浅析自然语言理解之统计语言模型
Posted 萤火虫程序员沙龙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅析自然语言理解之统计语言模型相关的知识,希望对你有一定的参考价值。
本文由Emotibot出品,作者为技术专家王海波。
Emotibot致力于打造中国首款人工智能伴侣,以情感计算研究为核心,深度学习等尖端技术为基础,满足广大用户的日常生活和工作所需。
前言
在人机对话系统中,一个重要的问题是如何判断一串文字序列是否是人可以理解的或者人们在日常生活中会表达出来的句子。比如,文字序列“麻辣香锅味道不错,很多人都喜欢吃”是一个正常的句子;文字序列“吃欢喜都人多很,错不道味锅香辣麻”就比较费解一些,因为很少有人会这么反着讲话;而文字序列“吃欢都锅人喜辣多,很错道味不香麻” 无论怎样理解都难以讲通,更遑论解读出其中的意思,进而进行有效的沟通了。
这个问题之所以重要,是因为它在人机对话系统中存在广泛的应用。比如用户用语音进行交互。对话系统首先需要进行语音识别,弄清楚用户的输入之后才能进一步交互。在语音识别中,“不想玩”和“不想王”的发音比较接近,到底该识别成哪一个呢?在日常用语中,很少有人会说“不想王”,而说“不想玩”的比较多。结合上下文是在谈论是否玩游戏,识别成“不想玩”的概率比“不想王”的概率应当要大得多。
又比如用户输入一张图片,人机对话系统需要理解该图片在讲些什么,在必要的时候还需要给出对图片的描述。如果用户输入下面的图片[2]:

系统识别到了里面有两只海豚,那么描述 “两只海豚在进行水上表演”比“两个人在水上飞翔”显然是更加合适。这些识别出的信息提供了衡量上面两句话在该场景中合理程度的依据。
在人机对话系统中,对话生成模型生成的对话需要像人讲出来的一样,不能是难以解读甚至违反常识的句子。比如对于“今天天气如何”这样的回应,生成“今天天气不错,多云,最低温度15度,最高温度25度”这样通顺的句子比生成“今气不天天错, 最低度15度温,高温度最 25度多云”这样不通顺的句子要好很多。如果我们能够衡量一个句子的通顺程度,就可以给对话生成模型提供反馈,使得模型的输出能够保持较高对话的质量。
这些例子说明了计算机能够衡量一个句子的合理性是多么重要。那么如何衡量一个句子是否合理?用什么样的方法来计算句子的合理性呢?为了解决上述问题,人们最常用到的工具就是统计语言模型。
统计语言模型
什么是统计语言模型呢?通俗地说,统计语言模型描述了一串文字序列成为句子的概率。假设文字序列S由单词w1,w2,...wn组成,则该文字序列构成句子的概率P(S)可以由下面的公式进行计算[1,4]:
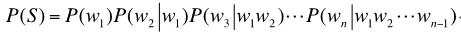
即
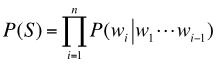
其中P(w1)表示第一个单词w1出现的概率,P(w2|w1)是在已知第一个词w1出现的情况下,第二个词w2出现的概率;同理,P(wi|w1,...,wi-1)是在序列wi,...,wi-1出现的情况,出现第i个词wi的概率。如何计算P(wi|w1,...,wi-1)呢?最简单的方法是使用极大似然估计(Maximum LikelihoodEstimate,MLE)。根据贝叶斯公式,我们可以得到:
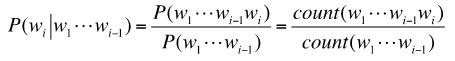
其中count(w1,...,wi)表示序列w1,...,wi在语料库中出现的频率。为了计算P(wi|w1,...,wi-1)我们需要一个语言词典,把前面i-1种单词组合的可能性都要考虑一遍。假设语料库里面有N个单词,i-1种单词的组合一共有N的i-1次方中排列方式。可以看到,随着i的增大,需要计算的可能性呈指数增长。
为了简化计算,人们通常采用马尔科夫假设 (Markov Assumption),即语言中的任意一个单词出现的概率只与其前面个N-1单词有关。
这个假设也叫作N阶马尔科夫假设。在这个假设之下,
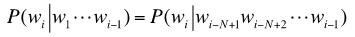
对应的统计语言模型被称之为N元模型(N-Gram Language Model)。
一元模型是最简单的模型。在一元模型之下, 可以表示为:
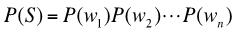
二元模型也叫作Bigram model。在该模型之下,
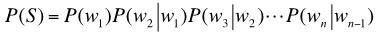
三元模型也称作Trigram model。在该模型之下,
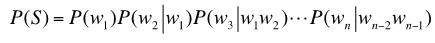
人们实际应用最多的是的三元模型,更高阶的模型就用得比较少了。主要有两方面的原因:一是阶数越高,计算量越大,潜在的计算量呈指数增长;二是高阶模型会面临严重的数据稀疏问题。况且,更高阶的模型并不一定能够覆盖所有的语言现象,一个典型的例子是单词之间的依赖关系[3]。在自然语言中,上下文之间的相关度有可能跨度非常大,甚至可以从一个段落跨到另一个段落,远远超过模型的窗口。高阶模型在这种长距离依赖的情形之下就变得无能为力了,这也是马尔科夫假设的局限所在。
本文接下来要介绍的递归神经网络语言模型可以用来解决这种长距离依赖关系。
递归神经网络语言模型
递归神经网络语言模型(Recursive Neural Network Language Model, RNN-LM)是一种非马尔科夫模型[2]。该模型直接建模了语言模型的条件概率:
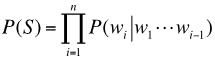
具体地说,该模型使用递归来构造两个函数,一个是特征抽取函数 ,另一个是条件概率计算函数g,即
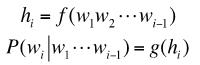
其中h1是隐藏状态,编码了从w1到wi-1的所有历史信息。计算函数h根据hi即可计算出第i时刻的条件概率P(wi|w1,...,wi-1)。下图形象地表示了这个计算过程。
例如,我们要计算P(w1,w2,w3,w4),
具体的计算过程如下:
初始化h1=0 =>P(w2|w1)=g(h2)
递归
(1) h2=f(h1,w1)=>P(w2|w1)=g(h2)
(2) h3=f(h2,w2)=>P(w3|w1w2)=g(h3)
(3) h4=f(h3,w3)=>P(w4|w1w2w3)=g(h4)
组合P(w1w2w3w4)=g(h1)g(h2)g(h3)g(h4)
在实际使用中,特征抽取函数通常采用函数,条件概率计算函数通常采用softmax函数。由于多个连续概率的乘积会变得非常微小,以至于会严重影响数值计算的精度,人们通常使用log概率(Log-Probability)来进行计算,如下:
递归神经网络语言模型的一大优点在于克服了N-Gram语言模型因为依赖马尔科夫假设而存在的局限性。在日常应用中,N-Gram语言模型最令人诟病的地方在于其统计特征只依赖于该词汇前面的有限个词汇;一旦N给定,其依赖关系的窗口也就固定了。在这种情形下,N-Gram模型对于超出窗口之外的依赖关系就无法建模了。而递归神经网络语言模型则不存在这个问题。事实上,递归神经网络语言模型可以处理任意长度的序列 ——该模型可以将过去的历史信息编码在隐藏层。正是由于这种记忆能力,递归神经网络语言模型得以在今天的自然语言处理任务中获得广泛运用;从手写识别、拼写纠错、语音识别,到机器看图说话、统计机器翻译、 自动问答以及人机对话系统中的语言生成等,都有该模型的影子。
结语
在人机对话系统中,一个最基本的自然语言理解问题是判断一个句子的可能性大小。通过将这种可能性建模成句子的统计概率,统计语言模型漂亮地解决了该问题。
[参考文献]:
[1].Language Model, https://en.wikipedia.org/wiki/Language_model
[2].Deep Natural LanguageUnderstanding,http://videolectures.net/deeplearning2016_cho_language_understanding/
[3].吴军,《数学之美》,人民邮电出版社,2014
[4].[我们是这样理解语言的-2]统计语言模型,http://www.flickering.cn/nlp/2015/02/%E6%88%91%E4%BB%AC%E6%98%AF%E8%BF%99%E6%A0%B7%E7%90%86%E8%A7%A3%E8%AF%AD%E8%A8%80%E7%9A%84-2%E7%BB%9F%E8%AE%A1%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B/
以上是关于浅析自然语言理解之统计语言模型的主要内容,如果未能解决你的问题,请参考以下文章