二代测序文库构建-概述与挑战(1)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了二代测序文库构建-概述与挑战(1)相关的知识,希望对你有一定的参考价值。
参考技术A高通量测序又称NGS,重新定义了基因组学研究。近年来,NGS技术稳步发展,伴随着成本下降以及测序应用呈指数增加。本文,我们研究了影响测序文库质量的关键因素,以及,在DNA来源和RNA来源文库准备过程中存在的挑战。这些因素包括,DNA/RNA材料的定量和物理性质以及潜在应用(比如,基因组测序、靶向测序、RNA-seq、ChIP-seq、RIP-seq和甲基化),在制备高质量测序文库的内容中将提到。另外,我们也会讨论制备单细胞来源的文库的方法。
在过去的5年里,NGS技术在生命科学领域的研究人员中得到了广泛应用。与此同时,随着测序技术的发展和进步,衍生了一些核酸提取和文库制备的方法。比如,已经可以成功利用来自单细胞的RNA和DNA进行文库的制备. NGS文库制备的基础是将靶向的核酸、RNA或DNA 改造成测序仪可以使用的形式(Fig 1)。在这儿,我们对比了多个文库制备策略以及NGS应用,主要着眼于与illumina测序技术兼容的文库。但是,需要指出一点,本文讨论的几乎所有原则只要稍加修饰便可应用于其他NGS平台,比如,Life Technologies、Roche和Pacific Biosciences。
一般来说,文库制备的核心步骤包括:1)片段化及或选出特定长度的片段,2)将其转化为双链的形式,3)将寡核苷酸接头连接至片段末尾以及4)对文库进行定量;目标DNA片段的大小是NGS文库构建的关键因素。对核酸进行片段化的方法主要包括物理、酶切和化学的方法。物理方法包括声波剪切(代表:Covaris)和超声(代表:BioRuptor),酶切方法包括非特异性内切酶和转座酶片段化;我们实验室中,Covaris, Woburn, MA主要用于获得100-5000bp范围的DNA片段,而Covaris g-TUBEs主要用于mate-pair文库所必需的6-20kb范围的DNA片段。酶切的方法包括DNase I或片段化酶的消化,一个两种酶的混合(New England Biolabs, Ipswich MA)。两种方法都很有效。但是,片段化酶相比物理方法会产生更多的假indel。另一种酶切方法是Illumina的Nextera,利用转座酶进行随机片段化并把接头序列插入双链DNA中。 这种方法有几个优势,包括,减少样品处理和制备的时间。
文库大小是由插入片段(指的是接头序列之间的文库部分)大小决定的,因为接头序列的长度是不变的。反过来说,最佳插入片段长度是有NGS设备以及特定测序应用决定的。比如, illumina中,最佳片段大小是受簇生成过程影响的,这个过程包括,文库编写、稀释以及分布至芯片表面进行扩增。虽然,短片段扩增更加有效,长片段文库能够产生更大、更弥散的簇。我们用illumina测序的文库最大为1500bp。
最佳文库大小也是由测序应用决定的。对于外显子测序来说,80%以上的人类外显子长度小于200bp。我们测试PE100bp,外显子文库大小约为250bp,这样可以匹配大多数外显子的平均大小,结果中没有重叠的读对。 RNA-seq文库大小也是由应用决定的。对于基因表达分析我们采用SE100的测序。但是对于,可变剪切或转录起始终止位点的判定,我们选择PE100的方案。大多数应用中,RNA在片段化之前会逆转录成cDNA的形式。一般是利用二价金属离子(镁或锌)对RNA进行可控的热消化。文库片段大小可以通过调节消化反应的时间来控制,重复性很好。
在最近对7个RNA-seq文库制备方法的研究中,大多是先对RNA进行片段化然后进行加接头。有两种方法,不利用随机引物,或者说在SMARTer Ultra Low RNA试剂盒中, 合成具有固定3\',5\'序列的全长cDNA序列。 全长的cDNA文库(平均2kb)可以通过长距离PCR(LD-PCR)进行扩增。这种扩增的双链cDNA再通过声波剪切至合适的长度,用在标准的illumina文库准备过程中(包括,末端修复和补平,加A和接头连接,再通过PCR进行扩增。)
另一种文库构建后对文库大小处理步骤是片选以及去除接头二聚体或其他文库制备的副产物。接头二聚体是接头自连的结果。这些二聚体成簇效率非常高,而且会消耗掉珍贵的芯片空间,但不产出任何有效数据。因此,我们通常利用磁珠法或切胶回收。磁珠法适用于起始材料比较充足的情况。若样本投入有限,就会生成更多的接头二聚体。我们的经验是,磁珠为基础的方法在这种情况下不适用,需要结合磁珠和切胶回收的方法。
在microRNA/small RNA文库制备过程中,目的产物通常只比120bp的接头二聚体长20-30bp。因此,必须使用切胶回收的方法获得尽可能多的目的序列。这种分离精度对于磁珠来说就不适用。另外,我们经常需要建大插入片段(1kb)的文库,结合更长的读长PE300以及无PCR步骤,用于细菌基因组的从头组装。为了尽可能获得可用于组装的数据,就必须要小心地进行切胶回收以获得大小较为一致的插入片段。
在利用DNA样本进行文库构建过程中有几个考虑,包括起始材料的量以及该文库是用于重测序(有可用于比对的参考序列)还是从头测序(需要利用此次下机数据组装出新的参考序列)。文库制备容易存在bias,这是由于基因组存在高GC或低GC的区域,目前已经开发了解决这些问题的方法,包括仔细选择用于扩增的聚合酶、循环数、条件以及缓冲液等。
DNA样本的文库制备,不管是用于WGS、WES、ChIP-seq还是PCR扩增子,一般都遵循相同的流程。总的来说,对于任何应用,目标都是使文库尽可能的复杂。
DNA建库试剂盒目前有多个品牌。竞争也促使价格迅速下降以及质量的提升。这些试剂盒能够处理DNA起始量从ug到pg多个级别。但是,我们需要记住一点,起始量大可以降低扩增循环数,因此文库复杂度更高。除Nextera外,文库制备步骤通常包括:1)片段化,2)末端修复,3)5端磷酸化,4)3端加A,5)接头连接,6)几个cycle的PCR以富集加了接头的产物。Ion Torrent流程的主要不同在于平末端连接不同的接头序列。
起始DNA被片段化后,会使用3个酶的混合物( T4 多聚核苷酸激酶、T4 DNA聚合酶以及 Klenow大片段 )进行末端补平和5端磷酸化。3端加A尾利用Taq聚合酶或Klenow片段(exo-)。Taq在加A尾上更有效率,但Klenow在不能用加热方法时,比如mate-pair文库可以适用。在接头连接过程中,最适的接头:片段比例大约为10:1,以摩尔数为单位。接头太多会形成难以分离的二聚体,这些二聚体在随后的扩增中会占主导地位。末端修复和加A反应后,磁珠或胶回收的方法都适用,但连接反应后我们发现,磁珠的方法能够更有效地去除接头二聚体。
为了便于多样本混合,可以对不同样本使用不同barcode的接头。另外barcode也可以由PCR扩增过程经不同barcode的引物加入。可以从多个供货商购买高质量的带barcode的接头和PCR引物。 目前DNA文库构建的所有组分,从接头到酶,都有详细的文字说明,可以组装成自制的文库制备试剂盒。
另一种方法是Nextera方法,利用转座酶对DNA进行随机打断,并在一个单管中对其加标签(又称tagmentation)。这种工程化的酶有两个功能,对DNA进行片段化,并将特定的接头加到片段化DNA的两端。 这些接头序列在接下来的PCR过程中用于扩增插入片段。PCR反应会加入barcode。这个制备过程相对传统方法的优势在于,将片段化、末端修复和接头连接合并成一步。这种方法相对于机械片段化的方法来说,对DNA的起始量更加敏感。为了实现在合适的距离进行片段化,转座酶相对样本的比例非常关键。因为片段大小依赖于反应效率,所有反应的参数,比如,温度和反应时间,都非常关键,需要严格控制。
一些课题组发表了对单个细胞基因组进行测序的结果。现在的策略采用多重链置换(MDA)对整个基因组进行扩增。MDA主要是利用了随机引物和phi29,一种高度进行性的链置换聚合酶。虽然这个技术能够产生足够的量用于测序文库的构建 ,但它的一个问题在于非线性扩增造成的大量的bias。最近有研究认为通过加入一个半线性的预扩增步骤能够减少bias。Fluidgm基于单细胞分离和微流控技术用于单细胞文库制备,每次运行可获得最多96个单细胞。
对于RNA文库,我们需要根据测序目的来进行文库构建方案的筛选。如果目的是发现复杂全面的转录事件,文库需要覆盖整个转录组,包括,编码、非编码、反义以及基因间RNA,而且需要尽可能的完整。但是,很多场合,目的只是研究能够翻译成蛋白质的编码mRNA的转录本。另一种情况只涉及small RNA,大多miRNA,也包括snoRNA,piRNA,snRNA以及tRNA。虽然,我们想要详述RNA测序文库的原则,但无法一一列举。感兴趣的读者可以自行研究。
NGS应用到RNA-seq最初成功的例子之一是 miRNA 。制备miRNA测序文库非常简单,通常是一步反应。事实上,miRNA在5端有天然磷酸修饰,这允许连接酶选择性地靶向miRNA。
illumina步骤的第一步,3端阻断,5端腺苷化的DNA接头通过截断的T4 RNA连接酶2被连接至RNA样本。这个酶经过修饰,能够对3端接头底物进行腺苷化。结果是,其他RNA片段在这个反应中不会连接在一起。只有腺苷化的寡核苷酸可以连接到游离的RNA的3端末端。由于接头3端是阻断的,无法进行自连。下一步,在ATP和RNA连接酶1的作用下加入5端RNA接头。 只有5端磷酸化的RNA分子能够在连接反应中作为有效的底物。第二步连接反应后,逆转录引物杂交到3端接头,开始启动RT-PCR 扩增(一般是12个循环)。由于小且片段大小可预测(120bp 接头序列加上20-30bp miRNA插入片段),文库或多个barcode混合样本通常一起进行切胶回收。 由于存在接头二聚体以及非miRNA的连接(tRNA和snoRNA),切胶回收非常重要。这种文库制备方法导致文库的测序具有方向性,总是从原始RNA的5端到3端。Ion Torrent 的miRNA测序原则也是相似的。Ion Torrent利用两种不同的接头连接至miRNA 3端和5端,随后进行RT-PCR。一般,文库构建步骤可以将任何RNA材料构建成有方向性的RNA-seq文库。
miRNA文库的一大限制在于RNA的起始量低(<200ng 总RNA);短接头二聚体在RT-PCR反应中与目的产物、接头和miRNA进行竞争。 当存在太多二聚体时,他们会在片段筛选时充斥整个凝胶,污染产物条带。为了尽量避免这种情况,很多试剂盒采取了各种方式来避免二聚体的形成。
对于mRNA测序文库,方法主要包括利用随机引物或oligo-dT引物进行cDNA合成或在mRNA片段上加接头后进行某种形式的扩增。mRNA可以由随机引物或oligo-dT起始产生一链cDNA。如果使用随机引物,必须先将rRNA去除或减少。rRNA可以通过寡核苷酸探针为基础的试剂,比如,Ribo-Zero和RiboMinus,进行去除。另外,polyA RNA可以通过oligo-dT磁珠进行正向筛选。
通常希望文库能够留有原始目的RNA的链的 方向性 。比如,逆转录产生的反义RNA在调节基因表达中发挥作用。实际上,lncRNA分析依赖于定向RNA测序。制备定向RNA-seq文库的方法有几种。逻辑时,进行cDNA反应,将两条链中的1条有选择地移除,通过,在第二条cDNA链合成时加入dUTP。尿嘧啶包含的链可以被响应的酶消化掉或者扩增的时候用不识别尿嘧啶的聚合酶。 另外,加入actinomycin D可以减少一链cDNA合成过程中假义链的合成。
另一种杂交方法利用随机或锚定oligo-dT引物的接头序列起始第一链cDNA的合成。接下来,在模板转换步骤,3端接头序列添加到cDNA分子。这种方法的明显优势在于第一链cDNA分子可以利用3端的唯一序列标签无需进行第二链合成,直接通过PCR进行扩增。5端唯一序列标签在第一链合成过程中引入。
用于cDNA合成的引物设计对于RNA-seq文库非常重要。比如,rRNA序列可以通过设计靶向rRNA的引物(不用于进一步扩增)进行去除。 NuGEN Ovation RNA-seq结合SPIA( Single primer isothermal amplification )核酸扩增技术以及用于第一链cDNA合成的引物来抑制rRNA的扩增。另一种方法中利用4096种六聚体来抑制rRNA序列(识别并消除完美匹配)。749种六聚体保留并用于起始第一链cDNA合成反应。结果是,rRNA reads从78%降至13%。还有一种方法叫, DP-seq ,利用44个7聚体引物扩增了大部分的小鼠转录本。这种引物设计选择性地抑制了高表达转录本的扩增,包括rRNA,并提供了胚胎发育模型中低丰度转录本的估计。
最近发表了一些制备单细胞RNA文库的方法。一种方法利用第一链cDNA的多聚核苷酸尾巴,结合模板转换反应。结果是第一链cDNA产物可以通过通用PCR引物进行扩增。如图,Figure4B所示,且已并入是试剂盒中。另一种方法叫 CEL-Seq ,在cDNA 5端合成T7启动子序列,随后在体外转录过程中进行现象扩增。
单个细胞的总RNA一般为10pg,但polyA RNA只有0.1pg。因此,这些方法某种程度上需要全转录本扩增以产生足够的建库所需起始量。这样大量扩增的弊端就在于大量技术噪音的产生,这一问题目前尚未解决。 (?)
最后,核糖体印记能够反应翻译的任何节点上细胞mRNA转录本的混合。这种方法涉及到利用RNase对细胞进行裂解,只留下被核小体保护的30个核苷酸的区域。核小体经蔗糖梯度密度离心进行纯化,接着mRNA被从核小体中提取出来。另一种新的RNA测序的应用是 SHAPE-Seq,通过酰化试剂来偏向性地修饰未配对的碱基以探索RNA的二级结构。通过对修饰的RNA和未修饰的对照进行逆转录,对得到的cDNA片段进行测序,比较后能够揭示核苷酸水平的碱基配对信息。
Illumina测序原理
由于现在手头所分析的RNA-seq要用到的数据全部是来自与Illumia测序,所以决定先看看Illumina的测序原理。
决定先看youtube上的陈巍学基因。
https://www.youtube.com/watch?v=VvS8NEJGxnM
其中的一些注意点:
1)adapter是接头,分为pcr扩增接头和测序接头,分别用于文库构建和测序的引物。
index是索引序列,为区分不同样本而构建。高通量测序一次一块板要加好多样品,如果你的样品少那单独测你的测序公司就亏了,因此把你的和别人的样品放到一起,分别加个index用以区分,测序结束后就可以根据index来分离单个样本了
2)双端测序,应该是先从第一链的接头那里开始测,测完后,从第二链的接头那里开始测,并非是在一条链上两端测序
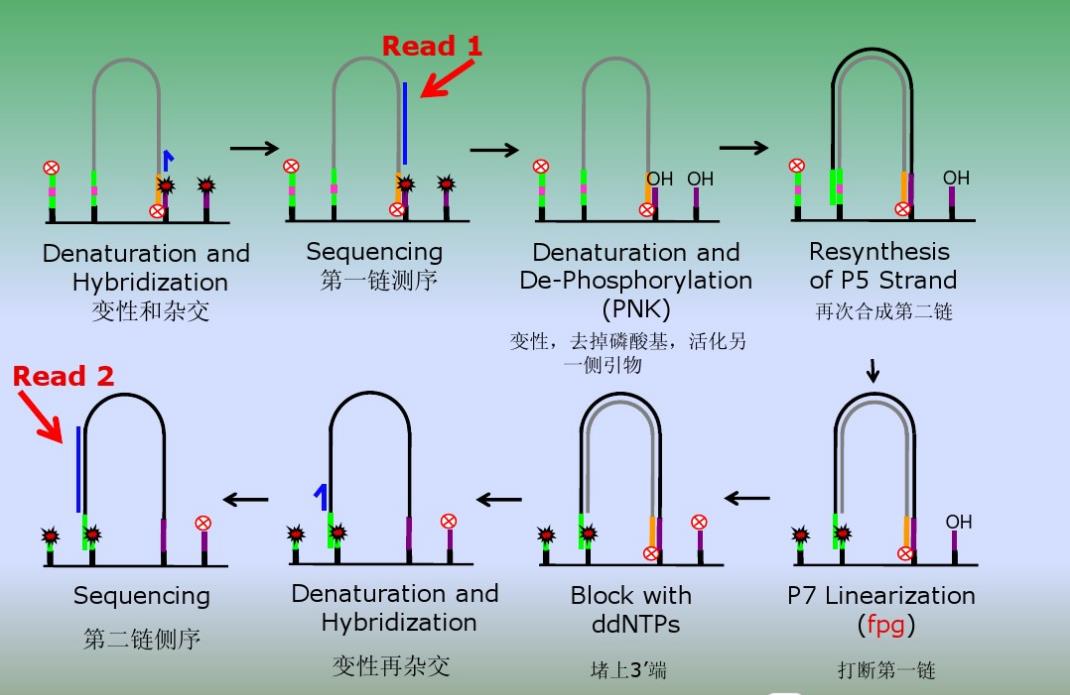
3)Pair-end reads,就是双端测序,简称PE,也就是一段DNA,从正向读一次,再从反向读一次。与双端测序相对的,是单端测序,也叫Sing read,简称SR,在中国大陆,也有许多人将之称为SE,single-end。
4)1、测序深度:测序得到的总碱基数与待测基因组大小的比值。假设一个基因组大小为7M,测序总碱基数为70M,则测序深度为10×。
2、覆盖度:测序获得的序列占整个基因组的比例。由于基因组中高GC含量,重复序列等复杂结构的存在,测序最终拼接组装的序列往往无法覆盖所有的区域,这些区域就叫做Gap。
二者的关系:测序深度与基因组覆盖度之间是一个正相关的关系,测序带来的错误率或假阳性结果会随着测序深度的提升而下降。当测序深度在10~15X以上时,基因组覆盖度和测序错误率控制均得以保证。
5)RPKM(reads per kilobase per million reads)是每百万读段中来自于某基因每千碱基长度的读段数。其公式为:

其中,total exon reads指映射到某个基因上的reads数,mapped reads指map到所有基因的总的reads数。
RPKM不仅对测序深度作了归一化,而且对基因长度也作了归一化,使得不同长度的基因在不同测序深度下得到的基因表达水平估计值具有了可比性,是目前最常用的基因表达估计方法。
之所以分母还要加上这个基因的外显子长度。因为基因是被打断从而测序的,如果一个基因的外显子越长,则其所产生的RNA就越长,被打出来的小片段就越多,比如A基因,1kb,则其可能会被打成5个200bp,而B基因,2kb,则10个200bp,所以B基因在测序中被测到的概率会比A高一倍。除以外显子长度,是为了修正mRNA长度所引起的mRNA的read数的偏差。
以上是关于二代测序文库构建-概述与挑战(1)的主要内容,如果未能解决你的问题,请参考以下文章