吐血整理!基于 Flask 部署 Keras 深度学习模型
Posted 编程派
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了吐血整理!基于 Flask 部署 Keras 深度学习模型相关的知识,希望对你有一定的参考价值。
文 | 风玲儿
出处 | 掘金
本文主要记录在进行
Flask部署过程中所使用的流程,遇到的问题以及相应的解决方案。
1、项目简介
该部分简要介绍一下前一段时间所做的工作:
-
基于深度学习实现一个简单的图像分类问题 -
借助 flask 框架将其部署到 web 应用中 -
并发要求较高
这是第一次进行深度学习模型的 web 应用部署,在整个过程中,进一步折射出以前知识面之窄,在不断的入坑、解坑中实现一版。
2、项目流程
这部分从项目实施的流程入手,记录所做的工作及用到的工具。
2.1 图像分类模型
1. 模型的选择
需要进行图像分类,第一反应是利用较为成熟与经典的分类网络结构,如 VGG 系列(VGG16, VGG19),ResNet 系列(如ResNet50),InceptionV3等。
考虑到是对未知类型的图像进行分类,且没有直接可用的训练数据,因此使用在Imagenet上训练好的预训练模型,基本满足要求。
如果对性能(耗时)要求较为严格,则建议使用深度较浅的网络结构,如VGG16, MobileNet等。
其中,MobileNet网络是为移动端和嵌入式端深度学习应用设计的网络,使得在 cpu 上也能达到理想的速度要求。是一种轻量级的深度网络结构。
MobileNet 由 Google 团队提出,发表于 CVPR-2017,论文标题:《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》
2. 框架选择
-
平时使用
Keras框架比较多,Keras底层库使用Theano或Tensorflow,也称为 Keras 的后端。Keras是在Tensorflow基础上构建的高层 API,比Tensorflow更容易上手。 -
上述提到的分类网络,在
Keras中基本已经实现,Keras 中已经实现的网络结构如下所示:
-
使用方便,直接导入即可,如下:
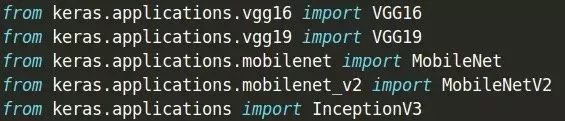
因此,选择 Keras 作为深度学习框架。
3. 代码示例
以Keras框架,VGG16网络为例,进行图像分类。
from keras.models import Model
from keras.applications.vgg16 import VGG16, preprocess_input
import keras.backend.tensorflow_backend as KTF
import tensorflow as tf
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1" #使用GPU
# 按需占用GPU显存
gpu_options = tf.GPUOptions(allow_growth=True)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))
KTF.set_session(sess)
# 构建model
base_model = VGG16(weights=‘imagenet’, include_top=True)
model = Model(inputs=base_model.input,
outputs=base_model.get_layer(layer).output) # 获取指定层的输出值,layer为层名
# 进行预测
img = load_image(img_name, target_size=(224, 224)) # 加载图片并resize成224x224
# 图像预处理
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
feature = model.predict(x) # 提取特征
2.2 模型性能测试
将分类模型跑通后,我们需要测试他们的性能,如耗时、CPU 占用率、内存占用以及 GPU 显存占用率等。
1. 耗时
耗时是为了测试图像进行分类特征提取时所用的时间,包括图像预处理时间和模型预测时间的总和。
# 使用python中的time模块
import time
t0 = time.time()
....
图像处理和特征提取
....
print(time.time()-t0) #耗时,以秒为单位
2. GPU 显存占用
使用英伟达命令行nvidia-smi可以查看显存占用。
3. CPU, MEM 占用
使用top命令或htop命令查看 CPU 占用率以及内存占用率。
内存占用还可以使用free命令来查看:
-
free -h: 加上-h选项,输出结果较为友好,会给出合适单位 -
需要持续观察内存状况时,可以使用
-s选项指定间隔的秒数:free -h -s 3(每隔 3 秒更新一次,停止更新时按下Ctrl+c)
Ubuntu 16.04版本中默认的free版本有 bug,使用-s选项时会报错。
根据以上三个测试结果适时调整所采用的网络结构及显存占用选项。
命令具体含义可参考博文:
Linux 查看 CPU 和内存使用情况[1]
2.3 Redis 使用
Redis=Remote DIctionary Server,是一个由 Salvatore Sanfilippo 写的高性能的key-value存储系统。Redis 是一个开源的使用 ANSI C 语言编写、遵守 BSD 协议、支持网络、可基于内存亦可持久化的日执行、key-value 数据库,并提供多种语言的 API。
Redis支持存储的类型有string, list, set, zset和hash,在处理大规模数据读写的场景下运用比较多。
1. 基本使用
安装 redis
pip install redis
# 测试
import redis
基本介绍
redis.py提供了两个类:Redis,StrictRedis用于实现Redis的命令 StrictRedis用于实现大部分官方命令,并使用官方的语法和命令 Redis是StrictRedis的子类,用于向前兼容redis.py 一般情况下我们就是用StrictRedis。
使用示例
# 1. 导入redis
from redis import StrictRedis
# 2. 连接数据库,指定host,端口号,数据库
r = StrictRedis(host=‘localhost’, port=6379, db=2)
# 3. 存储到redis中
r.set('test1', 'value1') # 单个数据存储
r.set('test2', 'value2')
# 4. 从redis中获取值
r.get('test1')
# 5. 批量操作
r.mset(k1='v1', k2='v2')
r.mset({'k1':'v1', 'k2':'v2'})
r.mget('k1', 'k2')
r.mget(['k1', 'k2'])
2. Redis 存储数组
Redis 是不可以直接存储数组的,如果直接存储数组类型的数值,则获取后的数值类型发生变化,如下,存入 numpy 数组类型,获取后的类型是bytes类型。
import numpy as np
from redis import StrictRedis
r = StrictRedis(host=‘localhost’, port=6379, db=2)
x1 = np.array(([0.2,0.1,0.6],[10.2,4.2,0.9]))
r.set('test1', x1)
>>> True
r.get('test1')
>>> b'[[ 0.2 0.1 0.6]
[10.2 4.2 0.9]]'
type(r.get('test1')) #获取后的数据类型
>>> <class 'bytes'>
为了保持数据存储前后类型一致,在存储数组之前将其序列化,获取数组的时候将其反序列化即可。
借助于 python 的pickle模块进行序列化操作。
import pickle
r.set('test2', pickle.dumps(x1))
>>> True
pickle.loads(r.get('test2'))
>>> array([[ 0.2, 0.1, 0.6],
[10.2, 4.2, 0.9]])
这样,就可以保持数据存入前和取出后的类型一致。
2.4 web 开发框架——Flask
之前学习 python 语言,从来没有关注过
Web开发这一章节,因为工作内容并没有涉及这一部分。如今需要重新看一下。
早期软件主要运行在桌面上,数据库这样的软件运行在服务器端,这种Client/Server模式简称CS架构。随着互联网的兴起,CS架构不适合Web,最大原因是 Web 应用程序的修改和升级非常频繁,CS架构需要每个客户端逐个升级桌面 App,因此,Browser/Server模式开始流行,简称BS架构。
在BS架构下,客户端只需要浏览器,应用程序的逻辑和数据存储在服务器端,浏览器只需要请求服务器,获取 Web 页面,并把 Web 页面展示给用户即可。当前,Web 页面也具有极强的交互性。
Python 的诞生历史比 Web 还要早,由于 Python 是一种解释型的脚本语言,开发效率高,所以非常适合用来做 Web 开发。
Python 有上百个开源的 Web 框架,比较熟知的有Flask, Django。接下来以Flask为例,介绍如何利用 Flask 进行 web 部署。
关于 web 开发框架的介绍,可以参考下面这篇博文:三个目前最火的 Python Web 开发框架,你值得拥有![2]
有关Flask的具体用法可参考其他博文,这方面的资料比较全。下面主要以具体使用示例来说明:
1. 安装使用
-
安装 Flask
pip install flask
import flask # 导入
flask.__version__ # 版本
>>> '1.1.1' #当前版本 -
一个简单的 Flask 示例
Flask 使用 Python 的装饰器在内部自动的把
URL和函数给关联起来。# hello.py
from flask import Flask, request
app = Flask(__name__) #创建Flask类的实例,第一个参数是模块或者包的名称
app.config['JSON_AS_ASCII']=False # 支持中文显示
@app.route('/', methods=['GET', 'POST']) # 使用methods参数处理不同HTTP方法
def home():
return 'Hello, Flask'
if __name__ == '__main__':
app.run()运行该文件,会提示
* Running on http://127.0.0.1:5000/,在浏览器中打开此网址,会自动调用home函数,返回Hello, Flask,则在浏览器页面上就会看到Hello, Flask字样。app.run 的参数
app.run(host="0.0.0.0", port="5000", debug=True, processes=2, threaded=False)注意:绝对不能在生产环境中使用调试器
-
host设定为0.0.0.0,则可以让服务器被公开访问 -
port:指定端口号,默认为5000 -
debug:是否开启 debug 模型,如果你打开 调试模式,那么服务器会在修改应用代码之后自动重启,并且当应用出错时还会提供一个 有用的调试器。 -
processes:线程数量,默认是1 -
threaded:bool类型,是否开启多线程。注:当开启多个进程时,不支持同时开启多线程。 -
使用 route()装饰器来告诉 Flask 触发函数的 URL; -
函数名称被用于生成相关联的 URL。函数最后返回需要在用户浏览器中显示的信息。
2. Flask 响应
视图函数的返回值会自动转换为一个响应对象。如果返回值是一个字符串,那么会被 转换为一个包含作为响应体的字符串、一个 200 OK 出错代码 和一个 text/html 类型的响应对象。如果返回值是一个字典,那么会调用 jsonify() 来产生一个响应。以下是转换的规则:
-
如果视图返回的是一个响应对象,那么就直接返回它。 -
如果返回的是一个字符串,那么根据这个字符串和缺省参数生成一个用于返回的 响应对象。 -
如果返回的是一个字典,那么调用 jsonify 创建一个响应对象。 -
如果返回的是一个元组,那么元组中的项目可以提供额外的信息。元组中必须至少 包含一个项目,且项目应当由 (response, status) 、 (response, headers) 或者 (response, status, headers) 组成。status 的值会重载状态代码, headers 是一个由额外头部值组成的列表 或字典。 -
如果以上都不是,那么 Flask 会假定返回值是一个有效的 WSGI 应用并把它转换为一个响应对象。
JSON 格式的 API
JSON格式的响应是常见的,用 Flask 写这样的 API 是很容易上手的。如果从视图 返回一个 dict ,那么它会被转换为一个 JSON 响应。
@app.route("/me")
def me_api():
user = get_current_user()
return {
"username": user.username,
"theme": user.theme,
"image": url_for("user_image", filename=user.image),
}
如果 dict 还不能满足需求,还需要创建其他类型的 JSON 格式响应,可以使用 jsonify() 函数。该函数会序列化任何支持的 JSON 数据类型。
@app.route("/users")
def users_api():
users = get_all_users()
return jsonify([user.to_json() for user in users])
3. 运行开发服务器
-
通过命令行使用开发服务器
强烈推荐开发时使用 flask 命令行脚本( 命令行接口 ),因为有强大的重载功能,提供了超好的重载体验。基本用法如下:
$ export FLASK_APP=my_application
$ export FLASK_ENV=development
$ flask run这样做开始了开发环境(包括交互调试器和重载器),并在
http://localhost:5000/提供服务。通过使用不同
run参数可以控制服务器的单独功能。例如禁用重载器:$ flask run --no-reload -
通过代码使用开发服务器
另一种方法是通过
Flask.run()方法启动应用,这样立即运行一个本地服务器,与使用flask脚本效果相同。示例:
if __name__ == '__main__':
app.run()通常情况下这样做不错,但是对于开发就不行了。
2.5 使用 Gunicorn
当我们执行上面的app.py时,使用的flask自带的服务器,完成了 web 服务的启动。在生产环境中,flask 自带的服务器,无法满足性能要求,我们这里采用Gunicorn做wsgi容器,来部署flask程序。
Gunicorn(绿色独角兽)是一个Python WSGI UNIX HTTP服务器。从 Ruby 的独角兽(Unicorn )项目移植。该Gunicorn服务器作为wsgi app的容器,能够与各种 Web 框架兼容,实现非常简单,轻量级的资源消耗。Gunicorn 直接用命令启动,不需要编写配置文件,相对 uWSGI 要容易很多。
web 开发中,部署方式大致类似。
1. 安装及使用
pip install gunicorn
如果想让Gunicorn支持异步workers的话需要安装以下三个包:
pip install gevent
pip install eventlet
pip install greenlet
指定进程和端口号,启动服务器:
gunicorn -w 4 -b 127.0.0.1:5001 运行文件名称:Flask程序实例名
以上述 hello.py 文件为例:
gunicorn -w 4 -b 127.0.0.1:5001 hello:app
查看 gunicorn 的具体参数,可执行gunicorn -h 通常将配置参数写入到配置文件中,如gunicorn_conf.py
重要参数:
-
bind: 监听地址和端口 -
workers: worker 进程的数量。建议值:2~4 x (NUM_CORES),缺省值是 1. -
worker_class:worker 进程的工作方式。有:sync(缺省值),eventlet,gevent,gthread,tornado -
threads:工作进程中线程的数量。建议值:2~4 x (SUM_CORES),缺省值是 1. -
reload: 当代码有修改时, 自动重启 workers。适用于开发环境,默认为False -
daemon:应用是否以daemon方式运行,是否以守护进程启动,默认False -
accesslog:访问日志文件路径 -
errorlog:错误日志路径 -
loglevel:日志级别。debug, info, warning, error, critical.
一个参数配置示例:
# gunicorn_conf.py
bind: '0.0.0.0:5000' # 监听地址和端口号
workers = 2 # 进程数
worker_class = 'sync' #工作模式,可选sync, gevent, eventlet, gthread, tornado等
threads = 1 # 指定每个进程的线程数,默认为1
worker_connections = 2000 # 最大客户并发量
timeout = 30 # 超时时间,默认30s
reload = True # 开发模式,代码更新时自动重启
daemon = False # 守护Gunicorn进程,默认False
accesslog = './logs/access.log' # 访问日志文件
errorlog = './logs/error.log'
loglevel = 'debug' # 日志输出等级,debug, info, warning, error, critical
调用命令:
gunicorn -c gunicorn_conf.py hello:app
参数配置文件示例可见:gunicorn/example_config.py at master · benoitc/gunicorn[3]
3、代码示例
#flask_feature.app
import numpy as np
from flask import Flask, jsonify
from keras.models import Model
from keras.applications.vgg16 import VGG16
from keras.backend.tensorflow_backend import set_session
app = Flask(__name__)
app.config['JSON_AS_ASCII']=False
@app.route("/", methods=["GET", "POST"])
def feature():
img_feature = extract()
return jsonify({'result':'true', 'msg':'成功'})
def extract(img_name):
# 图像预处理
img = load_image(img_name, target_size=(feature_params["size"], feature_params["size"]))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
with graph.as_default():
set_session(sess)
res = model.predict(x)
return res
if __name__ == '__main__':
tf_config = some_custom_config
sess = tf.Session(config=tf_config)
set_session(sess)
base_model = VGG16(weights=model_weights, include_top=True)
model = Model(inputs=base_model.input,
outputs=base_model.get_layer(layer).output)
graph = tf.get_default_graph()
app.run()
使用gunicorn启动服务命令:
gunicorn -c gunicorn_conf.py flask_feature:app
4、遇到的问题
在此记录整个部署工作中遇到的问题及对应解决方法。
4.1 Flask 多线程与多进程问题
由于对算法的时间性能要求较高,因此尝试使用 Flask 自带的多线程与多进程选项测试效果。在Flask的app.run()函数中,上面有介绍到processes参数,用于指定开启的多进程数量,threaded参数用于指定是否开启多线程。
flask 开启 debug 模式,启动服务时,dubug 模式会开启一个 tensorflow 的线程,导致调用 tensorflow 的时候,graph 产生了错位。
4.1 Flask 与 Keras 问题
使用 Flask 启动服务的时候,将遇到的问题及参考的资料记录在此。
Q1:Tensor is not an element of this graph
错误信息:
"Tensor Tensor("pooling/Mean:0", shape=(?, 1280), dtype=float32) is not an element of this graph.",
描述:使用Keras中预训练模型进行图像分类特征提取的代码可以正常跑通,当通过Flask来启动服务,访问预测函数时,出现上述错误。
原因:使用了动态图,即在做预测的时候,加载的graph并不是第一次初始化模型时候的Graph,所有里面并没有模型里的参数和节点等信息。
有人给出如下解决方案:
import tensorflow as tf
global graph, model
graph = tf.get_default_graph()
#当需要进行预测的时候
with graph.as_default():
y = model.predict(x)
Q2:使用 Flask 启动服务,加载两次模型,占用两份显存
出现该问题的原因是使用Flask启动服务的时候,开启了 debug 模式,即debug=True。dubug模式会开启一个tensorflow的线程,此时查看 GPU 显存占用情况,会发现有两个进程都占用相同份的显存。
关闭 debug 模型(debug=False)即可。
参考资料:
[1]:Keras + Flask 提供接口服务的坑~~~[4]
4.2 gunicorn 启动服务相关问题
当使用 gunicorn 启动服务的时候,遇到以下问题:
Q1: Failed precondition
具体问题:
2 root error(s) found.
(0) Failed precondition: Error while reading resource variable block5_conv2/kernel from Container: localhost. This could mean that the variable was uninitialized. Not found: Container localhost does not exist. (Could not find resource: localhost/block5_conv2/kernel)
[[{{node block5_conv2/convolution/ReadVariableOp}}]]
[[fc2/Relu/_7]]
(1) Failed precondition: Error while reading resource variable block5_conv2/kernel from Container: localhost. This could mean that the variable was uninitialized. Not found: Container localhost does not exist. (Could not find resource: localhost/block5_conv2/kernel)
[[{{node block5_conv2/convolution/ReadVariableOp}}]]
0 successful operations.
0 derived errors ignored."
解决方法:
通过创建用于加载模型的会话的引用,然后在每个需要使用的请求中使用 keras 设置 session。具体如下:
from tensorflow.python.keras.backend import set_session
from tensorflow.python.keras.models import load_model
tf_config = some_custom_config
sess = tf.Session(config=tf_config)
graph = tf.get_default_graph()
# IMPORTANT: models have to be loaded AFTER SETTING THE SESSION for keras!
# Otherwise, their weights will be unavailable in the threads after the session there has been set
set_session(sess)
model = load_model(...)
# 在每一个request中:
global sess
global graph
with graph.as_default():
set_session(sess)
model.predict(...)
有网友分析原因:tensorflow的graph和session不是线程安全的,默认每个线程创建一个新的session(不包含之前已经加载的 weights, models 等)。因此,通过保存包含所有模型的全局会话并将其设置为在每个线程中由keras使用,可以解决问题。
有网友提取一种改进方式:
# on thread 1
session = tf.Session(graph=tf.Graph())
with session.graph.as_default():
k.backend.set_session(session)
model = k.models.load_model(filepath)
# on thread 2
with session.graph.as_default():
k.backend.set_session(session)
model.predict(x, **kwargs)
这里的新颖性允许(一次)加载多个模型并在多个线程中使用。默认情况下,加载模型时使用“默认”Session和“默认”graph。但是在这里是创建新的。还要注意,Graph存储在Session对象中,这样更加方便。
测试了一下好像不行
Q2:无法启动服务,CRITICAL WORKER TIMEOUT
当使用 gunicorn 启动 flask 服务时,查看服务器状态和日志文件发现一直在尝试启动,但是一直没有成功。
CRITICAL WORKER TIMEOUT
这是 gunicorn 配置参数timeout导致的。默认值为30s,即超过 30s,就会 kill 掉进程,然后重新启动restart。
当启动服务进行初始化的时间超过 timeout 值时,就会一直启动,kill, restart。
可根据具体情况,适当增加该值。
参考资料:
tensorflow - GCP ML-engine FailedPreconditionError (code: 2) - Stack Overflow[5]
参考资料
Linux查看CPU和内存使用情况: https://www.cnblogs.com/mengchunchen/p/9669704.html
[2]三个目前最火的Python Web开发框架,你值得拥有!: https://yq.aliyun.com/articles/700673
[3]gunicorn/example_config.py at master · benoitc/gunicorn: https://github.com/benoitc/gunicorn/blob/master/examples/example_config.py
[4]1]:[Keras + Flask 提供接口服务的坑~~~: https://www.cnblogs.com/svenwu/p/10189557.html
[5]tensorflow - GCP ML-engine FailedPreconditionError (code: 2) - Stack Overflow: https://stackoverflow.com/questions/55632876/gcp-ml-engine-failedpreconditionerror-code-2
回复下方「关键词」,获取优质资源
回复关键词「 pybook03」,立即获取主页君与小伙伴一起翻译的《Think Python 2e》电子版
回复关键词「入门资料」,立即获取主页君整理的 10 本 Python 入门书的电子版
回复关键词「m」,立即获取Python精选优质文章合集
回复关键词「book 数字」,将数字替换成 0 及以上数字,有惊喜好礼哦~
推荐阅读
题图:pexels,CC0 授权。
以上是关于吐血整理!基于 Flask 部署 Keras 深度学习模型的主要内容,如果未能解决你的问题,请参考以下文章
AI常用框架和工具丨11. 基于TensorFlow(Keras)+Flask部署MNIST手写数字识别至本地web
AI常用框架和工具丨11. 基于TensorFlow(Keras)+Flask部署MNIST手写数字识别至本地web
AI常用框架和工具丨11. 基于TensorFlow(Keras)+Flask部署MNIST手写数字识别至本地web
教程 | 如何使用 Kubernetes 轻松部署深度学习模型