利用Flask等开源软件快速搭建数据分析平台
Posted 编程派
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用Flask等开源软件快速搭建数据分析平台相关的知识,希望对你有一定的参考价值。
本文介绍了如何使用开源软件迅速的搭建一个数据分析平台,包含数据导入,变形,分析,预测,可视化。
原文:https://my.oschina.net/taogang/blog/630632
最近,国内涌现出了不少数据分析平台产品,例如和。
这些产品的目标应该都是 self service 的 BI ,利用可视化提供数据探索的功能,并且加入机器学习和预测的功能。它们对标的产品应该是 Tableau 或者 SAP Lumira 。因为笔者曾经为 Lumira 开发数据可视化的功能,对这一块很感兴趣,于是就试用了一下这些产品,感觉这些产品似乎还有很大的差距,于是就想自己用开源软件搭一个简单的数据分析平台试试看。
代码在这里
废话少说,上架构图:
列一下主要用到的开源软件:
服务器端:
flask
轻量级的 Python Web 框架
pandas
Python 的数据结构和数据分析工具包,提供数据处理的 Wrangling 的功能
sklearn
非常流行的Python机器学习包,依赖于,和
客户端:
jquery
这个就不用介绍了
reactjs
facebook 开发的 js UI 框架,基于组件( component )而非 mvc
d3js
数据驱动的 DOM 操纵库,可以创建丰富的数据可视化呈现。
echarts
百度开发的数据可视化库,基于 canvas 技术,功能丰富。实为中国开源项目的翘楚。
bootstrap
twitter 开发的前端框架,非常流行。
jquery datatables
非常实用的基于 jquery 的表格控件
bootstrap fielinput
html 5文件上传控件
papaparse
CSV 文件的 JS 解析
requirejs
JS 依赖管理
select2
基于 jquery 的 select 控件
开发构建工具
nodejs
这个应该也不用介绍
babel
javascript 的编译器,支持把 ES 6的代码转换成浏览器可执行的代码,这里主要是为了支持 reactjs 使用的 jsx 的编译。
好了,罗列了这么多的开源软件后,我们看看 dataplay 2的功能,然后看看这些开源软件起到的作用和我为什么要选择它们的原因。
在介入正题之前,我们先聊聊dataplay2这个名字,dataplay很容易理解,我希望创建一个简单易用的数据平台,使用起来像玩一样的愉快。但为什么是2呢?因为这个软件很二么?当然不是。其实我之前写过一个的,当时的架构略有不同,为了使用R里的ggplot来支持语法驱动的可视化方案,我后台使用了R/Python的桥接方案,前台的可视化操作会生成ggplot的命令,好处是可以有一个统一的数据模型和语法来驱动数据的可视化分析,便于用户进行数据的探索。然而这样的架构太复杂了,服务器端既有R又有Python,我自己都看不下去了,后来就放弃了。新的dataplay2使用echart的图表库来做可视化,优缺点我们后面再聊。
好了,运行dataplay2非常简单,下载github上的code后,建议安装,所有的Python依赖就都准备好了,进入dataplay2/package目录,运行:
python main.py
这里补充说明一下,因为 react 的 jsf 需要编译,需要运行如下的命令用 babel 进行 jsf 的编译才能运行,具体命令如下:
# install node first
# cd package/static
npm install - g babel - cli
npm install babel - preset - es2015 - -save
npm install babel - preset - react - -save
babel - -presets es2015, react - -watch js / --out - dir lib/
另外还需要使用 bower 安装客户端的所有依赖
# install bower first
# cd package/static
bower install
大家也可以参考package/static/package.json了解需要的依赖。有时间需要集成一个更简单的build脚本来做这些事情。生成的JS文件在lib目录下。修改js目录下的原始文件,babel会触发编译,生成新的js文件在lib目录下。
然后在浏览器中键入 localhost :5000启动客户端。

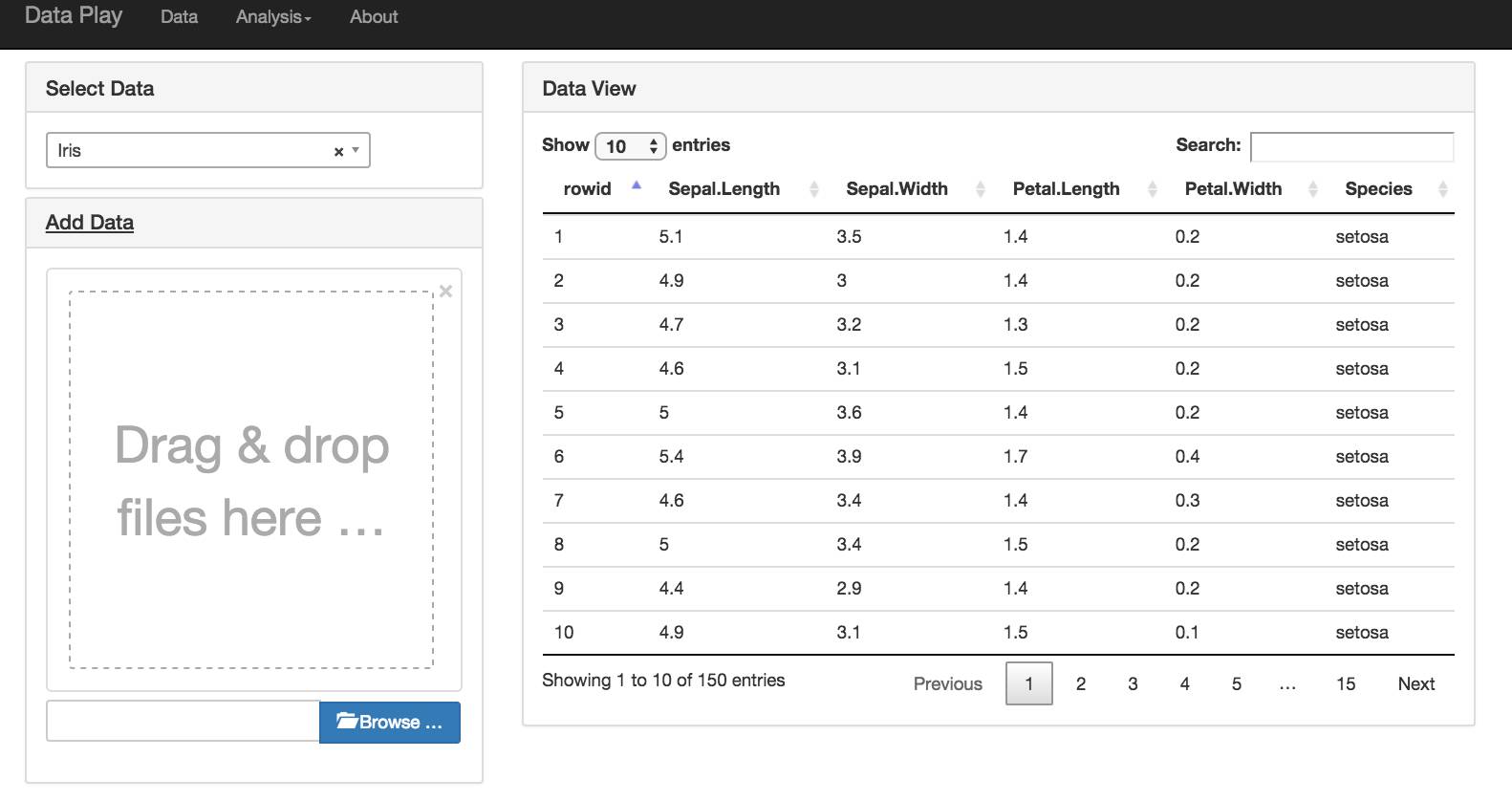
首先我们进入数据菜单

在这个页面,用户可以浏览已有的数据,或者上传一个 CSV 文件,增加一个数据集。
简单介绍一下这一部分的实现。
数据上传用到了 file input 控件,数据表用了 datatable 控件。为了方便 CSV 文件直接存贮在本地文件系统中。后台用 pandas 对 csv 文件进行处理。前台用 Rest API读取csv文件,然后用papaparse解析后,展现在数据表中。这样做纯粹是为了方便,因为整个POC是我在假期花了3/4天做的,所以怎么方便怎么来。更好的做法是在后台用Python对CSV文件作解析。
注意这里我们对上传的 CSV 文件有严格的要求,必须有首行的 header ,末尾不能有空行。
有了数据后,就可以开始做分析了。首先我们看看可视化的分析。点击菜单 Analysis / Visualization
例如我们选定 Iris 数据源做一个 Scatter Plot
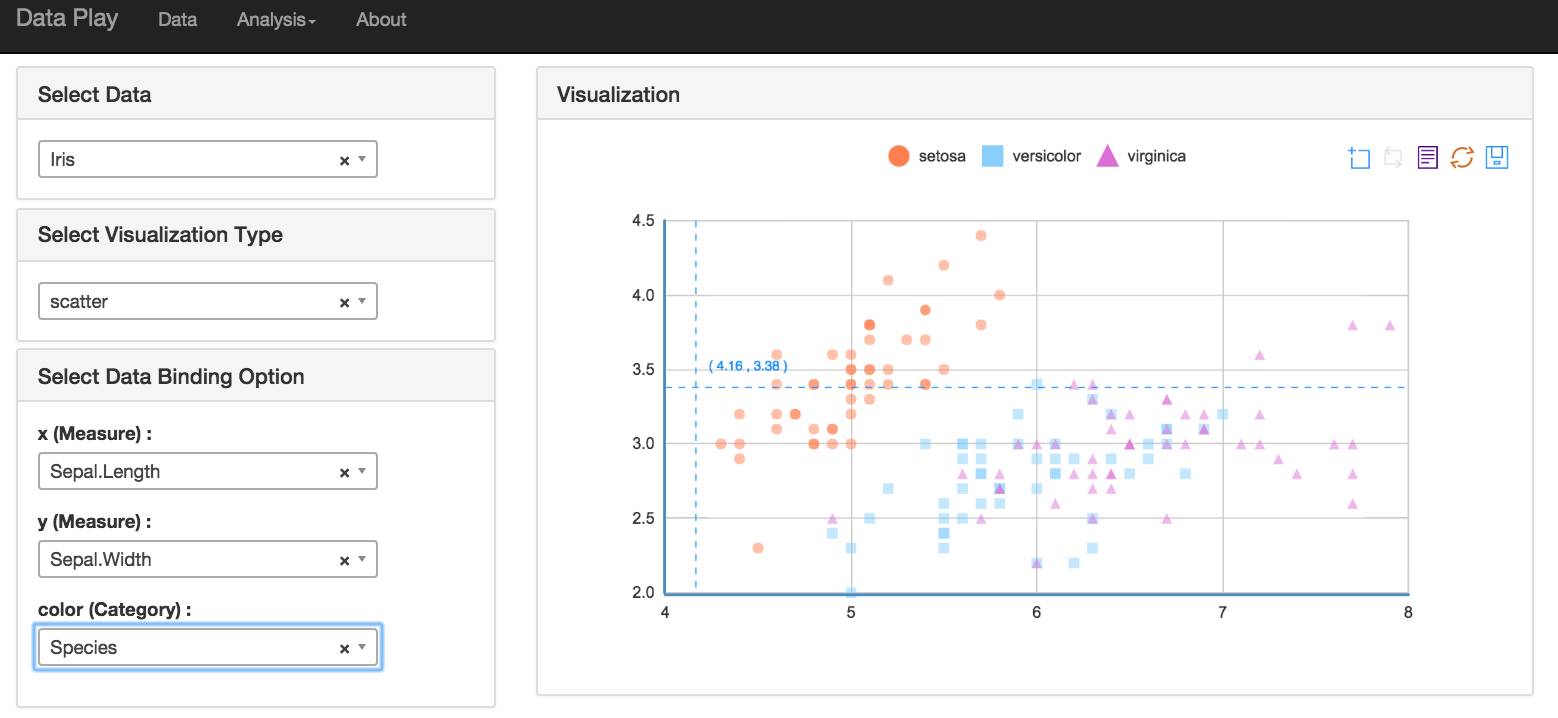
可视化这一块的主要工作是从 CSV 的表结构数据,根据数据绑定,变形到 echart 的数据结构。因为 echart 并没有一个统一的数据模型,所以每一个类型的图表都需要有对应的数据变形的逻辑 。(代码 package/static/js/visualization )
现在主要的做了 Pie , Bar , Line , Treemap , Scatter , Area 这几种 chart 。
现在用下来感觉echart优缺点都很明显,他提供的辅助功能很好,可以方便的增加辅助线,note,存贮为图形等。但是由于缺乏统一的数据模型扩展起来比较麻烦,我希望有时间试用一下,当然highchart是非常成熟的图表库,无需证明。
其实我希望能找到一个ggplot的D3的实现,例如这个 ,可惜该项目似乎不活跃了。
除了基于可视化的分析功能,还有机器学习的功能。
分类
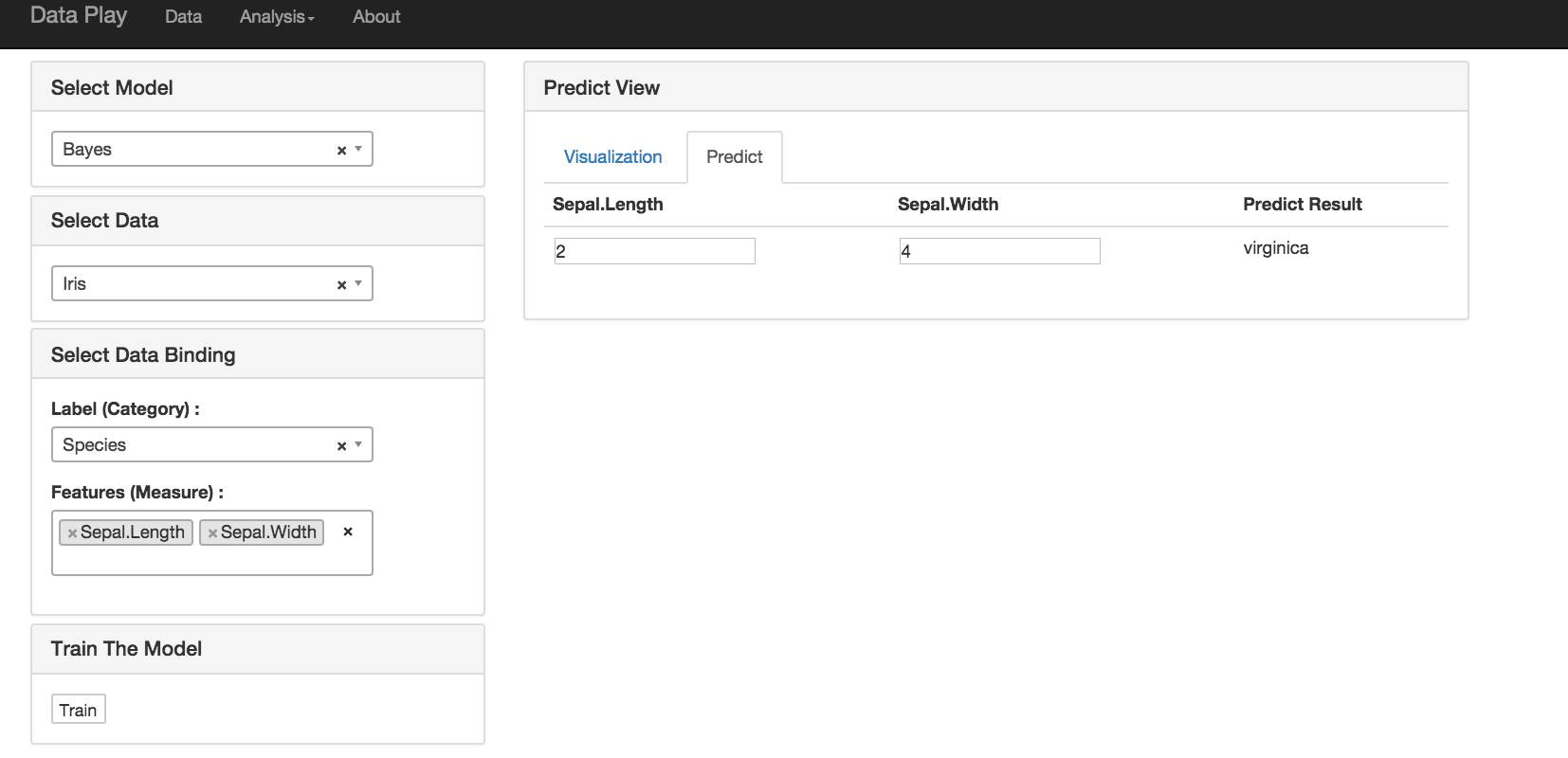
分类的算法可以使用 KNN , Bayes 和 SVM 。
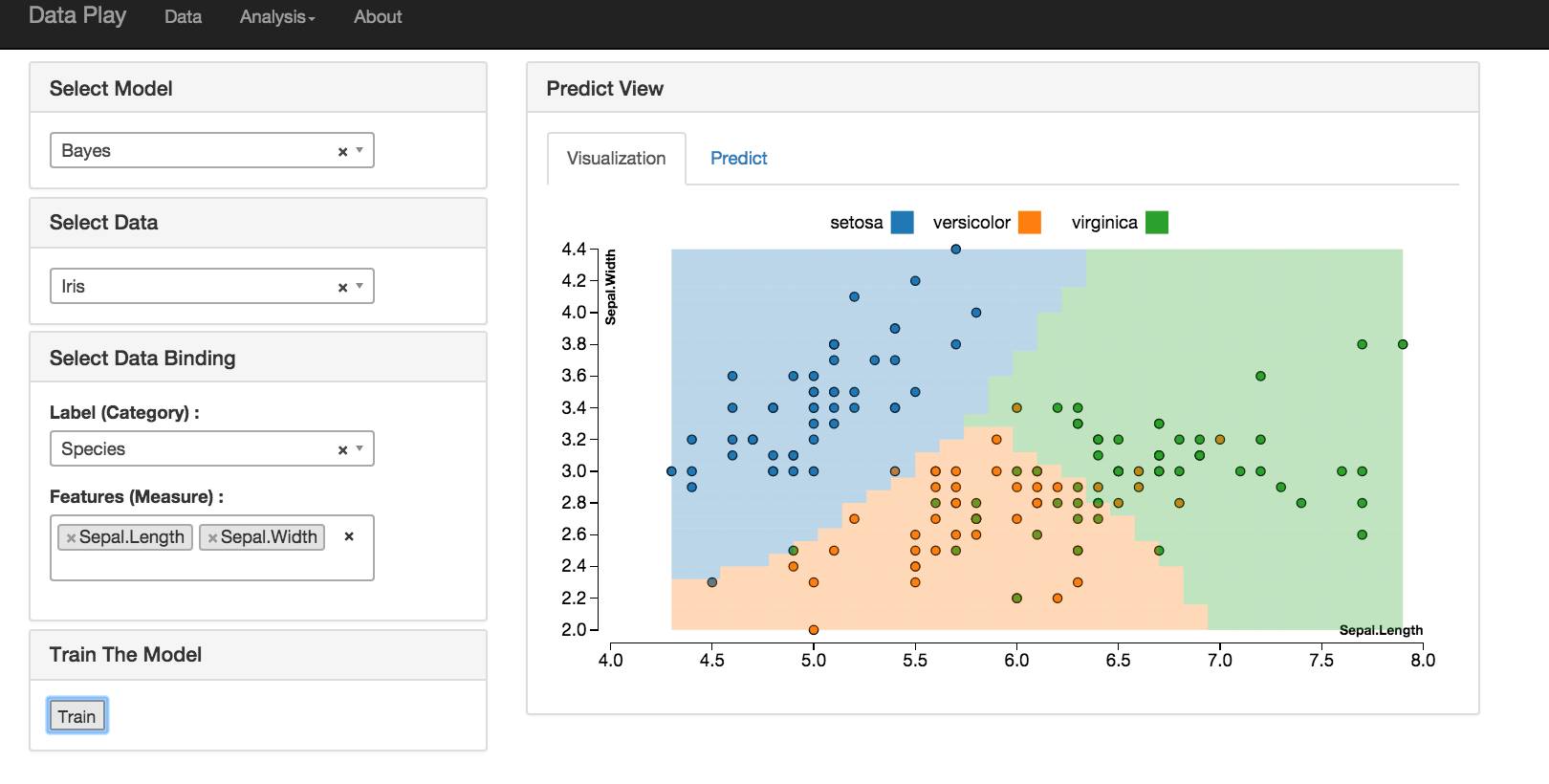
如果选择两个 Feature 做预测,我用 D 3画出了该预测的模型。大于两个时,就没有办法画出来了。
然后用户可以选择基于该模型来做预测。
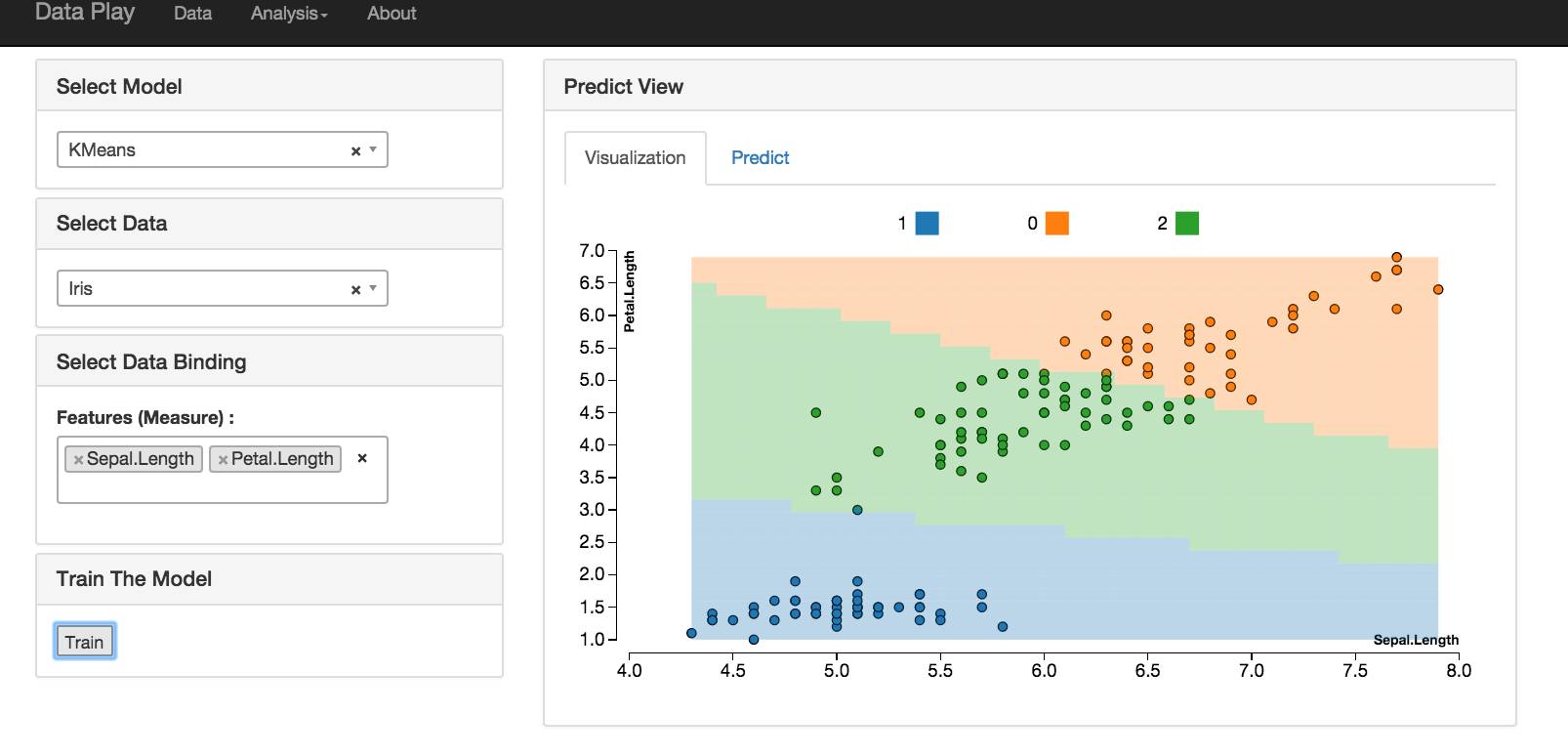
聚类和回归的功能和分类基本一致。
聚类
聚类算法现在实现了 Kmeans
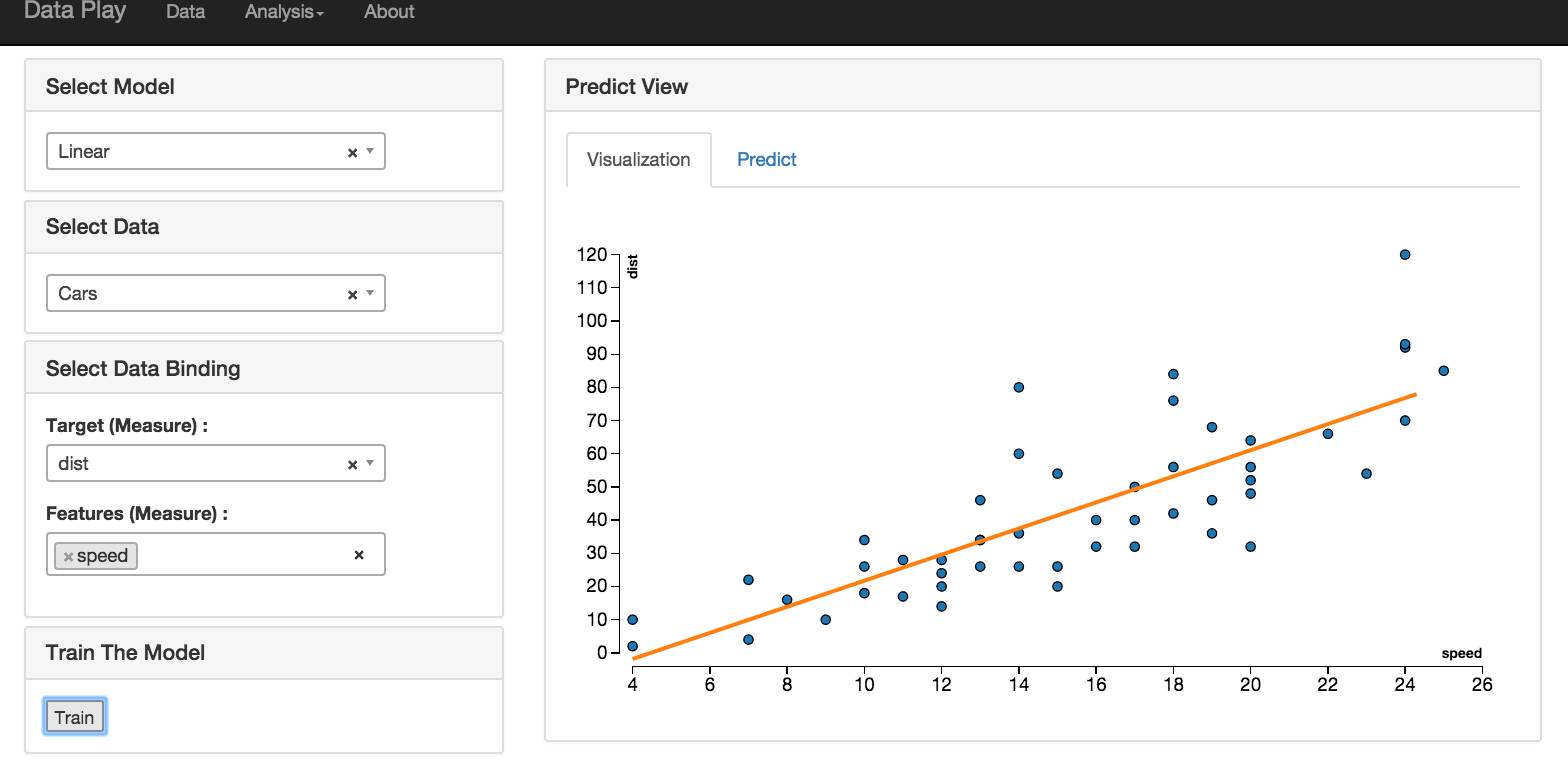
线性回归
逻辑回归
基本功能就这些了,这里列出一些我想要实现的功能:
数据源
现在的数据源只有 CSV 文件,可以考虑更多的数据源支持,例如数据库/数据仓库, REST 调用,流等等。
数据模型
现在的数据模型比较简单,就是 pandas 的 dataframe 或者一个简单的 cvs 的表结构。可以考虑引入数据库。另外还需要增加对层级数据( hierachical )的支持
数据变形
数据变形是数据分析的必要准备工作。业内有很多专注于数据准备的产品,例如,
这个版本的 dataplay 没有任何的数据变形和准备的功能,其实 pandas 有非常丰富的 data wrangling 的功能,我希望能在这之上包装一个 data wrangling 的 DSL ,可以让用户快速的进行数据准备。
可视化库
Baidu 的 echart 是非常优秀的可视化库,可是用于数据探索时,还不够好。希望能有一套类似 ggplot 的前端可视化库来使用。另外地图功能和层级化的图表也是数据分析常见的功能。
还需要加入图表的选项
仪表盘功能
这个版本的dataplay没有仪表盘功能,这个功能是数据分析软件的标配,必须有。似乎是个不错的选择,也和dataplay的架构一致(python,reactjs),有时间可以尝试一下
机器学习和预测
dataplay 现在实现了最简单的一些机器学习的算法,我觉得方向应该是面向用户,变得更简单,用户只给出简单的选项,例如要预测的目标属性,和用于预测的属性,然后自动的选择算法。另外需要更方便的对算法进行扩展。
好了,最后谈谈简单的感受
reactjs真不错,一直不喜欢MVC,reactjs的组件化用起来更舒服,而且开发效率确实高,整个项目我用假期3/4天完成,react功不可没。
dataplay 现在的功能还比较弱,但是基本的架构已经搭好了,大家喜欢的话可以拿去扩展。我不一定会有时间继续对它的功能增强,但是欢迎大家和我一起讨论。
更新:
因为很多同学反映不能正常运行,我制作了一个 Dockerfile ,大家可以参考 https://github.com/gangtao/dataplay2/tree/master/docker 来构建。希望可以解决大家不能运行的问题。Image 已经发布到 dockerhub 了:https://hub.docker.com/r/naughtytao/dataplay/
点击阅读原文,查看更多 Python 教程和资源。
以上是关于利用Flask等开源软件快速搭建数据分析平台的主要内容,如果未能解决你的问题,请参考以下文章