散列表的平均查找长度怎么计算?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了散列表的平均查找长度怎么计算?相关的知识,希望对你有一定的参考价值。
如题:假定一个待散列存储的线性表为(32,78,29,63,48,94,25,36,18,70,49,80),散列地址空间为HT[11] ,若采用除留余数法构造散列函数和链接法处理冲突,求出平均查找长度?(这个公式到底有用吗:1/2(1+1/(1-装填因子)))
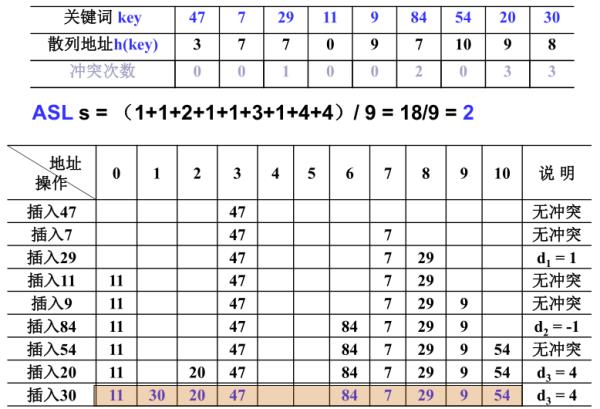
对于含有n个数据元素的查找表,查找成功的平均查找长度为:ASL=∑PiCi (i=1,2,3,…,n),可以简单以数学上的期望来这么理解。其中:Pi 为查找表中第i个数据元素的概率,Ci为找到第i个数据元素时已经比较过的次数。
在查找表中查找不到待查元素,但是找到待查元素应该在表中存在的位置的平均查找次数称为查找不成功时的平均查找长度,不成功。
扩展资料
散列表的查找过程基本上和造表过程相同。一些关键码可通过散列函数转换的地址直接找到,另一些关键码在散列函数得到的地址上产生了冲突,需要按处理冲突的方法进行查找。在介绍的三种处理冲突的方法中,产生冲突后的查找仍然是给定值与关键码进行比较的过程。所以,对散列表查找效率的量度,依然用平均查找长度来衡量。
查找过程中,关键码的比较次数,取决于产生冲突的多少,产生的冲突少,查找效率就高,产生的冲突多,查找效率就低。因此,影响产生冲突多少的因素,也就是影响查找效率的因素。影响产生冲突多少有以下三个因素:
1、散列函数是否均匀;
2、处理冲突的方法;
3、散列表的装填因子。
散列表的装填因子定义为:α= 填入表中的元素个数 / 散列表的长度
α是散列表装满程度的标志因子。由于表长是定值,α与“填入表中的元素个数”成正比,所以,α越大,填入表中的元素较多,产生冲突的可能性就越大;α越小,填入表中的元素较少,产生冲突的可能性就越小。
实际上,散列表的平均查找长度是装填因子α的函数,只是不同处理冲突的方法有不同的函数。
参考资料来源:百度百科-平均查找长度
参考资料来源:百度百科-散列表
参考技术A 先构造散列表,再将查找到每个关键码的探查次数求和,然后除以关键码的总个数就是ASL了这个数据序列的结果就是17/12
这个公式只是用随机过程和排队论得出的理论性能,大量的随机数据的平均值就是这个值,但是每个表的值并非如此 参考技术B 一、分析问题:这是一个建立哈希函数的问题。 哈希表中元素是由哈希函数确定的。将数据元素的关键字K作为自变量,通过一定的函数关系(称为哈希函数),计算出的值,即为该元素的存储地址。表示为: Addr = H(key) 为此在建立一个哈希表之前需要解决两个主要问题: ⑴构造一个合适的哈希函数 均匀性 H(key)的值均匀分布在哈希表中; 简单 以提高地址计算的速度 ⑵冲突的处理 冲突:在哈希表中,不同的关键字值对应到同一个存储位置的现象。即关键字K1≠K2,但H(K1)= H(K2)。均匀的哈希函数可以减少冲突,但不能避免冲突。发生冲突后,必须解决;也即必须寻找下一个可用地址。 本题是用除留余数法构造散列函数(哈希函数),用链接法(拉链法)处理冲突。1、除留余数法:取关键字被某个不大于哈希表表长m的数p除后所得余数为哈希地址。 H(key)=key MOD p (p<=m)2、拉链法:拉出一个动态链表代替静态顺序存储结构,可以避免哈希函数的冲突,不过缺点就是链表的设计过于麻烦,增加了编程复杂度。此法可以完全避免哈希函数的冲突。确定记录在查找表中的位置,需和给定值进行比较的关键字个数的期望值称为查找算法在查找成功时的平均查找长度(Average Search Length),ASL成功。 对于含有n个数据元素的查找表,查找成功的平均查找长度为:ASL=∑PiCi (i=1,2,3,…,n),可以简单以数学上的期望来这么理解。其中:Pi 为查找表中第i个数据元素的概率,Ci为找到第i个数据元素时已经比较过的次数。 在查找表中查找不到待查元素,但是找到待查元素应该在表中存在的位置的平均查找次数称为查找不成功时的平均查找长度,ASL不成功。二、解答问题散列地址空间为HT[11] p=11所以32%11=10......80%11=3。所以散列地址为(10,1,7,8,4,6,3,3,7,4,5,3) ASL=∑PiCi (i=1,2,3,…,n),在这里n=12p1=1/12,C1=0;P2=1/12,C2=1;然后你自已求解吧
散列及碰撞处理
散列是一种常用的数据存储技术。散列使用的数据结构叫做散列表。在散列表上插入、删除、取用数据都非常快,但是对于查找来说效率很低。
散列表的长度是预先设定的,存储数据时,通过一个散列函数将键映射为一个数字,这个数字的长度为0到散列表的长度。编写散列函数前需要先确定散列表数组的长度,我们对数大小常见的限制是:数组长度应该是一个质数。数组长度的确定策略都是基于处理碰撞问题的。
1、散列函数
我们采取的散列方式为除留余数法,基于这个方法的散列函数可以更加均匀的分布随机的整数键。对于字符串类型的键,散列值可以设为每个字符的ASCII码值的和除以数组长度的余数。散列函数定义如下:
function simpleHash(data) { var total = 0; for ( var i = 0; i < data.length; ++i) { total += data.charCodeAt(i); } return total % this.table.length; }
于是,HashTable类的构造函数如下:
function HashTable() { this.table = new Array(137);this.simpleHash = simpleHash; this.showDistro = showDistro; this.put = put; //this.get=get; } function simpleHash(data) { var total = 0; for ( var i = 0; i < data.length; ++i) { total += data.charCodeAt(i); } return total % this.table.length; } function put(data) { var pos = this.simpleHash(data); this.table[pos] = data; } function showDistro() { for ( var i = 0; i < this.table.length; ++i) { if (this.table[i] != undefined) { document.write(i + ": " + this.table[i]); document.write("<br />"); } } }
simpleHash()散列函数通过JavaScript的charCodeAt()函数,返回每个字符的ASCII码值,相加得到散列值,put()方法通过调用simpleHash()得到数组的索引,并将数据存储到该索引对应的位置。通过实验可以发现,这个散列函数散列的数据并不是均匀分布的,向数组的两端集中,并且更严重的问题是,容易引发碰撞!所以需要优化一下散列函数来避免碰撞。
为了避免碰撞:
1、首先要保证散列表中用来存储数据的数组大小是个质数。这个计算散列值时采取的取余运算有关。
2、有了合适的散列表大小后,接下来就需要有一个更好的散列函数。霍纳算法很好的解决了这个问题。新的散列函数在每次求值前都先乘以一个质数,这里建议使用一个较小的质数。
使用霍纳算法的散列函数:
function betterHash(data) { const H = 37; var total = 0; for ( var i = 0; i < data.length; ++i) { total += total*H + data.charCodeAt(i); } total = total % this.table.length;
return parseInt(total);
}
2、从散列表中存取数据
使用散列表来存储数据,我们需要重新定义put() 方法,使其可以同时接受键和数据作为参数,对键值散列后,将数据存储到散列表中:
function put(key, data) { var pos = this.betterHash(key); this.table[pos] = data; }
get() 方法同样需要对键值进行散列化,得到数据在散列表中存储的位置:
function get(key) { return this.table[this.betterHash(key)]; }
3、碰撞处理
1)开链法
开链法是指,实现散列表的底层数组中,每个数组元素又是一个新的数组结构。
实现开链法的方法:在创建存储散列过的键值的数组时,通过调用一个函数创建一个空的新数组,将该数组赋值给散列表里的每个数组元素,创建一个二维数组。我们称这个数组为链。函数buildChains() 定义如下:
function buildChains() { for ( var i = 0; i < this.table.length; ++i) { this.table[i] = new Array(); } }
使用了开链法后,我们需要重新定义put()和get()方法。
put()方法先将键值散列,散列后的值对应数组中的一个位置,先查看该位置上数组的第一个单元格是否有值,如果有值则会搜索下一个位置,直到找到可以存放数据的单元格,并将数组存储进去,新的put()方法实现如下:
function put(key, data) { var pos = this.betterHash(key); var index = 0; if (this.table[pos][index] == undefined) { this.table[pos][index] = key; this.table[pos][index + 1] = data; } else { while (this.table[pos][index] != undefined) { ++index; } this.table[pos][index] = key; this.table[pos][index + 1] = data; } }
新的put()方法不同于之前的方法,之前的方法仅存放数据,而新的put()方法使用链中两个相同的单元格同时存放了散列后的键值和数据,第一个单元格存放键值,第二个单元格存放数据。这样便于在碰撞出现时,链中存放多条数据时,从散列表中取值。
get()方法先对键值散列,根据散列后的值找到散列表中相应的位置,查找该位置的链中是否存在这个键值,如果有,则把紧跟在键值后面的单元格的数据返回,没找到就返回undefined。新的get()方法实现如下:
function get(key) { var index = 0; var pos = this.betterHash(key); if(this.table[pos][index] == key) { console.log(this.table[pos][index + 1]); return; } else { while (this.table[pos][index] != key) { index += 2; } console.log(this.table[pos][index + 1]); return; } document.write(‘undefined‘); return; }
散列表现在使用的是多维数组存储数据,为了更好的显示使用了开链法后键值的分布,则需要对showDistro()方法进行如下修改:
function showDistro() { for ( var i = 0; i < this.table.length; ++i) { if (this.table[i][0] != undefined) { document.write(i + ": " + this.table[i]); document.write("<br />"); } } }
2)线性探测法
线性探测法隶属于一种更一般化的散列技术:开放寻址散列。当发生碰撞时,线性探测法会检查散列表中下一个位置是否为空,如果为空,则将数据存储在该位置,如果不为空,则继续检查下一个位置,直到找到空位置为止。当存储数据的数组特别大时,选择线性探测法要比开链法好,有一个公式可以帮助我们来判断使用那种碰撞处理方法:如果数组的大小是待存储数据的1.5倍,使用开链法;如果数组的大小是待存储数据的两倍或两倍以上,则选择线性探测法。
下面用代码说明线性探测法的工作原理,重新定义put()和get()方法,在构造函数中新增加一个数组
this.values = [];
数组value和table并行工作,table用来存储键值,value用来存储对应的数据。put()方法定义如下:
function put(key, data) { var pos = this.betterHash(key); if (this.table[pos] == undefined) { this.table[pos] = key; this.values[pos] = data; } else { while (this.table[pos] != undefined) { pos++; } this.table[pos] = key; this.values[pos] = data; } }
get()方法先搜索散列后的键值在散列表中的位置,如果在table中找到key,则返回values中对应位置上的数据,如果没找到则循环搜索,直到找到了table中对应的键,或者table中对应的值为undefined时,表示键值和数据没有存储到散列表。get()方法如下:
function get(key) { var hash= -1; var hash= this.betterHash(key); if(hash > -1) { for (var i=hash; this.table[i] != undefined; i++) { if (this.table[i] == key) { return this.values[i]; } } } return undefined; }
以上是关于散列表的平均查找长度怎么计算?的主要内容,如果未能解决你的问题,请参考以下文章