68ms,CPU占用4核。通过代理访问的QPS6.8k+,平均延时14.97ms,代理CPU占用2核,API服务CPU占用2核。CPU消耗以及转发消耗降低了QPS,增加了延时,通过增加机器核数并增加服务部署数量缓解该问题,经过测试环境测试,延时可以接受。
Q:
Sidecar在生产中资源占用为多少?
是否会对集群资源占用很多?
A:以单个Pod为例,见闻业务单个Pod中Sidecar所占资源约占整个Pod所耗资源的1/10。
Q:
Jeager你们是进行了代码埋点吗?
更为底层代码级别的追踪,有用其他方案吗?
A:Envoy本身对tracing有良好的支持,所以业务端所做的改动只需将其所产生的追踪数据延续下去即可。上Istio之前,见闻在相关微服务中通过在基础库中增加链路追踪逻辑(Zipkin)实现了链路追踪,不过只做了Golang版,多语言兼容开发运维难度较大。
基于Kubernetes的DevOps实践培训将于2019年5月10日在上海开课,3天时间带你系统掌握Kubernetes,学习效果不好可以继续学习。 本次培训包括:容器特性、镜像、网络;Kubernetes架构、核心组件、基本功能;Kubernetes设计理念、架构设计、基本功能、常用对象、设计原则;Kubernetes的数据库、运行时、网络、插件已经落地经验;微服务架构、组件、监控方案等,点击下方图片查看详情。
以上是关于华尔街见闻Istio生产实践的主要内容,如果未能解决你的问题,请参考以下文章
开发新系统,取代安卓?刚刚,华为这样回应……
16.ajax_case06
1.nuxt是什么?
Flutter使用ListView加载列表数据
奇点临近:互联网经济的供给侧革命和全球货币政策的新格林斯潘之谜
第992期webpack 2 打包实战(上)