rand()随机函数产生的值的范围?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了rand()随机函数产生的值的范围?相关的知识,希望对你有一定的参考价值。
参考技术Acplusplus中有这样的介绍:
rand函数产生一个0到RAND_MAX的伪随机数,这里的RAND_MAX因不同的实现而异,但RAND_MAX至少为32767。(比如,MSVC中通常为0x7fff,即32767,而Linux平台下GCC中RAND_MAX通常会远远大于这个值)
有一些其他编程语言的rand函数确实是产生一个[0.0, 1.0)之间的浮点数。比如MATLAB。
在C中,rand() % 32会产生一个[0, 32)之间的伪随机数,那么rand() % 32 + 1的取值区间实际上是[1, 33)。
要产生[0, 32)(开区间)之间伪随机数:rand() % 32即可。

扩展资料:
注意:如果要使用函数RAND()生成一随机数,并且使之不随单元格计算而改变,可以在编辑栏中输入“=RAND()”,保持编辑状态,然后按F9,将公式永久性地改为随机数。
不过,这样只能一个一个的永久性更改,如果数字比较多,也可以全部选择之后,另外选择一个合适的位置粘贴,粘贴的方法是点击右键,选择“选择性粘贴”,然后选择“数值”,即可将之前复制的随机数公式产生的数值(而不是公式)复制下来。
参考资料来源:百度百科-随机函数
报错注入
报错注入

1,rand()函数可以产生0~1随机数。
rand()函数产生的随机数是0~1,floor函数向下取整,取到的值是固定的“0”,
rand()*2,floor函数取到的值是不固定的“0”或"1"
floor(x)函数向下取整,即取不超过x的最大整数。
rand(0)*2将取0~2中的随机数
floor(rand()*2)记录显示两条就报错
floor(rand(0)*2)记录显示三条一上,且三条以上必报错。
group by对数据进行分组。
详细步骤:
我们先查询数据库
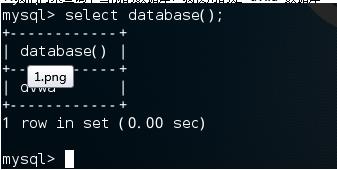
select database();
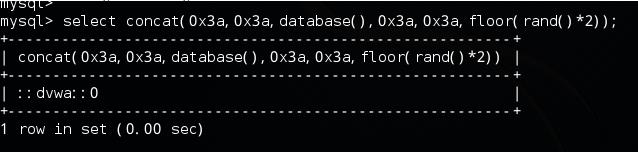
select concat(database(),floor(rand()*2));
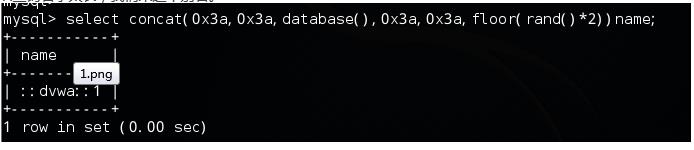
查询名字太长,取个别名为name
select concat(database(),floor(rand()*2))name;
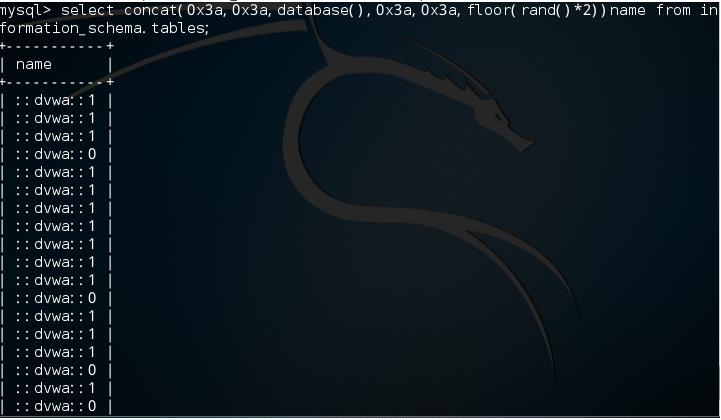
我们查询information.schema.tables表中有多少表格,多少列
select concat(database(),floor(rand()*2))name from information.schema.tables;
我们用group by分组
select concat(database(),floor(rand()*2))name from information.schema.tables group by name;
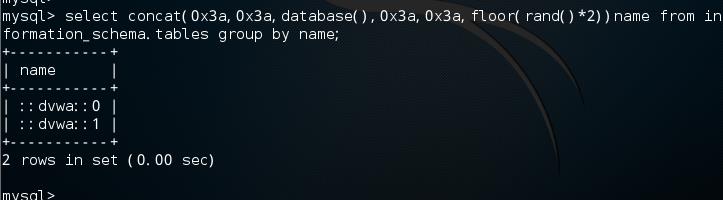
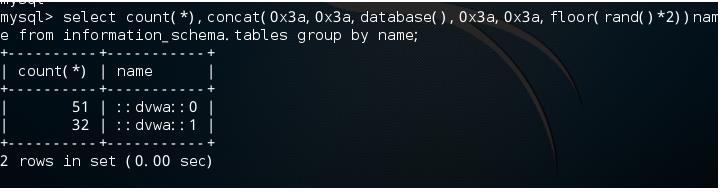
我们用count()函数进行统计
select count(*) , concat(database(),floor(rand()*2)name from information_schema.tables group by name;

以上是关于rand()随机函数产生的值的范围?的主要内容,如果未能解决你的问题,请参考以下文章