自然语言工具包入门
Posted Python与AI技术汇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言工具包入门相关的知识,希望对你有一定的参考价值。
NLTK 是使用 Python 教学以及实践计算语言学的极好工具。此外,计算语言学与人工 智能、语言/专门语言识别、翻译以及语法检查等领域关系密切。
NLTK 包括什么
NLTK 会被自然地看作是具有栈结构的一系列层,这些层构建于彼此基础之上。那些熟悉人工语言(比如 Python)的文法 和解析的读者来说,理解自然语言模型中类似的 —— 但更深奥的 —— 层不会有太大困难。
尽管 NLTK 附带了很多已经预处理(通常是手工地)到不同程度的全集,但是概念上每一层 都是依赖于相邻的更低层次的处理。首先是断词;然后是为单词加上 标签;然后将成组 的单词解析为语法元素,比如名词短语或句子(取决于几种技术中的某一种,每种技术都有其优缺点); 最后对最终语句或其他语法单元进行分类。通过这些步骤,NLTK 让您可以生成关于不同元素出现情况 的统计,并画出描述处理过程本身或统计合计结果的图表。
在本文中,您将看到关于低层能力的一些相对完整的示例,而对大部分高层次能力将只是进行简单抽象的描述。 现在让我们来详细分析文本处理的首要步骤。
断词(Tokenization)
您可以使用 NLTK 完成的很多工作,尤其是低层的工作,与使用 Python 的基本数据结构来完成相比,并 没有 太 大的区别。不过,NLTK 提供了一组由更高的层所依赖和使用的系统化的接口,而不只是 简单地提供实用的类来处理加过标志或加过标签的文本。
具体讲, nltk.tokenizer.Token 类被广泛地用于存储文本的有注解的片断;这些 注解可以标记很多不同的特性,包括词类(parts-of-speech)、子标志(subtoken)结构、一个标志(token) 在更大文本中的偏移位置、语形词干 (morphological stems)、文法语句成分,等等。实际上,一个 Token 是一种 特别的字典 —— 并且以字典形式访问 —— 所以它可以容纳任何您希望的键。在 NLTK 中使用了一些专门的键, 不同的键由不同的子程序包所使用。
让我们来简要地分析一下如何创建一个标志并将其拆分为子标志:
清单 1. 初识 nltk.tokenizer.Token 类
概率(Probability)
对于语言全集,您可能要做的一件相当简单的事情是分析其中各种 事件(events) 的 频率分布,并基于这些已知频率分布做出概率预测。NLTK 支持多种基于自然频率分布数据进行概率预测的方法。 我将不会在这里介绍那些方法(参阅 参考资料 中列出的概率教程), 只要说明您肯定会 期望的那些与您已经 知道的 那些(不止是显而易见的 缩放比例/正规化)之间有着一些模糊的关系就够了。
基本来讲,NLTK 支持两种类型的频率分布:直方图和条件频率分布(conditional frequency)。nltk.probability.FreqDist 类用于创建直方图;例如, 可以这样创建一个单词直方图:
清单 2. 使用 nltk.probability.FreqDist 创建基本的直方图

概率教程讨论了关于更复杂特性的直方图的创建,比如“以元音结尾的词后面的词的长度”。 nltk.draw.plot.Plot 类可用于直方图的可视化显示。当然, 您也可以这样分析高层次语法特性或者甚至是与 NLTK 无关的数据集的频率分布。
条件频率分布可能比普通的直方图更有趣。条件频率分布是一种二维直方图 —— 它按每个初始条件或者“上下文”为您显示 一个直方图。例如,教程提出了一个对应每个首字母的单词长度分布问题。我们就以这样分析:
清单 3. 条件频率分布:对应每个首字母的单词长度
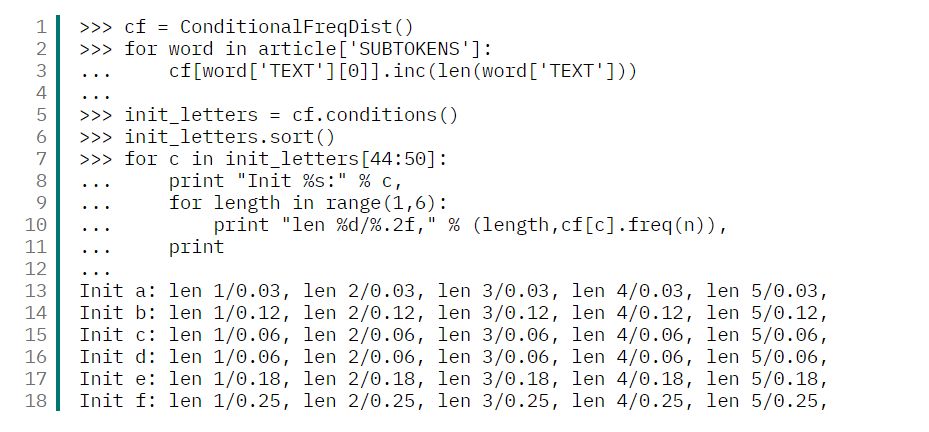
条件频率分布在语言方面的一个极好应用是分析全集中的语段分布 —— 例如,给出一个特定的 词,接下来最可能出现哪个词。当然,语法会带来一些限制;不过,对句法选项的选择的研究 属于语义学、语用论和术语范畴。
词干提取(Stemming)
nltk.stemmer.porter.PorterStemmer 类是一个用于从英文单词中 获得符合语法的(前缀)词干的极其便利的工具。这一能力尤其让我心动,因为我以前曾经用 Python 创建了一个公用的、全文本索引的 搜索工具/库(见 Developing a full-text indexer in Python 中的描述,它已经用于相当多的其他项目中)。
尽管对大量文档进行关于一组确切词的搜索的能力是非常实用的( gnosis.indexer 所做的工作), 但是,对很多搜索用图而言,稍微有一些模糊将会有所帮助。也许,您不能特别确定您正在寻找的电子邮件是否使用了单词 “complicated”、“complications”、“complicating”或者“complicates”,但您却记得那是大概涉及的内容(可能与其他一些 词共同来完成一次有价值的搜索)。
NLTK 中包括一个用于单词词干提取的极好算法,并且让您可以按您的喜好定制词干提取算法:
清单 4. 为语形根(morphological roots)提取单词词干

实际上,您可以怎样利用 gnosis.indexer 及其衍生工具或者完全不同的索引工具中的词干 提取功能,取决于您的使用情景。幸运的是,gnosis.indexer 有一个易于进行专门定制的 开放接口。您是否需要一个完全由词干构成的索引?或者您是否在索引中同时包括完整的单词 和词干?您是否需要将结果中的词干匹配从确切匹配中分离出来?在未来版本的 gnosis.indexer 中我将引入一些种类词干的提取能力,不过,最终用户可能仍然希望进行不同的定制。
无论如何,一般来说添加词干提取是非常简单的:首先,通过特别指定 gnosis.indexer.TextSplitter 来从一个文档中获得词干;然后, 当然执行搜索时,(可选地)在使用搜索条件进行索引查找之前提取其词干,可能是通过定制 您的MyIndexer.find() 方法来实现。
在使用 PorterStemmer 时我发现 nltk.tokenizer.WSTokenizer 类确实如教程所警告的那样不好用。它可以胜任概念上的角色,但是对于实际的文本而言,您可以更好地识别出什么是一个 “单词”。幸运的是, gnosis.indexer.TextSplitter 是一个健壮的断词工具。例如:
清单 5. 基于拙劣的 NLTK 断词工具进行词干提取

查看一些词干,集合中的词干看起来并不是都可用于索引。很多根本不是实际的单词,还有其他一些是 用破折号连接起来的组合词,单词中还被加入了一些不相干的标点符号。让我们使用更好的断词工具 来进行尝试:
清单 6. 使用断词工具中灵巧的启发式方法来进行词干提取

在这里,您可以看到有一些单词有多个可能的扩展,而且所有单词看起来都像是单词或者词素。 断词方法对随机文本集合来说至关重要;公平地讲,NLTK 捆绑的全集已经通过 WSTokenizer() 打包为易用且准确的断词工具。要获得健壮的实际可用的索引器,需要使用健壮的断词工具。
添加标签(tagging)、分块(chunking)和解析(parsing)
NLTK 的最大部分由复杂程度各不相同的各种解析器构成。在很大程度上,本篇介绍将不会 解释它们的细节,不过,我愿意大概介绍一下它们要达成什么目的。
不要忘记标志是特殊的字典这一背景 —— 具体说是那些可以包含一个 TAG 键以指明单词的语法角色的标志。NLTK 全集文档通常有部分专门语言已经预先添加了标签,不过,您当然可以 将您自己的标签添加到没有加标签的文档。
分块有些类似于“粗略解析”。也就是说,分块工作的进行,或者基于语法成分的已有标志,或者基于 您手工添加的或者使用正则表达式和程序逻辑半自动生成的标志。不过,确切地说,这不是真正的解析 (没有同样的生成规则)。例如:
清单 7. 分块解析/添加标签:单词和更大的单位

所提及的分块工作可以由 nltk.tokenizer.RegexpChunkParser 类使用伪正则表达式来描述 构成语法元素的一系列标签来完成。这里是概率教程中的一个例子:
清单 8. 使用标签上的正则表达式进行分块

真正的解析将引领我们进入很多理论领域。例如,top-down 解析器可以确保找到每一个可能的产品,但 可能会非常慢,因为要频繁地(指数级)进行回溯。Shift-reduce 效率更高,但是可能会错过一些产品。 不论在哪种情况下,语法规则的声明都类似于解析人工语言的语法声明。本专栏曾经介绍了其中的一些: SimpleParse 、 mx.TextTools 、 Spark 和gnosis.xml.validity (参阅 参考资料)。
甚至,除了 top-down 和 shift-reduce 解析器以外,NLTK 还提供了“chart 解析器”,它可以创建部分假定, 这样一个给定的序列就可以继而完成一个规则。这种方法可以是既有效又完全的。举一个生动的(玩具级的)例子:
清单 9. 为上下文无关语法定义基本的产品
probabilistic context-free grammar(或者说是 PCFG)是一种上下文无关语法, 它将其每一个产品关联到一个概率。同样,用于概率解析的解析器也捆绑到了 NLTK 中。
关注后回复【入群】,和大家一起学习
商务合作/文章转载/投稿
以上是关于自然语言工具包入门的主要内容,如果未能解决你的问题,请参考以下文章