Web开发之旅--Flask使用Celery执行异步任务
Posted 程序猿与吉他狗
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Web开发之旅--Flask使用Celery执行异步任务相关的知识,希望对你有一定的参考价值。
在后端服务器有时候需要处理耗时较长的任务,例如发送电子邮件,在处理这些任务时,这个线程就处于阻塞状态而无法处理新的请求,服务器性能就大大降低,可以将这些耗时较长的任务交给任务队列来处理,处理完成后告诉我们结果就可以了,这样服务器处理请求的能力得到了极大的提高,本文将介绍Flask如何使用Celery来处理耗时任务。
一、知识点
1.任务队列
Celery 是一个异步任务队列。通俗的讲它就是我们的助理,当我们要出差的时候,它会帮我们安排好车辆、订好机票、安装酒店等等。把Flask看成老板,Celery就是它的助理,帮助老板处理琐碎的事情,这样老板就有更多的时间处理其他重要的事情。
2.消息队列
rabbitmq是一个消息队列(message queue)。通俗的讲它就是我们和助理沟通的工具,就像一个日程表,我们将需要助理处理的事情记录在上面,助理就会看到这些事情然后去处理,最后把处理的结果记录在日程表上,当我们看到处理结果后,日程表上的这个事项就划掉了,有时候我们需要保存这些处理结果,所以为助理专门准备了一个记录处理结果的小本本,这个小本本通常使用redis。
3.生产者和消费者
生产者和消费者是相对于消息队列的,老板往消息队列添加任务,所以老板是生产者,助理从消息队列提取任务,所以是消费者。
二、使用Celery的好处
1.应用解耦。
消息是与平台无关的,Flask只需要把需求告诉消息队列即可,由谁来完成并不需要关心,当访问量增加时对Flask不会造成明显的冲击。
2.异步通信。
缩短了请求等待的时间,提高了页面的吞吐量,尤其是瞬间高流量时,消息队列能够有效缓解访问压力。
3.送达保证。
消息队列冗余机制确保了消息最终都会被处理,不会造成数据或操作丢失的情况。
三、如何使用Celery
1.安装初始化配置
安装rabbitmq
http://www.rabbitmq.com/download.html
安装redis
https://redis.io/download
安装celery
pip install celery
配置Celery
vv/config.py:

在config.py中配置Celery需要的两个参数,CELERY_BROKER_URL 的值告诉Celery 消息队列在哪里运行。CELERY_RESULT_BACKEND 选项只有在你必须要Celery 任务返回存储状态和运行结果的时候才是必须的。
vv/app/__init__.py:
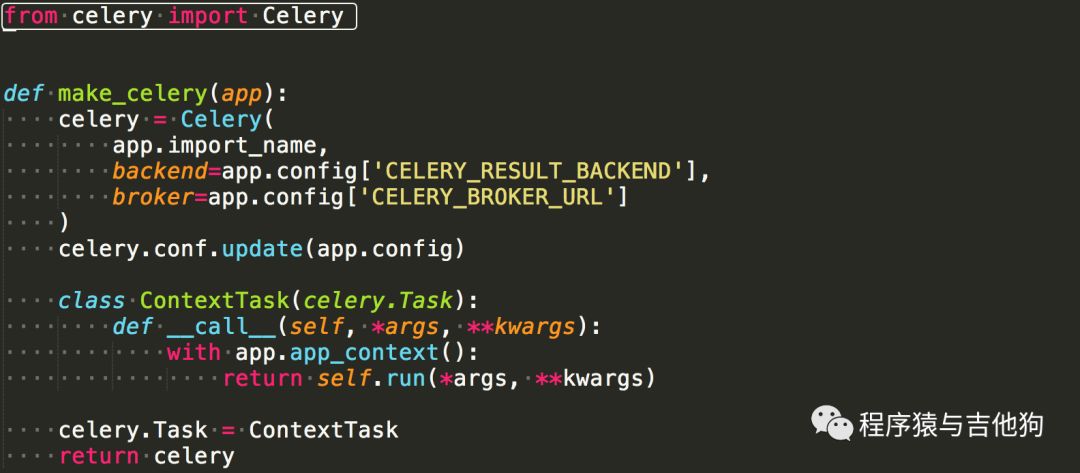
因为我们的使用了工厂函数来创建Flask实例,为了确保celery运行时包含Flask上下文,这里建立一个工厂函数来创建Celery实例。
2.创建后台任务
vv/app/main/tasks.py:
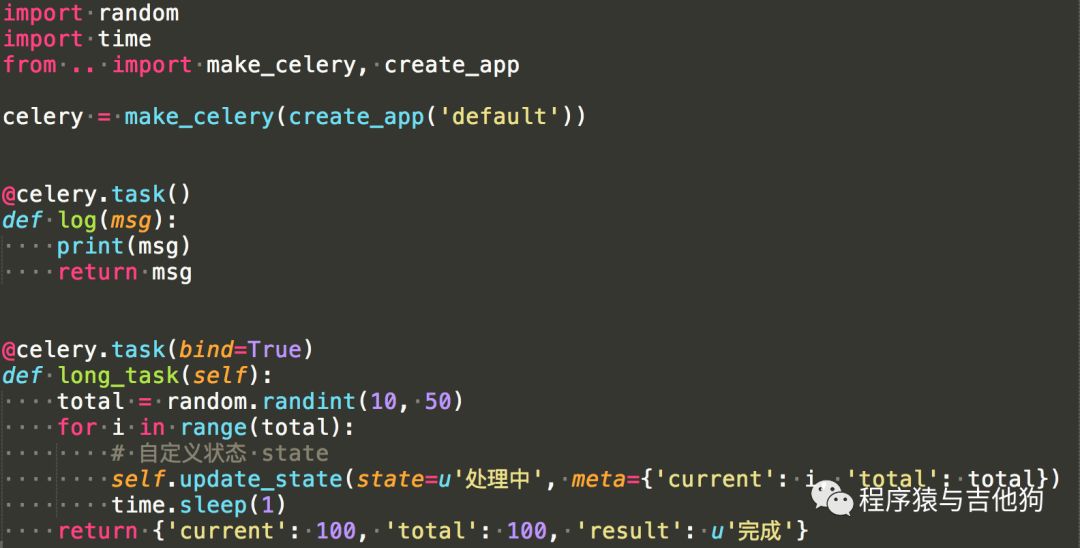
在main文件夹下新建一个tasks.py文件,来存放需要异步执行的耗时任务,首先通过工厂函数make_celery创建Celery实例,后台任务其实就是一个函数,把要执行的动作放入这个函数中,然后使用celery.task这个装饰器来装饰就可以了。这里建立了两个任务,第一个任务很简单,只是打印出传入参数并返回传入参数,第二个任务的装饰器包含了bind参数,表示Celery发送一个self参数到我们的任务,这个参数主要用来使用update_state方法更新当前任务执行状态,update_state方法两个参数,1个state表示当前状态,meta是相关的数据,其实就是一个字典。
3.调用任务
vv/app/main/views.py:

通常在视图函数中,处理业务逻辑时调用后台任务,有两种方法,一种是调用任务的delay方法,直接传入参数即可,一种是调用入伍的apply_async方法,任务的参数通过args传递,countdown是定时任务,表示多少秒以后执行。
通常我们将耗时较长的任务编写成一个函数,然后使用celery.task装饰器将其转化成一个任务对象,最后在视图函数中需要使用的时候调用它的delay或者apply_async方法来执行。
4.状态查看
vv/app/main/views.py:

vv/app/main/views.py:
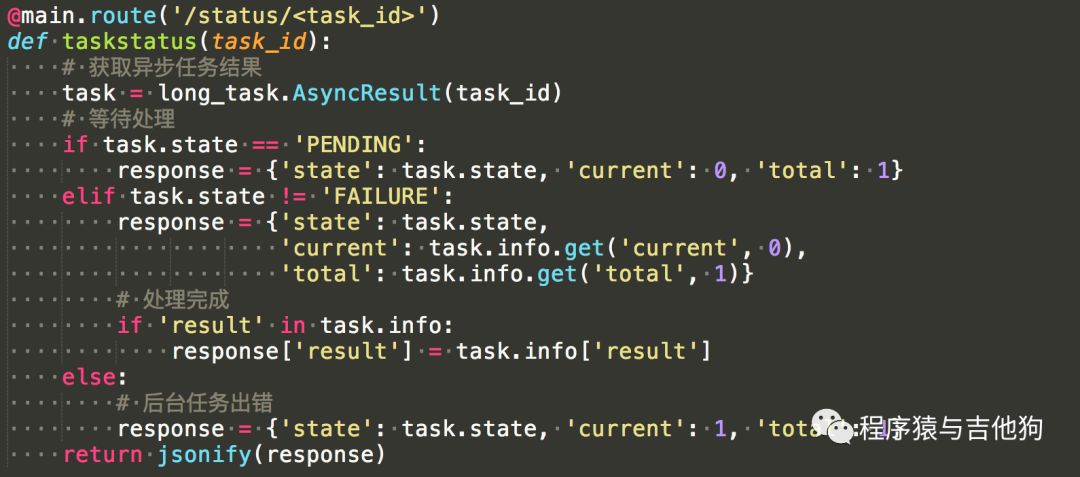
这个就是用来请求任务状态的路由,首先使用task_id找到正在执行的任务。通过task.state可以获取到任务的状态,PENDING表示任务还未开始,通过task.info.get()方法得到前面self.update_state中meta参数的内容。
后端的代码就已经完成了,然后就是前端来获取数据并使用进度条插件实现进度的可视化。
5.前端实现
vv/app/templates/main/index.html
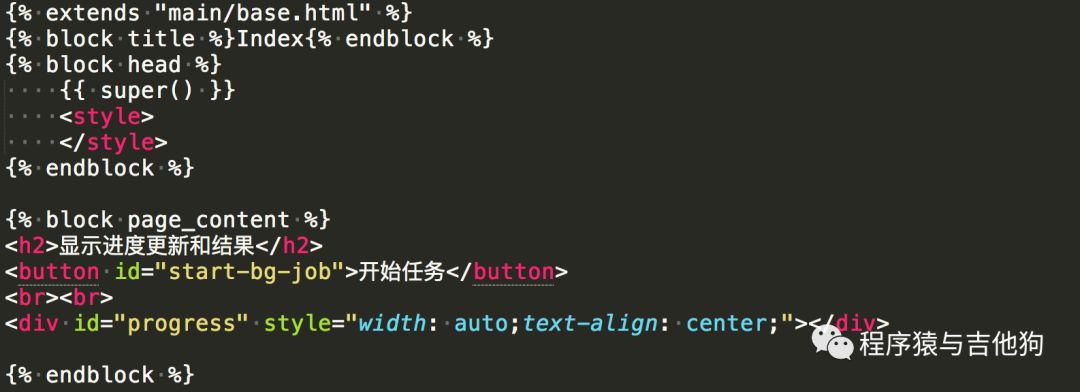
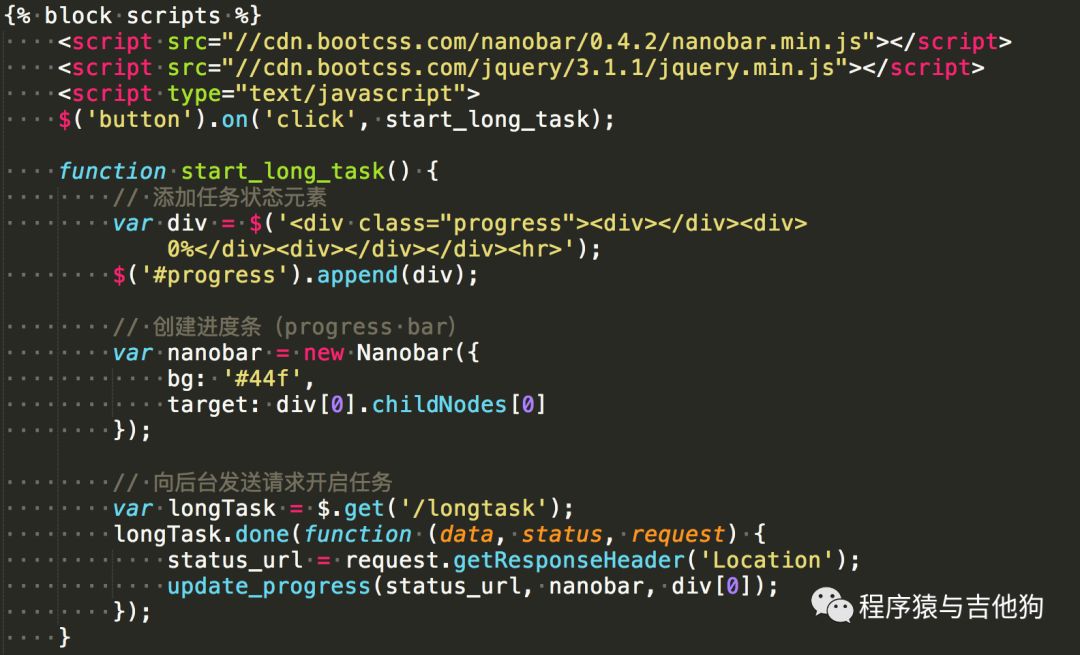
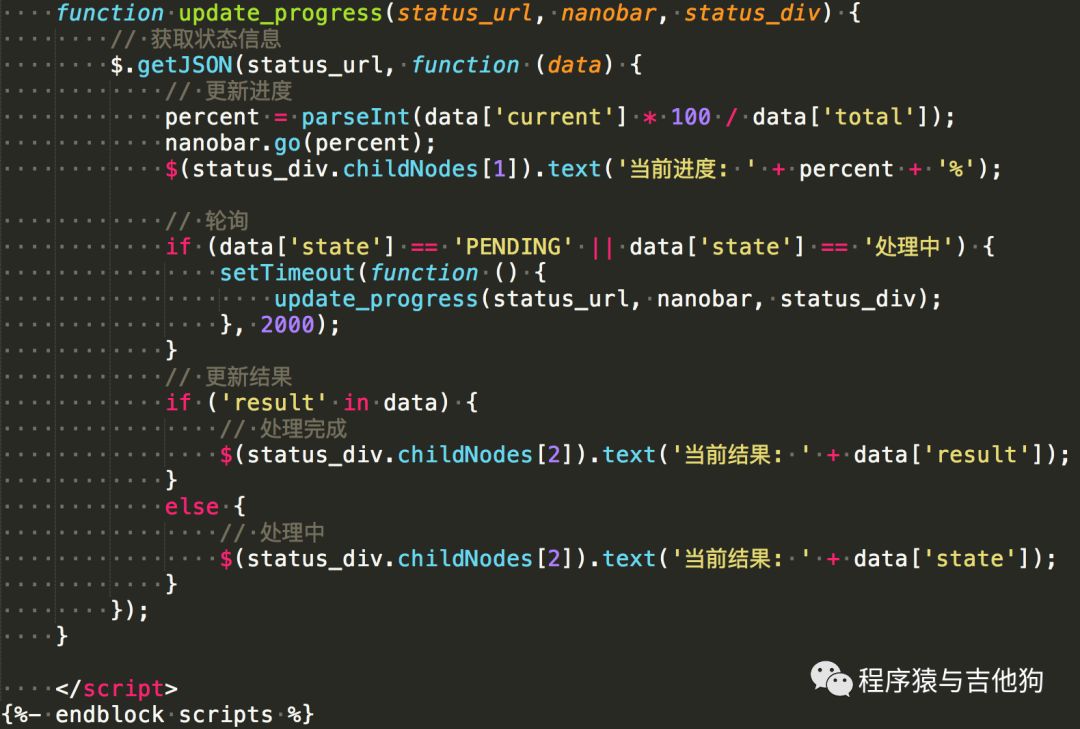
前端使用nanobar.js来显示进度条,定义了两个函数,start_long_task访问/longtask来启动任务,update_progress来更新任务处理进度。
6.启动服务
启动rabbitmq
启动redis
启动Celery
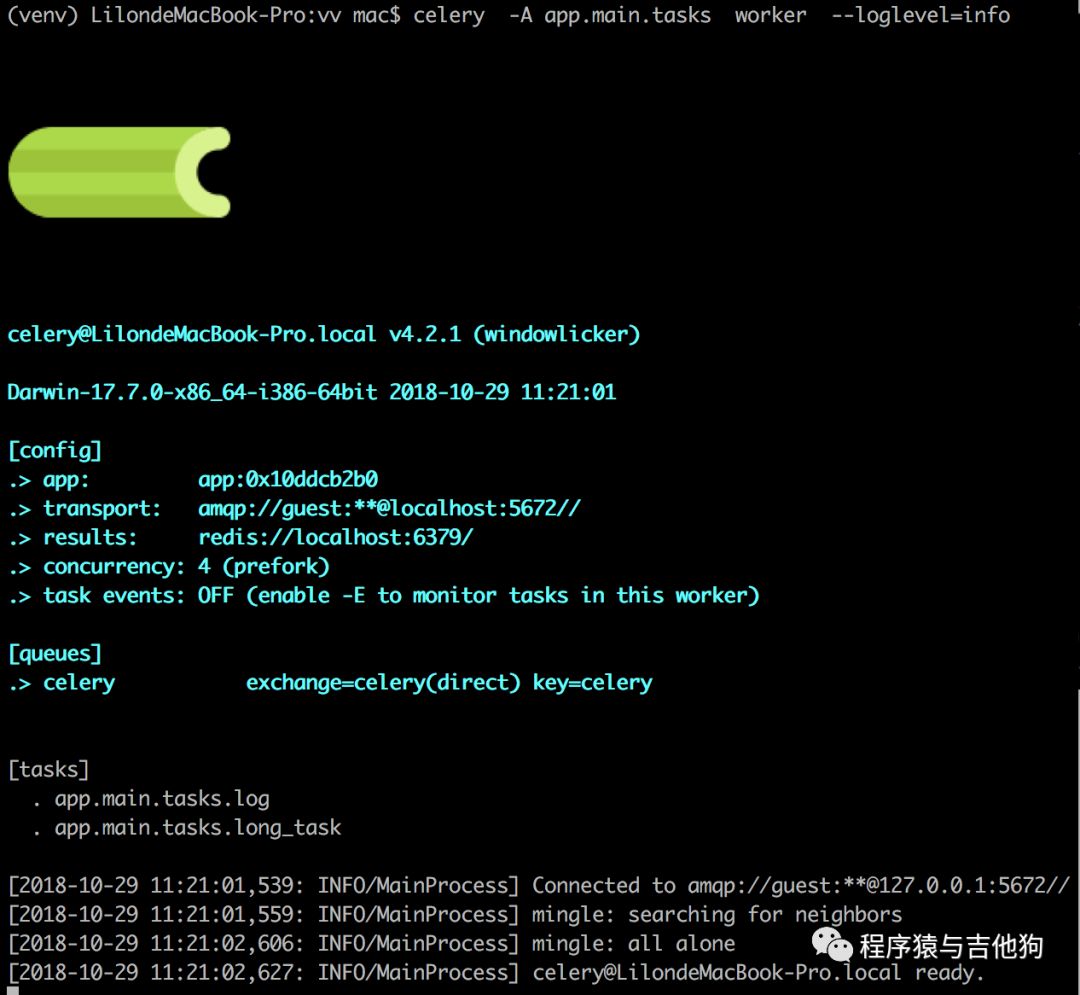
启动Flask
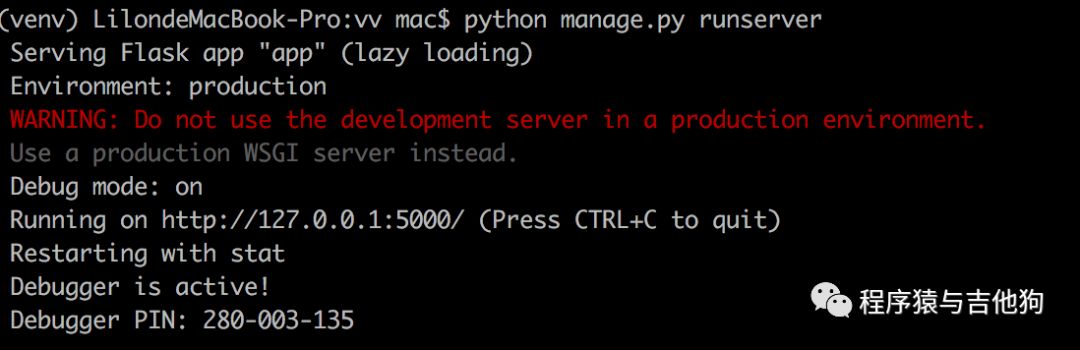
启动浏览器访问http://127.0.0.1:5000/
关于redis和rabbitmq的安装自行搜索,还有很多深度内容,以后的文章再进行介绍,首先跑通整个流程,能够将耗时的任务交给异步任务队列进行处理,来提高网站的访问性能和用户体验。
记得关注并转发
记得关注并转发
记得关注并转发
以上是关于Web开发之旅--Flask使用Celery执行异步任务的主要内容,如果未能解决你的问题,请参考以下文章