MRCP学习笔记-自然语言语义标识语言(NLSML)
Posted Asterisk开源派
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MRCP学习笔记-自然语言语义标识语言(NLSML)相关的知识,希望对你有一定的参考价值。
MRCP协议使用了Natural Language Semantics Markup Language(NLSML)来呈现数据的输出格式,它封装了语音识别资源和说话人确认资源的数据。Natural Language Semantics Markup Language的中文的全称是自然语言语义标识语言。为了书写方便,我们在接下来的部分使用其缩写来表示。NLSML是W3C的一个发布标准,MRCP协议借用了NLSML的部分技术细节,经过一些裁剪实现了MRCP的NLSML版本。在今天的章节中,我们将涵盖MRCP的自然语言语义标识语言一些关键配置参数和使用示例。
首先,我们介绍一下NLSML的一些背景信息。MRCP中的NLSML实际上是一种数据交换的格式,它介于语音识别和说话人确认资源的之间。
NLSML可表示的数据信息包括用户语音输入,用户的DTMF输入,和其相关的语义解释信息,信任度信息和时间戳的信息。
MRCP拓展了NLSML来进一步表示说话人注册语法(英文全称是Voiceen rolled grammars, 有时也称之为speaker dependent grammars)相关数据。speaker dependent grammars 表示的是由用户自己语音创建的语法,为了进一步的语音识别操作来服务的语法形式。
NLSML也可以配合说话人确认资源来表示各种说话人确认信息和身份等相关的数据。
首先让我们看看NLSML的数据结构。NLSML的数据结构通过媒体类型来定义:application/nlsml+xml。其结构如下:
<?xmlversion="1.0"encoding="UTF-8"?><resultxmlns="http://www.ietf.org/xml/ns/mrcpv2">
...
</result>
这里的数据完全取决于是否使用了NLSML返回的语音识别的结果信息,例如语音识别结果,声音注册的语法结果和说话人确认和身份结果都等数据。我们在下面的章节中会依次介绍这三种数据结果的结构。
现在我们首先介绍一下语音识别结果的数据格式。语音识别的结果是被封装在NLSML中,并且包含在了RECOGNITION COMPLETE事件的消息体或GET-RESULT 响应的信息体。我们已经在前面的章节中介绍过事件的消息体内容,读者可查阅历史文档学习。NLSML的结果通过<result>的一个或多个子要素标签<interpretation>来做标识。以下表中表示了NLSML中的数据格式要素和其属性数值。
刚才,我们已经提到过,每个NLSML文件至少包含一个或多个<interpretation>。如果有多个<interpretation>时,这里的<interpretation>将会以递减信任度的形式排列。可选数值confidence表示对其<interpretation>的数值的信任评价值,其取值范围从0.0到1.0。在<interpretation>中包含一个<input>和一个<instance>要素。<input>表示用户输入的文本形式,<instance>则包含了相应的语义解释结果。如果没有成功识别的话,此文件会包含<noinput>或 <nomatch>的要素,表示未成功识别。timestamp-start和timestamp-end用来表示用户输入时间段。这里,读者要注意,其时间戳格式是ISO 8601格式标准。
语音识别在一定时间内,其检测结果可能是成功的也可能是失败的。
我们重点介绍几个不同的状态返回结果。当在一定时间内没有检测到用户输入时,语音识别引擎会在返回的RECOGNITION-COMPLETE事件中返回002 no-input-timeout 错误码。关于002 错误码我们在以前的章节中做过介绍,用户可以查阅历史文档。如果NLSML结果在返回的事件的消息体中的话,NLSML将返回一个<noinput>作为<input>的子要素。如果识别引擎检测到了用户输入数据,但是识别引擎没有匹配语法设置或超过信任度的峰值参数时,在RECOGNITION-COMPLETE的返回的事件中,识别引擎会携带001 no-match 错误码。同时,如果返回的事件消息体中包含了NLSML的结果,NLMSL将包含一个<nomatch>子要素作为<input>的子要素。另外,在<nomatch>要素中可能包含某些可选的文本,这些文本是被拒绝匹配中的最佳结果。我们列举几个不同的返回结果来说明语音识别是否成功。
成功的识别结果,包含两个<interpretation>值和相应的返回值<instance>。
<?xml version="1.0" encoding="UTF-8"?>
<result xmlns="http://www.ietf.org/xml/ns/mrcpv2"
grammar="http://www.example.com/demo.grxml">
<interpretation confidence="0.81">
<input mode="speech">
to recognise speech
</input>
<instance>
to recognise speech
</instance>
</interpretation>
<interpretation confidence="0.75">
<input mode="speech">
to wreck a nice beach
</input>
<instance>
to wreck a nice beach
</instance>
</interpretation>
</result>
无用户输入的检测结果,这里输出的是<noinput/>子要素,可能没有用户输入或没有设置时间戳设置。
<?xml version="1.0" encoding="UTF-8"?>
<result xmlns="http://www.ietf.org/xml/ns/mrcpv2">
<interpretation>
<input mode="speech">
<noinput/>
</input>
<instance/>
</interpretation>
</result>
无匹配的返回结果,这里可能是信任度峰值的数值不准确导致不匹配。
<?xml version="1.0" encoding="UTF-8"?>
<result xmlns="http://www.ietf.org/xml/ns/mrcpv2"
grammar="http://www.example.com/number.grxml">
<interpretation confidence="0.31">
<input mode="speech">
<nomatch>one</nomatch> // 虽然返回拒绝匹配输出结果,但是提供了最佳匹配可选内容。
</input>
<instance/>
</interpretation>
</result>
上面的章节中我们介绍了语音识别的返回结果匹配的结果,这里我们进一步介绍包含语义解释的语音识别的语法结构。当语法中的tag-format设置为semantics/1.0-literals 时,<tag>要素中的内容则被解释为ECMAScript 脚本。我们在前面的章节中已经说明这个定义。当所有匹配的<tag>执行以后会从语法规则中生成语义结果。然后,NLSML会把匹配的语法中的语义解释结果插入到<instance>中。现在让我们看一下以下示例:
<?xmlversion="1.0"encoding="UTF-8"?><grammarversion="1.0"xmlns="http://www.w3.org/2001/06/grammar"
mode="voice"xml:
lang="en-IE"
root="yesno"
tag-format="semantics/1.0-literals">
<ruleid="yesno">
<one-of>
<item>yes<tag>affirmative</tag></item>
<item>yea<tag>affirmative</tag></item>
<item>no<tag>negative</tag></item>
<item>nah<tag>negative</tag></item>
</one-of></rule>
</grammar>
现在,如果我们假设用户发音是单词“yea”,那么NLSML可能生成的结果是:
<?xmlversion="1.0"encoding="UTF-8"?><resultxmlns="http://www.ietf.org/xml/ns/mrcpv2"
grammar="http://www.example.com/yesno.grxml"><interpretationconfidence="0.91">
<inputmode="speech">yea</input>
<instance>affirmative</instance>
</interpretation></result>
其他的应用程序则可以根据<instance>的结果来做进一步的业务处理。
前面我们介绍了ECMAScript的语法结构和具体使用方式和解释结果。语义解释结果会保存到数据文件中。当规则中的变量被认定为一个标量类型(例如string, number,boolean,null或undefined类型)时,那么语义结果同样会NLSML生成的<instance>中。这里,如果number是小于零,则加一个negative前缀。如果是布尔值,则为true或false。null则为null值。如果是undefined的值,则仍然为undefined值。以下语法同样会生成同样的语义结果(根据前面所生产的语义结果):
<?xmlversion="1.0"encoding="UTF-8"?><grammarversion="1.0"xmlns="http://www.w3.org/2001/06/grammar"
mode="voice"xml:
lang="en-IE"
root="yesno"
tag-format="semantics/1.0">
<ruleid="yesno">
<one-of>
<item>yes<tag>out="affirmative";</tag>
</item><item>yea<tag>out="affirmative";</tag></item><item>no<tag>out="negative";</tag></item>
<item>nah<tag>out="negative";</tag></item>
</one-of>
</rule>
</grammar>
当语法规则的变量不是标量变量类型,它返回的是ECMAScript 对象时,则处理的数据格式更加复杂。关于如何从ECMAScript 对象转转换成XML语法结构的规定,用户可以参考Semantic Interpretation for Speech Recognition(SISR)。规则中定义了不同的转换规则,用户可以做进一步的了解。具体的规则如下:

现在让我们了解一下语法规则和转换后的结果:
<?xmlversion="1.0"encoding="UTF-8"?><grammarversion="1.0"xmlns="http://www.w3.org/2001/06/grammar"
mode="voice"
xml:lang="en-GB"
root="travel"tag-format="semantics/1.0">
<ruleid="travel">
<tag>out.travel=newObject();</tag>
I want a fly from
<rulerefuri="#city"/>
<tag>out.travel.orig=rules.city;</tag>
to
<rulerefuri="#city"/>
<tag>out.travel.dest=rules.city;</tag>
</rule><ruleid="city">
<one-of>
<item>Dublin<tag>out="Dublin";</tag></item><item>London<tag>out="London";</tag></item><item>Paris<tag>out="Paris";</tag>
</item>
</one-of>
</rule>
</grammar>
在以上的示例中,对于“I want to fly from Dublin to Paris“ 输入变量来说,其生成的结果规则变量是:
{
travel:
{
orig:Dublin,
dest:Paris
}
}
如果我们把整个结果通过规则转换的规则来进行语法处理后,NLSML的结果类似于:
<?xmlversion="1.0"encoding="UTF-8"?>
<result xmlns="http://www.ietf.org/xml/ns/mrcpv2"
grammar="http://www.example.com/travel.grxml">
<interpretation confidence="0.93">
<input mode="speech">I want to fly from Dublin to Paris</input>
<instance>
<travel>
<orig>Dublin</orig>
<dest>Paris</dest>
</travel>
</instance>
</interpretation>
</result>
语法规则变量的类型也可能是array类型或其中一个属性可能是array的数据类型。这种情况下,如果规则变量转换成语义结果的话,需要遵守一定的规则。具体的规则如下:
Array对象的带索引的要素会变成XML的子要素,并且带<item>名称。
每个item中的参数属性命名为带索引支持,此索引对应Array中的要素。
XML文件中包含<item>要素属性length,此值通过ECMAScript Array的对象来定义。
以上规则看起来比较难以理解,我们通过以下示例来加以说明:
<?xmlversion="1.0"encoding="UTF-8"?>
<grammar version="1.0"
xmlns="http://www.w3.org/2001/06/grammar"
mode="voice"
xml:lang="en-GB"
root="string"
tag-format="semantics/1.0">
<ruleid="string">
<tag>out.digitstring=newArray();</tag>
<itemrepeat="1-">
<rulerefuri="#digits"/>
<tag>out.digitstring.push(rules.digits);</tag>
</item>
</rule>
<ruleid="digits">
<one-of>
<item>one<tag>out=1;</tag></item>
<item>two<tag>out=2;</tag></item>
<item>three<tag>out=3;</tag></item>
<item>four<tag>out=4;</tag></item>
<item>five<tag>out=5;</tag></item>
</one-of>
</rule>
</grammar>
如果用户的输入语句是”5,4,3,2,1“的话,生成的array 类型的对象变量结果格式为:
{
digitstring:[ 5, 4, 3, 2, 1] // 这里的长度是5,包含五个数值。
}
如果按照上面的三条规则进行转换以后,生成的结果类似于:
<?xmlversion="1.0"encoding="UTF-8"?><resultxmlns="http://www.ietf.org/xml/ns/mrcpv2"
grammar="http://www.example.com/yesno.grxml">
<interpretation confidence="0.93">
<input mode="speech">
five four three two one
</input>
<instance>
<digitstring length="5"> // 长度取决于array 对象值。
<item index="0">5</item> // 这里0对应的是5
<itemindex="1">4</item>
<itemindex="2">3</item>
<itemindex="3">2</item>
<itemindex="4">1</item>
</digitstring>
</instance>
</interpretation>
</result>
从概念上来说,注册语音语法可以看作是简单的SRGS语法,它由几个可选设置构成,例如以下示例:
<?xmlversion="1.0"encoding="UTF-8"?><grammarversion="1.0"
xmlns="http://www.w3.org/2001/06/grammar"
mode="voice"
xml:lang="en-GB"
root="address"
tag-format="semantics/1.0-literals">
<ruleid="address">
<one-of>
<item>Mary<tag>user01</tag></item>
<item>Anne<tag>user02</tag></item>
<item>JohnHenry<tag>user03</tag></item>
...
</one-of>
</rule>
</grammar>
这里,短语(Mary,Anne,JohnHenry)通过自己的注册session ID和对应的语义解释添加到了语法中。每个短语通过MRCP 客户端提供的唯一短语ID来进行跟踪。在注册会话中,用户说几次短语的名称,每次捕捉的短语会和以前的短语采样进行对比。当捕捉到足够说话采样以后,短语经过训练以后生成个人注册语音语法。这个个人的注册语音语法可以通过正常的语音识别引擎使用个人语法的URL加以调用。当短语在设定的注册会话期间成功匹配后,语义解释结果会以NLSML的结果返回。这里,我们再次强调,这里的部署仅从理论上加以讨论,具体的实现方式完全依赖于每个语音识别的平台本身以及平台语法和短语等存储方式,语法结构等相关参数。当MRCP 客户端对语音识别引擎发出 START-PHRASE-ENROLLMENT请求时,注册会话则开始启动。当MRCP客户端对语音识别引擎发出END-PHRASE-ENROLLMENT 请求时,注册会话的生命周期结束。如果在RECOGNIZE请求中包含头域Enroll-Utterance:true会触发对语音进行捕捉。在对应的RECOGNITION-COMPLETE事件中会包含NLSML结果,它封装了注册的尝试信息。具体的注册结果我们在未来的章节中会做进一步的介绍,现在我们专门针对NLSML中包含的语音注册结果的格式进行介绍。
NLSML包含的语音注册结果通过<enrollment-result>来加以定义,<enrollment-result>是<result>的子要素。以下列表说明了语音注册结果的表达方式:
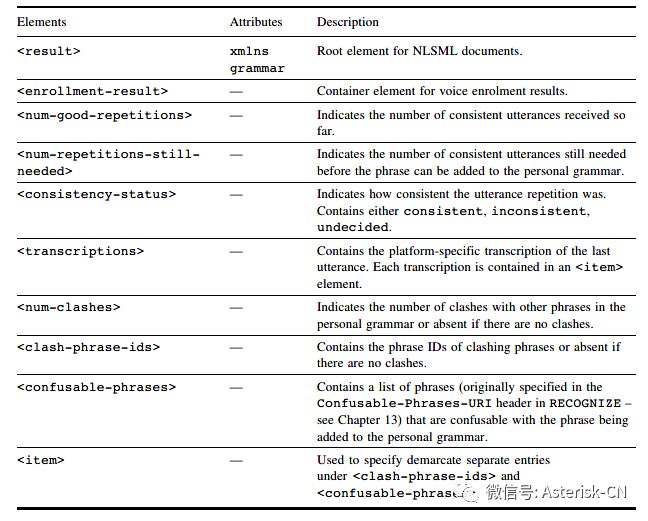
让我们看一下在语音注册会话生命周期中,RECOGNITION-COMPLETE事件返回的NLSML结果。在下面的示例中,具体语法结果表示通过URL设定了个人语法,目前收到一个连续的语音,仍然需要获得两个或多个语音,并且还有两个不相容短语(Mary和Madge,它们分别通过clash-phrase-id 表示)。
<?xmlversion="1.0"encoding="UTF-8"?><resultxmlns="http://www.ietf.org/xml/ns/mrcpv2"
grammar="http://example.com/ve/personal-grammar-01">
<enrollment-result>
<num-good-repetitions>1</num-good-repetitions>
<num-repetitions-still-needed>2</num-repetitions-still-needed>
<consistency-status>consistent</consistency-status>
<transcriptions>
<item>Marie</item>
</transcriptions>
<num-clashes>2</num-clashes>
<clash-phrase-ids>
<item>Mary</item>
<item>Madge</item>
</clash-phrase-ids>
</enrollment-result>
</result>
MRCP通过NLSML封装了说话人的状态验证信息。这些结果消息包含在VERIFICATION-COMPLETE事件的消息体中,是GET-INTERMEDIATE-RESULT请求的对应响应。关于说话人验证和定位消息,我们在以前的章节中做过简单的介绍,在未来的章节中会更加深入地进行剖析。这里,我们仅关心NLSML的文件结构, 这里的NLSML文件用来描述训练的声纹结果,声纹对比以后的语音变化,说话语音和多个声纹对比来确认状态。NLSML在<verification-result> XML要素来获得支持。以下列表是一个关于speaker verification/identification 结果的汇总:
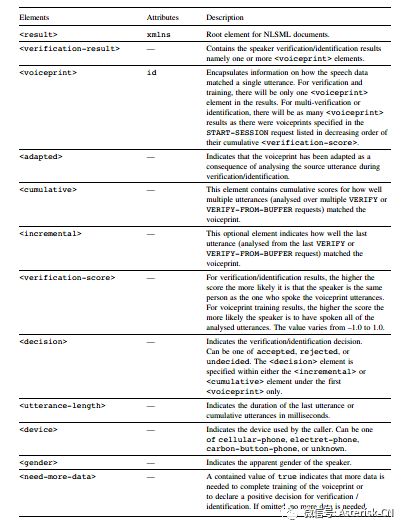
以下是一个在声纹训练中返回的验证结果。NLSML包含在VERIFICATION-COMPLETE的事件消息体中,或GET-INTERMEDIATE-RESULTS 请求的响应中:
<?xmlversion="1.0"encoding="UTF-8"?><resultxmlns="http://www.ietf.org/xml/ns/mrcpv2">
<verification-result>
<voiceprint id="joebloggs.voiceprint">
<incremental>
<verification-score>0.91</verification-score>
<device>cellular-phone</device>
<gender>male</gender>
<utterance-length>751</utterance-length>
</incremental>
<cumulative>
<verification-score>0.93</verification-score>
<device>cellular-phone</device>
<gender>male</gender>
<utterance-length>1522</utterance-length>
<need-more-data>true</need-more-data>
</cumulative>
</voiceprint>
</verification-result>
</result>
在这个示例中已经有一个声纹的确认ID:joebloggs.voiceprint。<incremental> 表示要针对前一个讲话的分析结果来做进一步处理。其他独立的标签表示设备类型,说话人性别等信息。<cumulative>中的值是针对说话语音分析,这些语音分析数据是通过多个VERIFY或VERIFY-FROM-BUFFER请求获得的累计的cumulatives cores值。<verification-score> 这里表示的是拟然值,同样的说话人说过的所有同样的句子。<utterance-length>表示训练中所使用的所有语音长度,它以毫秒为单位。<need-more-data>设置为true则表示需要更多数据来完成声纹训练,MRCP 客户端可能需要从用户侧获得更多的数据,因此要求发送更多的VERIFY 或VERIFY-FROM-BUFFER请求获得支持数据。
现在,让我们介绍一个关于验证结果的示例。在START-SESSION请求中,我们在头域Voiceprint-Identifier设定了一个单个的声纹,我们期望获得的单个声纹NLSML返回结果,在结果中包含一个<voiceprint>。具体的xml 结果如下:
<?xmlversion="1.0"encoding="UTF-8"?><resultxmlns="http://www.ietf.org/xml/ns/mrcpv2">
<verification-result>
<voiceprintid="joebloggs.voiceprint">
<incremental>
<verification-score>0.85</verification-score>
<device>carbon-button-phone</device>
<gender>male</gender>
<utterance-length>841</utterance-length>
</incremental>
<cumulative>
<verification-score>0.81</verification-score>
<device>carbon-button-phone</device>
<gender>male</gender>
<utterance-length>1619</utterance-length>
<decision>accepted</decision>
</cumulative>
</voiceprint>
</verification-result>
</result>
通过累计分析,这里的<decision>accepted</decision>表示说话人语音资源已经足够匹配其中一个说话的声纹。
最后,我们再介绍一个如何确认从多个说话人的声纹中确认某个说话人。这里,假设“JoeBloggs”是属于我们前面例子中“MaryBloggs”和“TedBloggs”的成员。在START-SESSION 的请求中设定的Voiceprint-Identifier将会列出所有三个声纹,然后生成NLSML结果,这个结果包含三个<voiceprint>要素:
<?xml version="1.0" encoding="UTF-8"?>
<result xmlns="http://www.ietf.org/xml/ns/mrcpv2">
<verification-result>
<voiceprint id="marybloggs.voiceprint">
<incremental>
<verification-score>0.85</verification-score>
<device>cellular-phone</device>
<gender>female</gender>
<utterance-length>842</utterance-length>
</incremental>
<cumulative>
<verification-score>0.85</verification-score>
<device>cellular-phone</device>
<gender>female</gender>
<utterance-length>842</utterance-length>
<decision>accepted</decision>
</cumulative>
</voiceprint>
<voiceprint id="tedbloggs.voiceprint">
<cumulative>
<verification-score>0.31</verification-score>
</cumulative>
</voiceprint>
<voiceprint id="joebloggs.voiceprint">
<cumulative>
<verification-score>0.29</verification-score>
</cumulative>
</voiceprint>
</verification-result>
</result>
这里的排序是按照<verification-score> 的值,从最大值到最小值的排序方式。说话人语音和列表中的声纹进行对比,现在可以确认,说话人是Mary Bloggs,而不是另外的人。
在本章节中,我们介绍了MRCP协议中的数据表达格式-自然语言语义标识语言(NLSML)。在具体的章节中,我们首先介绍了NLSML的背景知识,文件结构。然后介绍了NLSML的语音识别的结果输出格式和其脚本(ECMAScript)的转换机制以及语义对象,array等使用方式的内容。我们也介绍了通过用户注册的语法实现个人语法的NLSML结果以及如何使用在标准的语音识别引擎中。最后,我们介绍了关于如何验证说话人以及确认说话人的方式,声纹训练。MRCP协议通过几个不同的NLSML和声纹资源输出结果,和相应的最终<verification-score>值来判断说话人。
在接下来的章节中,我们会介绍MRCP数据呈现的最后一种语法格式-Pronunciation Lexicon Specification (PLS)。
参考资料:
https://www.w3.org/TR/semantic-interpretation/
https://www.nuance.com/content/dam/nuance/en_us/collateral/enterprise/data-sheet/ds-nuance-recognizer11-en-us.pdf

freepbx 技术论坛:www.ippbx.org.cn
Asterisk, freepbx技术文档: www.freepbx.org.cn
欧米(Omni)智能客服解决方案
融合通信商业解决方案,协同解决方案首选产品:www.hiastar.com
以上是关于MRCP学习笔记-自然语言语义标识语言(NLSML)的主要内容,如果未能解决你的问题,请参考以下文章