回顾·音乐垂域的自然语言理解
Posted DataFunTalk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了回顾·音乐垂域的自然语言理解相关的知识,希望对你有一定的参考价值。
大数据、算法的交流学习平台 圈内人都在关注



本文根据小米智能云秦斌老师在DataFunTalk人工智能技术沙龙“自然语言处理技术应用实践”中分享的《音乐垂域的自然语言理解》编辑整理而成,在未改变原意的基础上稍做删减。

(秦斌老师在活动现场)

今天分享的内容有项目研究背景、实现了那些功能,在做音乐领域时有哪些独有的问题与挑战,还有就是“小爱”项目具体的实现。
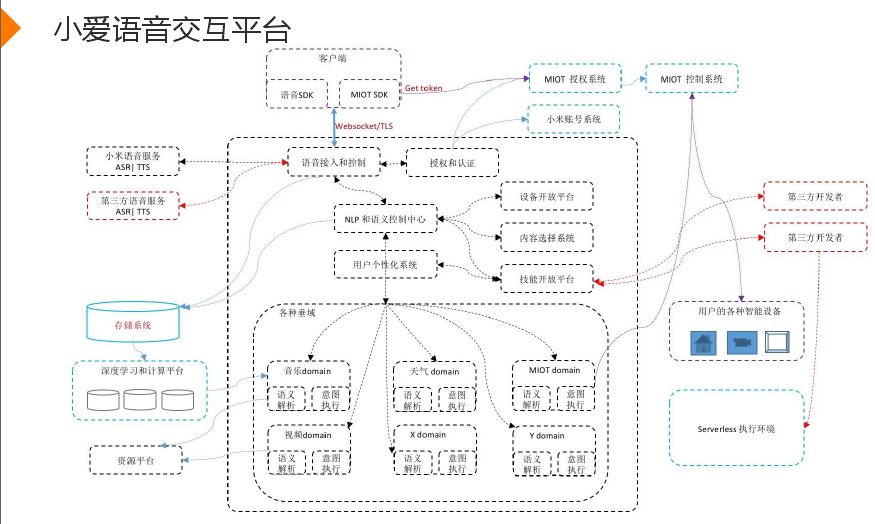
上图是整个小爱语音交互平台的后台服务架构,小米大脑定位的是一个平台,能够处理各种数据。在最外部给各种厂商封装了SDK接口,目的使厂商能够很快的接入,降低你接入成本,如果你要操作小米相关智能设备就要MOIT授权验证。后续会有小米语音服务ASR,语音识别都在客户端,由于平台特性,在云端接入ASR厂商,如微软、百度、科大讯飞、猎狐星空等,部署于云端便于控制和优化,可以额外做一些文本选择等功能。语音转化为文本就会进入NLP模块,在NLP中控部分会做一些个人训练计划、公共训练计划、还有一些query概率,然后将其发布到精品垂域,采用分而治愈的思想,每一个垂域将这个领域的语料、知识、常见说法给建立起来,由中控选择最终的垂域。最外部有一个设备开放平台oivs,方便各种硬件设备厂商接入。后续还有一个技能开放平台,第三方技能开发者能够在平台上很简单的实现一个技能,如打开成语接龙或闲聊,将query转给第三方技能。周边就是机器存储、机器学习平台等资源平台。
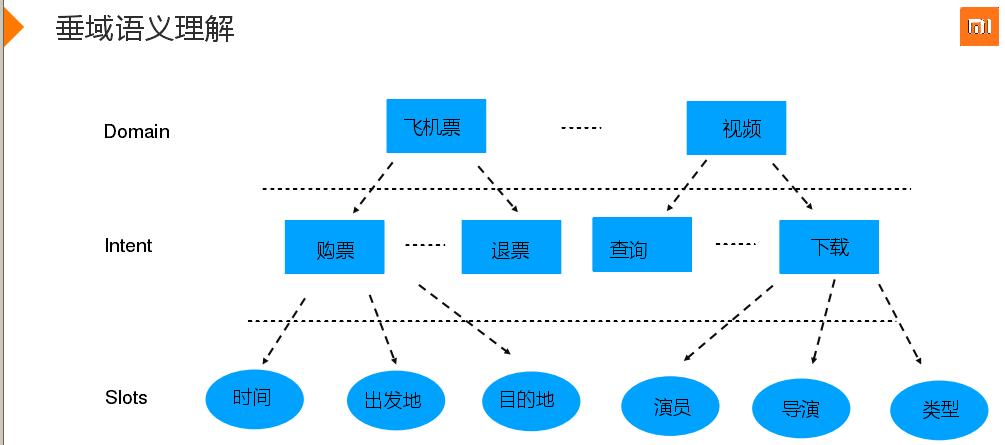
接下来介绍下,一个垂域要做那些事情。如飞机票垂域,要理解用户的意图,是要购票还是退票,音乐就是你要找歌手、听歌、还是找一个推荐;在意图理解后抽取Slot(一个个的字段),如时间、出发地、目的地。整体就是将一个纯文本机构化,将相关信息抽取出来,这是做语义理解经常要做的事情。

接下来介绍下音乐领域实现了那些功能,第一个就是用户的个性化推荐,如随便放首歌、歌单等。再往后就是一个搜索意图,比如我要听周杰伦的歌,周杰伦的简单爱,抽取“歌手/歌名/专辑/标签”四类字段(slot)信息。字段消歧,如“三生三世十里挑花的歌”,其实这是一个专辑,同时也有首歌叫三生三世十里桃花,通过用户原始信息知道应该是专辑而不是歌名。ASR不可能完全准确还有用户发音问题,因此需要纠错,纠错太多召回存在问题,一言不合就放歌,把握不好就会觉得你太笨,对“歌手/歌名/专辑/标签”字段的”同音/补全/乱序”纠错。如歌手同名问题,歌词错误,歌名与歌手对应错误等。

还有一些音乐特色功能:(1)音乐意图的上下文继承,对字段信息进行信息补全或指代消解。如我想听刘德华的歌,完了又说要播放他的笨小孩,那就是“刘德华的笨小孩”;(2)用户情感分析。如“我想听岁月神偷不要听金玟岐的”,就是对Artist的一个否定;(3)指定播放顺序;(4)根据歌词内容识别歌曲,如“海草海草”识别到是“海草舞”;(5)收听历史歌曲,需要提出时间信息。

上面介绍音乐要实现的功能,接下来介绍遇到的挑战。首先(1)实体名太过复杂,形式多样,没有固定的组成规则;知识库数量巨大,如QQ音乐是千万级,网易云音乐数百万,阿里系也有数百万。由于歌数量巨大,很多都垄断,要识别这些歌曲需要建立知识库,但是原始数据存在很大的噪音,缺少字段信息,歌名不规范。需要将海量数据爬取下来,判重。(2)用户说法很乱,不符合自然语言,比较简单,没有固定形式,半结构化文本。(3)实体名纠错。由于实体名自身的复杂性和多义性,存在着同音纠错,方言纠错,乱序纠错等多种纠错情况。
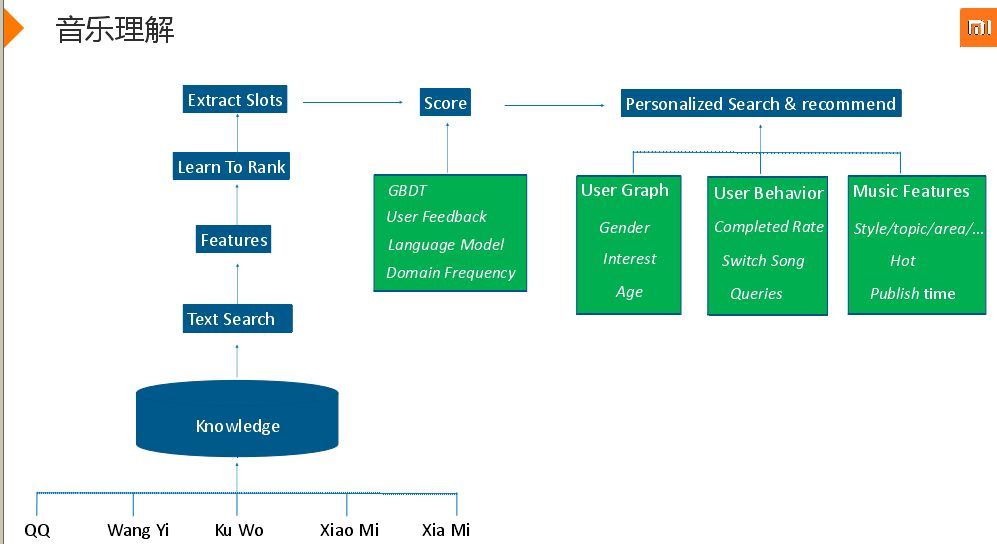
知识库很多,实体名很复杂,单纯用词表不能很好地解决这个问题,采用了知识库加搜索的方案。搜索能很容易解决数百万知识库,不存在性能问题,搜素排序算法技术比较成熟,搜索保留了歌的物理信息,如“王菲红豆”就能知道是红豆这首歌,但是如“韩红红豆”就不是歌了。歌来源有爬取的也有合作的,进入知识库后会有一个文本搜素,抽取feature,利用learn to rank排序,通过query确定用户想听那首歌,确定歌名,抽取slot,利用GBDT模型打分。还有User feedback,language model,domain frequency(利用用户行为反馈,改善向量效果)。后面就是个性化的搜索和推荐,如用户的性别、行为,歌一放出来就切换,还有音乐的热度、风格、发行时间等。大致流程会对query做一些前置理解,后续从知识库中找到与之相关的歌,抽取slot,然后进行语义消歧。然后打分,然后利用语言模型判断是否符合常用规则。
数据是核心,资源主要来自资源方、垂直网站还有人工运营平台。获取数据后对数据进行归一化,做相应的映射,打一些标签。还要排重,一家网站一首歌也会存在很多版本,但是我们只需要原始数据忽略版本。后续就进行DB、内容评审、构建索引等,清洗数据会花费大量时间。
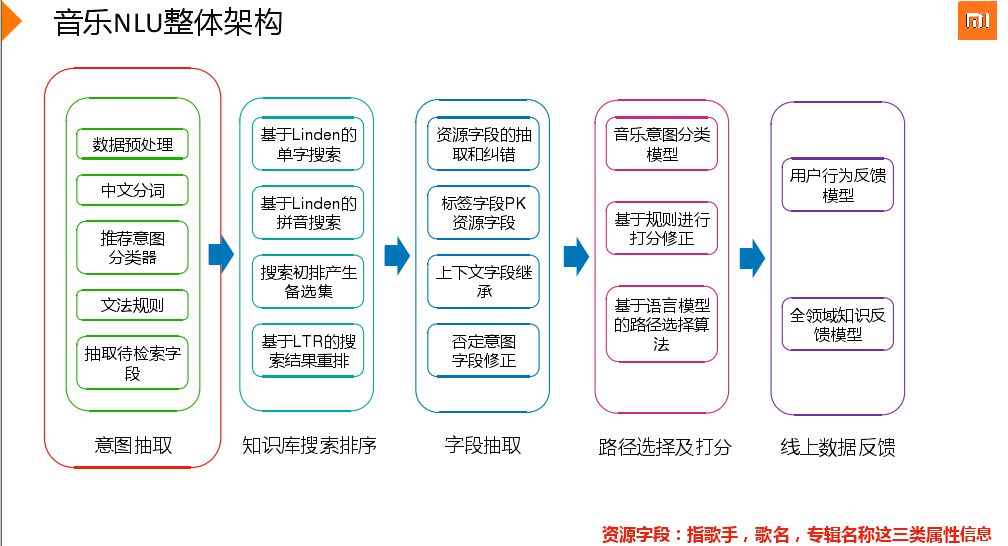
音乐NLU整体架构,分为意图抽取、知识库搜索排序、字段抽取、路径选择及打分、线上数据反馈。意图抽取会对query进行预分析,数据预处理,然后中文分词还有推荐意图分类器,还有文法规则,最后找到一些主干query供后续搜索,先理解query语义上的可能的一些倾向性的方向判断,找到主干query供第二部使用。

接下来介绍一下推荐意图分类器,在获取query时,增加了一个二分类判断,判断是否是推荐意图,目的是简化搜索,节省时间,同时为策略判断给出一些特例。具体做法是中文分词后抽取n-gram特征,如单词特征、二元特征、三元特征,最后利用逻辑回归。后续会使用Woed2vec,因为word2vec 能够捕捉更多语法和语义特征。

接下来就是文法规则匹配,自定义了一套文法规则,支持变量的定义、文法的组合、文法替代,目的是对query语义做倾向性判断。还有影视类、标签类的词典,标签文法对标签进行了强分类(强标签、弱标签)。
第二部分局势知识库搜索排序,基于Linden做的搜索。Linden是基于开源的Lucene包,Linden就是将其服务化,集群管理,加入类似SQL语言,便于集群查询。单词搜索主要针对用户说法很乱,如果进行切词可能无法召回,但是出现的问题是召回太多。最后会对初排后结果learn to rank,进行重排。

知识库中有数百万的数据,每周都需要评测更新一半的索引,上线有严格的流程,线上的策略改动、数据改动都要经过评测才能上线,还有人工审核top query。知识库索引设计支持歌手、歌名、歌手别名、专辑和影视类字段的综合搜索,支持单字和拼音两类搜索方式。知识库搜索初排也会支持降权,在搜索时就进行降权。

在初排后进入中间层会利用排序算法进行二次排序,如从top80里面选择一个最相似的文档。正负样本比例失衡,适用于Learn to rank算法,最后选用LamdaMart,采用决策树模型会学习到很多特征组合。模型特征有字段匹配类别、相似度,字段匹配长度,字段纠错类别,文档热度等50多个相关特征。
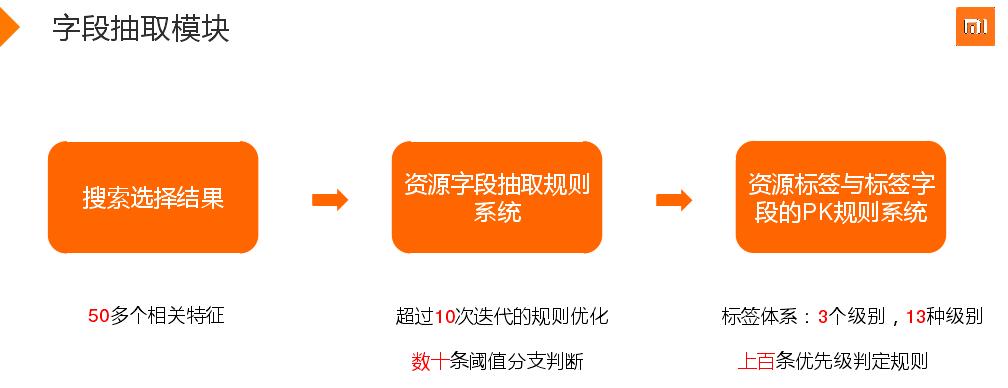
通过相关特征选择一首歌后,进行字段抽取。涉及资源字段的抽取和纠错,标签字段PK资源字段,如判断青春是歌手还是歌名,上下文字段继承,否定意图等。字段抽取是基于纯规则,有些热门歌曲唱错时也会将其选择出来,如一个歌手没唱过这首歌,但是如果是热门歌曲也会选择出来。

打分是基于意图分类和规则打分,还有基于语言路径的用户选择。由于语言的歧义性可能会选择多条路径,典型二分类问题,缺少其他domain打分信息结合少量必要规则,替代原有规则系统。最终选定GBDT算法,利用各种特征,如职业特征,郭德纲、岳云鹏都唱过歌,但是职业是相声演员,单说歌手就会将其推电台。还有一个优势就是APP搜索日志,小米音乐大都是key-words搜索,如果在日志中找到也是属于音乐特征。
文本搜索有用户点击信息,但是语音很难找用户行为特征信息,尤其命令型语音,得不到用户反馈。但音乐可以获取用户听没听这首歌,听了多久。利用的是全领域知识反馈模型,利用DFTF思想,如“大王叫我来巡山”在音乐领域用的很多,当出现大王,就很容易召回。另外还有完成率,就是用户完成行为反馈模型,用户听了多少歌,首条完成率,即第一首歌听完的概率,还有30秒切歌率等指标。
项目目前存在的问题,音乐过召回严重,音乐slot抽取准确性仍需提高,知识库的准确性和完整性存在不足, 聊音乐,想做电台式音乐,这样显得智能,一首歌结束会引出小爱的评价,引出下一首歌。端到端,利用click model训练端到端模型,知道一些query在历史上选为音乐意图,当一个新query来后与历史query比对,如果词向量相近,直接返回结果,简化操作。
——END
以上是关于回顾·音乐垂域的自然语言理解的主要内容,如果未能解决你的问题,请参考以下文章