Django使用S3服务
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Django使用S3服务相关的知识,希望对你有一定的参考价值。
参考技术Astatic静态文件和media多媒体(多为用户上传)需要分目录存储,新建s3utils.py文件:
settings.py添加S3配置:
因为S3开放了本机访问权限,因为不需要认证。
需要认证的添加 KEY_ID 和ACCESS_KEY:
运行 collectstaticDjango管理命令 :
静态文件应该以 http://horoscope-cxclient.s3.amazonaws.com/static/ 为结尾。
任何上传的文件FileField或ImageField模型上的属性都应该在 http://horoscope-cxclient.s3.amazonaws.com/media/ 中。如果这些模型属性指定upload_to路径,则存储于 /media/*** 。
如上配置配置成功后,资源访问域名是 https://horoscope-cxclient.s3.amazonaws.com/media/
发现资源加载速度慢了很多,17K耗时将近两秒,而且不同区域访问不稳定。
此时就应该祭出CDN了 知乎CDN
CDN HOST: http://***.cloudfront.net/ ,解析至 http://static.mobileapp666.com 域名下,settings配置:
重启后资源通过 http://static.mobileapp666.com/** 访问,速度有了明显的提高。
AWS_S3_SECURE_URLS: 是否启动安全网址,即是否使用 https , 默认为True,因为https需要申请证书等等一系列处理,暂时设置为False后将使用 http 协议。
使用 staticfiles
常用命令:
上传目录 需要添加参数 --recursive
AWS CLI命令参考: AWS CLI Command Reference
参考:
django-s3-temporary
cname-support-aws_s3_custom_domain-doesnt
django-wont-serve-static-files-from-amazon-s3-with-custom-domain
Using-Amazon-S3-to-store-your-Django-sites-static-and-media-files
django
---恢复内容开始---
首先了解web应用
一.
web应用是通过web访问的应用程序,程序的最大好处是用户很容易访问应用程序,用户只需要一个浏览器,应用程序分为两种 C/S B/S ,c/s是客户端/服务器程序,这类程序一般独立运行, b/s 是浏览器/服务器端应用程序,,浏览器是一个socket客户端,服务器是一个socket服务端
web应用小程序


1 import socket 2 3 def handle_request(client): 4 #5.接收浏览器的信息,1024字节接收 5 request_data = client.recv(1024) 6 print("request_data: ",request_data) 7 # 5.发送响应协议 8 client.send("HTTP/1.1 200 OK status: 200 Content-Type:text/html ".encode("utf8")) 9 # 6.发送数据至浏览器(客户端) 10 client.send("<h1>Hello, luffycity!</h1><img src=‘‘>".encode("utf8")) 11 12 def main(): 13 # 1.创建socket对象 socket.socket() 14 sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) 15 # 2.绑定ip端口 16 sock.bind((‘localhost‘,8812)) 17 # 3.限制次数 18 sock.listen(5) 19 20 while True: 21 print("the server is waiting for client-connection....") 22 # 4.connection 相当于连接的那把伞,地址 23 connection, address = sock.accept() 24 handle_request(connection) 25 connection.close() 26 27 if __name__ == ‘__main__‘: 28 29 main()
关于响应协议:
请求协议
浏览器-------------------> 服务器
<-------------------
响应协议
由服务端发送给浏览器的一种特殊协议,双方规定好的,
格式:
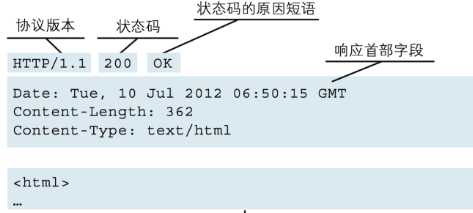
响应首行
HTTP/1.1 200 OK
协议/版本号/状态码/状态码译文
响应头
status: 200 Content-Type:text/html
键值对 用 区分开
响应体
<h1>Hello, luffycity!</h1>
主要内容 有 区分
了解http协议
二.
http是用于万维网(WWW:World Wide Web )服务器与本地浏览器之间传输超文本的传送协议。
HTTP 协议特性
1.基于TCP/IP:
http协议是基于TCP/IP协议之上的应用层协议。
2.基于请求-响应模式:
HTTP协议规定,请求从客户端发出,最后服务器端响应该请求并 返回。换句话说,肯定是先从客户端开始建立通信的,服务器端在没有 接收到请求之前不会发送响应
3.无状态保存
比如打开一个网页的时候,协议会稍微停留几秒钟,方便快速进行下次访问
4.无连接
无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
请求协议
get与post请求方法不同
-
GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditBook?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的请求体中.
-
GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制.
-
GET与POST请求在服务端获取请求数据方式不同。

响应协议:
关于web框架
三
wsgiref模块
最简单的web应用是把html用文件保存好,用一个现成的http服务器软件,接受用户的请求,从文件读取html,返回,要生成动态的html文件,需要把上述步骤自己实现,太麻烦了,需要自己去写,TCP连接(socket模块),解析http请求(接收来自http的协议),发送htto响应(发送响应协议),浏览器和服务器是通过http协议进行通信的,需要一个接口协议实现服务器软件,这个接口就是wsgi,而wsgiref就是python基于wsgi协议开发的服务模块
1 from wsgiref.simple_server import make_server 2 3 def application(environ, start_response): 4 """ 5 6 :param environ: 请求信息字典 7 :param start_response: 封装响应格式的 8 :return: 9 """ 10 print("environ",environ) 11 print("PATH_INFO",environ.get("PATH_INFO")) 12 start_response(‘200 OK‘, [(‘Content-Type‘, ‘text/html‘),("k1","v1")]) 13 return [b‘<h1>Hello, web!</h1>‘] 14 15 16 httpd = make_server(‘‘, 8080, application) 17 18 print(‘Serving HTTP on port 8080...‘) 19 # 开始监听HTTP请求: 20 httpd.serve_forever()
environ: 将http协议的各种请求以字典的的形式返回,直接取字典的键值对,
关于web框架的小小小项目
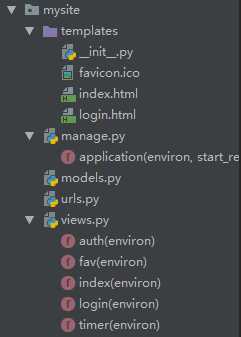
web项目中,templates是用来存放html文件的文件夹
manage.py是用来通过wsgief模块,进行动态的http协议交互
1 # 引入wsgi模块 2 from wsgiref.simple_server import make_server 3 4 from urls import urlpattens 5 6 def application(environ, start_response): 7 8 print("environ",environ) 9 print("PATH_INFO",environ.get("PATH_INFO")) 10 path=environ.get("PATH_INFO") 11 data=b"" 12 13 14 # 方案1 15 # if path=="/login": 16 # data=login(environ) 17 # elif path=="/auth": 18 # data=auth(environ) 19 20 # 方案2 21 func=None 22 # 2.1遍历取到的路径 如("/timer", timer),如果path=/time func为timer 23 for item in urlpattens: 24 print("------>",item[0]) 25 if item[0]==path: 26 func=item[1] 27 break 28 # 2.2 如果func为空,data= 404 如果不为空,执行timer(environ)函数 29 if not func: 30 data=b"<h1>404</h1>" 31 else: 32 data = func(environ) 33 34 start_response(‘200 OK‘, [(‘Content-Type‘, ‘text/html‘)]) 35 # 3.给浏览器返回 36 return [data] 37 38 39 httpd = make_server(‘‘, 8088, application) 40 41 print(‘Serving HTTP on port 8088...‘) 42 # 开始监听HTTP请求: 43 httpd.serve_forever()
models.py 是用来与数据库打交道的
1 # 创建表结构 2 3 import pymysql 4 #连接数据库 5 conn = pymysql.connect(host=‘127.0.0.1‘,port= 3306,user = ‘root‘,passwd=‘‘,db=‘web‘) #db:库名 6 #创建游标 7 cur = conn.cursor() 8 9 sql=‘‘‘ 10 create table userinfo( 11 id INT PRIMARY KEY , 12 name VARCHAR(32) , 13 password VARCHAR(32) 14 ) 15 16 ‘‘‘ 17 18 cur.execute(sql) 19 20 #提交 21 conn.commit() 22 #关闭指针对象 23 cur.close() 24 #关闭连接对象 25 conn.close()
urls.py 是用来进行对views.py导入的,用来存放访问的请求转到manage,在找到相应的关系执行函数
1 # url与视图函数的映射关系 2 from views import login,auth,fav,index,timer 3 4 urlpattens = [ 5 ("/timer", timer), 6 ("/login", login), 7 ("/auth", auth), 8 ("/favicon.ico", fav), 9 ("/", index), 10 ]
views.py 是用来进行对浏览器端返回的信息进行函数的方法结果返回给manage,最后返回到浏览器
1 from urllib.parse import parse_qs 2 3 def login(environ): 4 with open("templates/login.html", "rb") as f: 5 data = f.read() 6 7 return data 8 9 def auth(environ): 10 # 登录认证 11 12 # 1 获取用户输入的用户名和密码 13 # 1.1获取接受的字节数 14 request_body_size = int(environ.get(‘CONTENT_LENGTH‘, 0)) 15 print("request_body_size", request_body_size) # 17 16 # 1.2 按照字节数获取 17 request_body = environ[‘wsgi.input‘].read(request_body_size) # b‘user=alex&pwd=123‘ 18 # 1.3 将账号密码装换成字典的形式 19 reqeust_data = parse_qs(request_body) # {b‘user‘: [b‘alex‘], b‘pwd‘: [b‘123‘]} 20 # 1.4 用get取出字典,转换成字符串 21 user = (reqeust_data.get(b"user")[0]).decode("utf8") 22 pwd = (reqeust_data.get(b"pwd")[0]).decode("utf8") 23 print("====>", user, pwd) 24 25 # 2 去数据库做校验,查看提交用户是否合法 26 # 连接数据库 27 import pymysql 28 conn = pymysql.connect(host=‘127.0.0.1‘, port=3306, user=‘root‘, passwd=‘‘, db=‘web‘) # db:库名 29 # 创建游标 30 cur = conn.cursor() 31 SQL = "select * from userinfo WHERE NAME =‘%s‘ AND PASSWORD =‘%s‘" % (user, pwd) 32 cur.execute(SQL) 33 # print("cur.fetchone:",cur.fetchone()) # (1, ‘alex‘, ‘123‘) 34 if cur.fetchone(): 35 # 验证成功 36 data = "登录成功!".encode("gbk") 37 else: 38 # 验证失败 39 data = "登录失败!".encode("gbk") 40 41 return data 42 43 44 def fav(environ): 45 46 with open("templates/favicon.ico","rb") as f: 47 data=f.read() 48 49 return data 50 51 52 def index(environ): 53 54 with open("templates/index.html", "rb") as f: 55 data = f.read() 56 57 return data 58 59 def timer(environ): 60 61 import datetime 62 now=datetime.datetime.now() 63 64 return str(now).encode("utf8")
---恢复内容结束---
以上是关于Django使用S3服务的主要内容,如果未能解决你的问题,请参考以下文章
设置 Django 以提供来自 Amazon S3 的媒体文件
使用 AWS S3 for django 在 heroku 上提供静态文件?