基于自然语言命令的自动图频编辑系统(附pdf)
Posted 人工智能前沿讲习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于自然语言命令的自动图频编辑系统(附pdf)相关的知识,希望对你有一定的参考价值。
A System for Automated Image Editing from Natural Language Commands
Jacqueline Brixey, Ramesh Manuvinakurike, Nham Le,Tuan Lai, Walter Chang, Trung Bui
回复"自动图频"获取PDF资料
摘要
本研究展示了一项通过自然语言书写命令来在图片编辑软件中修改图片的任务。我们利用超过6000条图片编辑文字命令的众包语料库来修改真实世界的图片。我们提出了一个包含动作和实体结构的把用户的自然语言请求映射为图片编辑软件中可执行命令的新颖框架。我们通过投票过程来解决之前标注标签中存在的分歧并完成了语料库的所有的标注。我们对不同的机器学习算法进行了实验,结果表明LSTM模型,SVM模型以及双向LSTM-CRF联合模型是检测图片编辑动作并把其与一个给定表述中的实体对应起来的最佳模型。
1、概述
自从摄影出现,就一直存在编辑照片的需求。照相机在采集真实世界的光线和色彩有一些固有的局限,使得用户需要通过后期编辑来修整这些局限。诸如Photoshop这种数字图像处理程序也使得图像编辑的过程更加容易实现。但是新手用户发现他们为了成功完成所需的编辑常常需要一些来自例如Reddit’sPhotoshop Request论坛和Zhopped等这些用户可以提交图片编辑请求的网站上的专门的教程。他们在交流他们的编辑需求时通常使用一般化的、非技术的语言,例如:
我的婚纱裙子上有一个污点,有人可以帮我去掉它吗?拜托了!
他刚刚去世。但是他层希望他的依照看起来精彩一点,我觉得他脸上的光线不太好。可以请大家帮我修一下那个光线吗?
我们意在通过开发一个软件工具通过解释和执行自然语言所表达的图片编辑请求来帮助所有的用户实现他们的图片编辑目标。这个工具可以让用户在没有专业用户的帮助并且不需学习专业术语的情况下下独立完成图片编辑操作。我们工作的第一步是开发这样一个工具。我们会利用之前的工作Edit Me 语料库(Manuvinakurike等,2018),这是一个包含已写好的可以修改真实世界图片的编辑请求和相关框架的数据集。我们会通过解析之前的标注不一致的地方并完成对未标签数据的标注来改进这个数据集。所有的表示方式都是基于我们开发Edit Me时所使用的框架,可以将请求映射到图像编辑软件的可执行命令。然后我们会执行一个两层系统,第一层将一个修改中的动作类别,第二层识别这个动作相关的属性。
2、图像和编辑请求综述
2.1 已有研究
结合视觉和语言的研究包括基于视觉的问答系统(Antol等,2015),基于视觉讲述故事(Huang 等, 2016),基于图片生成问题(Mostafazadeh等,2016)以及基于图片展示信息的问答交互系统(Mostafazadeh等, 2017)。有关理解图片描述信息(Kulkarni等,2013)的已有研究对我们的研究工作至关重要,如上面论坛帖子所示(“他脸上的光线”)。我们的研究也借鉴了识别视觉参考信息(如“在我的婚纱裙上”)的研究)(Paetzel等,2015;deVries等,2016)。在Laput等人2013年的研究中曾开发了一个用户通过语音来编辑图片的手机交互软件,这是仅有的有关图片编辑的研究。他们部署了一个基于规则的系统,而我们通过利用机器学习来处理更多样化和更大结构的图片编辑自然语言修改指令,改进了已有的研究。
2.2 语料库
我们利用的是Edit Me语料中通过亚马逊MechanicalTurk众包用户(本研究下文中称turkers)创建的9101个文本编辑请求(总共44727个文字标识)(Manuvinakurike等,2018)。所采用的请求展示了词汇上的广度和具有挑战性的多样性以及语言表示结构和完成类似编辑成果的领域知识。在词汇上,相似但是不同的词语被用来执行相似的操作,例如裁剪、切除和删除,都是用来修改图片大小的。而大多数的编辑请求都是以祈使句动词开头,例如“切掉图片的左侧边缘”,其他流行的表达还包括情态动词以及把图片编辑请求构造成一个评论句,例如“图片是模糊的”。缺少专业知识会导致一些歧义,例如“放大”一词是指将图片的部分调成特写,但是也可能被理解为一个裁剪图片的请求(例如,“放大图中的斑马”)。
2.3 图片编辑的架构
我们的标注框架是作为解释请求中所代表的编辑软件功能的中介语言来使用。一个图片编辑请求(IER)包含一个可能被图片编辑软件来完成的操作。每条IER最多包含一个编辑动作,且包含零个或者更多的相关实体。我们的架构将明显或者隐晦的词语短语映射到18个修改动作之一:调整、删除、裁剪、添加、替换、应用、缩放、旋转、转换、移动、复制、选择、交换、撤销、合并、重做、其他和卷起。当动作提供了对一个IER的第一层理解时,实体就可以完成对如何应用这个动作的解释。我们的架构支持五种类型的实体:属性、修改器/值、物体、区域和意向。
图1 语料库中带标注的图片示例
架构的灵活性允许一个IER带有同类实体类型的多个标注。同时也支持没有实体的表述方式,这种情况占数据集中的3%。框架的一个特性是表述中的同一个词语可能有多个标签,或者一个词语可能是另一个词语的子集。例如“提高饱和度”中,“提高”一词被同时标注为一个“调整”动作和一个“修改器/动作”实体。
3、标注
标注语法之前在一个含有600个表述的样本中进行了评分者信度测试(结果如表1所示)(Manuvinakurike等, 2018)。最高一致性的结果被采用为动作类型,实体的一致性较低但也显著高于随机水平。不过对于一些实体,对应“修改器/值”,一致性处在随机水平的边缘。
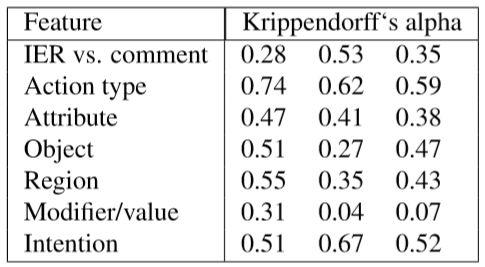
表1 3组标注者(每组3人)的评分者信度测试
由于一致性水平较低,我们决定在尝试计算模型之前,需要对标注者提供更多训练和支持来重做标注。此外,并非所有的语料都是由经过高度训练的标注者来标注的,而是由评分者信度一致性更低的Turkers来完成的(可以参考(Manuvinakurike等,2018)查阅相关分数)。因此,所有的表述都被经历了通过对浏览并讨论注解及之前标签中有分歧的注解训练的标注者标注了一遍。
数据集中最常见的动作是“调整”(占语料库中所有动作的44%)。我们的架构在设计时可以用于交互对话,而不仅仅是像引用的众包语料中IER实例那样的单一句子。因此,像撤销、重做、选择、合并和卷起等动作在我们的语料中都是不常见甚至完全没有出现的。对于实体,“属性”在标注表述出现次数占56%;“修改器/值”在32%的IER中被标注;“物体”在30%的表述中被标注;“区域”在60%的IER中被标注;“意图”出现在29%的重标注数据中。
4、方法
4.1 预处理
标注表述的语料库首先筛选为可执行动作。这一步中,我们移除了没有IER的表述,例如“这张照片应该是用尼康相机拍摄的”。带有“其他”动作的表述也被筛除出去(占语料库的0.01%)。被标为“其他”动作的IER包含某种程度的歧义以至于编辑请求不可能被执行,例如“把步行道清理干净”。用户想要把步行道编辑成一个统一的颜色达到满意水平,还是想要删除步行道上的叶子,这是不清楚的。我们把这个具体的动作留在日后进行调查。
我们选择了Glove(Pennington等,2014)把IER映射到向量来准备模型的输入。标注的实体序列被转化成BIO(头中尾)序列。例如,对于表述“裁剪图片”,将被标注为[IER: [动作-裁剪:“裁剪”] [位置:“图片”]],将成为一个O结尾,B开头-位置,I中间-位置。嵌套实体例如“添加一个更暖的色彩”中,“暖”既没有属性标签也没有值标签,展示了因为可能存在高深度嵌套,嵌套实体在BIO实体中一个重要的考虑因素。嵌套实体占语料库中所有实体的4%,因此在测试集出现而在训练集没有出现的嵌套深度是可能存在的。当遇到超出训练数据的新型嵌套实体深度时,两种模型在调研这个问题时都失败了。但是,使用最深实体可以使得图片编辑系统依旧能够对新型多层嵌套的表述做出响应,尽管会面临不完整的结果。由于所有的标签都具有同样的重要性,并且对于嵌套标签没有标注顺序,所以我们预期效果将和最终使用的任意嵌套深度相似。基于这些原因,我们暂且使用最深标签的处理方法。
最后,通过从语料库中随机选择表述来创建固定的表述训练集和测试集。对于动作,训练集包含4958个表述(语料库的75%),测试集包含1584个表述。实体数据被划分为训练集(占语料库的80%),验证集(10%)和测试集(10%)。
4.2 模型结果
我们的预测模型包含两层结构。第一层只把IER中的动作分类,分类的结果被传递入第二层,第二层仅检测实体的顺序。我们提出把模型分层可以剔除引起执行动作歧义的IER,因此也就避免了这些表述在后续步骤中产生进一步干扰和处理。
在第一层给动作分类的步骤中,我们以TensorFlow为后端评估了现有技术长短时记忆(LSTM)模型并将之与三个基准算法进行比较:支持向量机(SVM),逻辑回归和随机森林算法。所有这些基准算法模型都是在Python中使用Scikit Learn包来实现的。在第二层中要检测一个IER中的实体,我们把Scikit Learn中默认参数的卷积随机场算法(CRF)作为基准(也就是L-BFGS训练算法)将其与最新算法模型BiLSTM-CRF(Lample等, 2016)进行比较。BiLSTM-CRF把一个双向LSTM与一个CRF模型相结合。之前的实验表明了这种模型通过限制经由LSTM组件输出标签的独立性来改善突破CRF局限的能力。我们使用了BiLSTM-CRF的默认参数。
5、结果
5.1 动作
这项任务测得的最好F1分数是LSTM和SVM模型得出的(如表2所示)。一个原因是极其不均衡的数据集可能会导致问题,也就是所有的表述都会被分到多数的“调整”这个动作类别中。但是如图2的混淆矩阵所证,LSTM模型(图2上)以高准确性正确分类的少数类别,例如“旋转”动作尽管在数据集中出现频次低,其大多数情况都被正确分类。SVM算法(图2混淆矩阵下图)在正确分类多数标签时不够鲁棒,但却在预测其他最大三个类别(添加、裁剪、删除)时比LSTM模型表现更好。
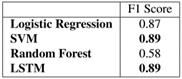
表2 每个机器学习模型进行动作标签分类的准确性
5.2 实体
对于实体,我们对仅使用最深实体和所有嵌套实体进行的实验比较。表3 给出了正确被一个表述翻译成可执行实体序列的正确率结果。
结果表明对于最深实体最新算法BiLSTM-CRF的性能大体上比基准CRF模型好。这表明了BiSLTM-CRF通过实行对于BiLSTM组件的限制对改善整体模型的的排序能力有明显效果。
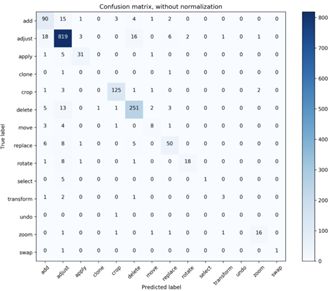
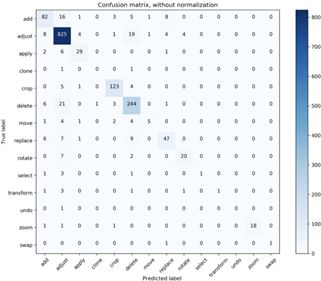
图2 SVM(上)和LSTM(下)的混淆矩阵

表3 对实体分类标签的F1分数
6、结论和展望
本文提供了通过自然语言交流来自动编辑图片的第一步研究。我们通过标注Edit Me语料库中剩余部分,并且对于之前标注存在分歧的表述进行了重新标注,对该语料库做出改进和贡献。我们也对一个处理编辑请求的分类动作类型和给实体排序的两层系列进行了评估,结论是分类动作类别时SVM模型和LSTM模型表现相当,并且BiLSTM-CRF模型在为嵌套实体的最深标签进行排序的任务上比其他基准模型表现更好。未来的工作中,我们计划研究一个可以同时预测动作类型和实体的联合模型。此外,两层的动作实体模型可以被应用在图像编辑交互对话中来进一步探索迁移学习技术。最后,在许多例子中,实体在最终可以被执行前都需要进一步划分解析。我们把解析模糊实体作为未来可以改进的工作。
7、参考文献
Antol, S., Agrawal, A., Lu, J., Mitchell, M., Batra, D., LawrenceZitnick, C., and Parikh, D. (2015). VQA: Visual Question Answering. InProceedings of the IEEE International Conference on Computer Vision, pages2425–2433, Santiago, Chile.
de Vries, H., Strub, F., Chandar, S., Pietquin, O., Larochelle, H.,and Courville, A. (2016). GuessWhat?! visual object discovery throughmulti-modal dialogue. arXiv preprint arXiv:1611.08481.
Huang, T.-H. K., Ferraro, F., Mostafazadeh, N., Misra, I., Agrawal,A., Devlin, J., Girshick, R., He, X., Kohli, P., Batra, D., Zitnick, C. L.,Parikh, D., Vanderwende, L., Galley,M.,andMitchell,M. (2016).Visualstorytelling. InProceedingsoftheNorthAmericanChapteroftheAssociation forComputational Linguistics - Human Language Technologies (NAACL-HLT), pages1233–1239, San Diego, California, USA.
Kulkarni, G., Premraj, V., Ordonez, V., Dhar, S., Li, S., Choi, Y.,Berg, A. C., and Berg, T. L. (2013). Babytalk: Understanding and generatingsimple image descriptions. IEEE Transactions on Pattern Analysis and MachineIntelligence, 35(12):2891–2903.
Lample, G., Ballesteros, M., Subramanian, S., Kawakami, K., andDyer, C. (2016). Neural architectures for named entity recognition. InProceedings of NAACLHLT, pages 260–270.
Laput, G. P., Dontcheva, M., Wilensky, G., Chang, W., Agarwala, A.,Linder, J., and Adar, E. (2013). Pixeltone: a multimodal interface for imageediting. In Proceedings of the SIGCHI Conference on Human Factors in ComputingSystems, pages 2185–2194. ACM.
Manuvinakurike, R., Brixey, J., Bui, T., Chang, W., Kim, D. S.,Artstein, R., and Georgila, K. (2018). Edit me: A corpus and a framework forunderstanding natural language image editing. In Proceedings of LREC 2018,Miyazaki, Japan.
Mostafazadeh, N., Misra, I., Devlin, J., Mitchell, M., He, X., andVanderwende, L. (2016). Generating natural questions about an image. InProceedings of the Annual Meeting of the Association for ComputationalLinguistics (ACL), pages 1802–1813, Berlin, Germany.
Mostafazadeh, N., Brockett, C., Dolan, B., Galley, M., Gao, J.,Spithourakis, G., and Vanderwende, L. (2017). Image-grounded conversations:multimodal context for natural question and response generation. In Proceedingsof the International Joint Conference on Natural Language Processing (IJCNLP),Taipei, Taiwan.
Paetzel, M., Manuvinakurike, R., and DeVault, D. (2015).“So,whichoneisit?” Theeffectofalternativeincremental architectures in ahigh-performance game-playing agent. In Proceedings of the Annual Meeting ofthe Special Interest Group on Discourse and Dialogue (SIGDIAL), pages 77–86,Prague, Czech Republic.
Pennington, J., Socher, R., and Manning, C. (2014). GLoVe: Globalvectors for word representation. In Proceedings of the 2014 conference onempirical methods in natural language processing (EMNLP), pages 1532– 1543.
历史文章推荐:
以上是关于基于自然语言命令的自动图频编辑系统(附pdf)的主要内容,如果未能解决你的问题,请参考以下文章