ACL 2018|斯坦福大学:用自然语言解释训练分类器
Posted 读芯术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ACL 2018|斯坦福大学:用自然语言解释训练分类器相关的知识,希望对你有一定的参考价值。
你和“懂AI”之间,只差了一篇论文
很多读者给芯君后台留言,说看多了相对简单的AI科普和AI方法论,想看点有深度、有厚度、有眼界……以及重口味的专业论文。
为此,在多位AI领域的专家学者的帮助下,我们解读翻译了一组顶会论文。每一篇论文翻译校对完成,芯君和编辑部的老师们都会一起笑到崩溃,当然有的论文我们看得抱头痛哭。
同学们现在看不看得懂没关系,但芯君敢保证,你终有一天会因此爱上一个AI的新世界。
这是读芯术解读的第120篇论文
ACL 2018 Long Papers
用自然语言解释训练分类器
Training Classifiers with Natural Language Explanations
斯坦福大学
Stanford University
本文是斯坦福大学发表于 ACL 2018 的工作,文章提出了一个用于训练分类器的框架BabbleLabble,解决传统精确分类器训练需要许多标签,但是每个标签只提供有限信息(二进制分类的一位)的问题。注释器为每个标记决策提供自然语言解释,语义解析器将这些解释转换为编程的标记函数,该函数为任意数量的未标记数据生成噪声标签,用于训练分类器。在三个关系抽取任务中,我们发现,通过提供解释而不是仅仅标签,用户能够更快地训练具有相当F1分数的分类器。

引言
获得标记数据集的标准协议是让人类注释者查看每个示例,评估其相关性,并提供标签(例如,二进制分类的正或负)。但是,每个示例只提供一个比特信息。这就引出了一个问题:如果注释者已经花费了大量的精力去阅读和理解一个例子,那么我们如何才能得到更多的信息呢?
以前的作品依赖于识别输入的相关部分,如标记特征、突出文本中的基本短语、或标记图像中的相关区域。但是,某些类型的信息不容易被简化为注释输入的一部分,例如缺少某个单词,或者存在至少两个单词。在这项工作中,我们挖掘自然语言的力量,并允许注释者通过自然语言解释为分类器提供监督。
特别地,我们提出了一个框架,其中注释器为它们分配给示例的每个标签提供自然语言解释(参见下图)。这些解释被解析为表示标记函数(LF)的逻辑形式,这些函数启发式地将示例映射到标签。然后,在许多未标记的示例上执行标记函数,从而产生大量的、弱监督的训练集,然后使用该训练集来训练分类器。

自然语言逻辑形式的语义分析是一个具有挑战性的问题,并且得到了广泛的研究。我们的主要发现之一是,在我们的设置中,即使一个简单的基于规则的语义分析器也足够,原因有三:首先,我们发现大多数不正确的LF都可以在语义上自动过滤掉(例如,它与相关的示例一致吗?)或者实用地(例如,它是否避免为整个训练集分配相同的标签?)第二,逻辑形式空间中靠近黄金LF的LF通常同样精确(有时甚至更精确)。第三,建立组合弱监督源的技术可以容忍一些噪声。其意义在于,我们可以在任务之间部署相同的语义解析器,而无需进行特定任务的训练。
我们的工作与Srivastava的工作最相似,Srivastava使用自然语言解释来训练分类器,但有两个重要的区别。首先,它们联合训练任务特定的语义解析器和分类器,而我们使用简单的基于规则的解析器。在第四节中,我们发现,在我们薄弱的监管框架中,基于规则的语义解析器和完美的解析器产生几乎相同的下游性能。其次,虽然他们使用解释的逻辑形式来直接产生提供给分类器的特征,但我们使用它们作为标记更大训练集的函数。我们发现使用函数比特征产生9.5F1的改进(26%的相对改进),并且F1分数随着可用的未标记数据的数量缩放。
我们在文献中的两个现有数据集和一个真实世界的用例上验证我们的方法,我们的生物医学合作者从文本中提取与帕金森病相关的蛋白激酶相互作用。根据经验我们发现,当用户提供自然语言解释而不是单个标签时,他们能够更快地训练具有可比F1分数的分类器,最高可达两个数量级。我们的代码和数据可以在http://Github. COM/HasyReals/Bable中找到。
模型
BabbleLabble框架将自然语言解释和未标记数据转换为标记噪声的训练集(参见下图)。有三个关键组件:语义解析器、过滤器组和标签聚合器。语义解析器将自然语言解释转换为表示标记函数(LF)的一组逻辑形式。过滤器组在不需要真正标签的情况下尽可能地去除不正确的LF。剩余的LF用于未标记的示例以产生标签矩阵。这个标签矩阵被传递给标签聚合器,它将这些潜在的冲突和重叠的标签组合为每个示例的一个标签。然后使用所得的标记示例来训练任意判别模型。

为了创建输入解释,用户查看未标记数据集D的一个子集S(其中|S|《|D|),并且为每个输入xi∈S提供一个标签yi和一个自然语言解释ei,这是一个解释该示例为什么应该接收该标签的句子。解释ei通常指的是示例的特定方面(例如,在图2中,特定字符串“his wife”的位置)。
语义解析器:语义解析器在二进制分类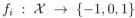 中,采用自然语言解释ei并返回一组LFs(逻辑形式或标记函数){f1,……., fk},其中0表示弃权。我们强调这个语义解析器的目标不是生成单个正确的解析,而是覆盖许多潜在有用的LFs。
中,采用自然语言解释ei并返回一组LFs(逻辑形式或标记函数){f1,……., fk},其中0表示弃权。我们强调这个语义解析器的目标不是生成单个正确的解析,而是覆盖许多潜在有用的LFs。
我们选择一个简单的基于规则的语义分析器,可以在没有任何训练的情况下使用。解析器使用一组形式为α→β的规则,其中α可以被β中的token替换(参见下图)。为了识别候选LF,我们基于语法规则定义的替换,为解释的每个跨度递归地构造一组有效的语法分析。最后,解析器返回与整个解释相对应的所有有效解析(在本例中为LFs)。
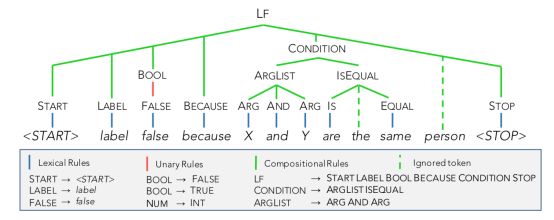
我们还允许在查找匹配规则时忽略给定跨度中任意数量的tokens。这提高了解析器处理意外输入(如未知单词或输入错误)的能力,因为可解析的输入部分仍然可以导致有效的解析。例如,在上图中,“person”一词被忽略。
语法中包括的所有谓词(下表)都提供给注释器,每个谓词的使用示例都很少。重要的是,所有规则都与域无关(例如,我们测试的所有三个关系提取任务都使用相同的语法),使得语义解析器易于转移到新的域。此外,虽然本文重点讨论关系提取的任务,但原则上BabbleLabble框架可以通过使用必要的基元扩展语法(例如,为行和列添加基元以便能够解释对齐器)来应用于其他任务或设置。单词表中的TS)。为了指导语法的构建,我们从Amazon Machinery Turk的工作人员那里收集了500个关于Spouse域的解释,并添加了对最常用谓词的支持。语法包含200个规则模板。

滤波器组:过滤器组的输入是由语义解析器生成的一组候选LFs。过滤器组的目的是在不需要附加标签的情况下丢弃尽可能多的不正确的LF。它包括两类过滤器:语义和语用。
回想一下,每一个解释ei都是在一个特定的标记实例(xi,yi)的上下文中收集的。语义过滤器检查与它们对应的例子不一致的LFs;对于f(xi)≠yi丢弃任意LF f。例如,在第二个图的第一个解释中,“right”一词可以被解释为“立即”(如“权利之前”)或者简单地“向右”。后一种解释导致与相关示例不一致的功能(因为“他的妻子”实际上在person 2的左边),因此可以安全地删除它。
实用过滤器去除了常数、冗余或相关的LFs。例如,在第二个图中,LF 2a是常数,因为它积极地标记每个示例(因为所有示例都包含来自同一句子的两个人)。LF 3b是冗余的,因为即使它具有与LF 3a不同的语法树,它也同样地标记训练集,因此不提供新的信号。
最后,在通过所有其他滤波器的相同解释的所有LF中,我们只保留最特定的(最低覆盖率)LFs。这防止多个相关的LFs从单个示例中占据主导地位。
标签聚合器:标签聚合器结合了来自LFs的多个(有可能冲突的)建议标签,并将它们组合成单个概率标签。具体地说,如果m LFs通过滤波器组并应用于n个实例,则标签聚合器实现函数f:{-1, 0, 1 }m×n→[0, 1 ]n。
本文使用数据编程将真实标签和标签输出的关系建模为因子图。给定真标记Y∈{1,1}n(潜在的)和标签矩阵(观察到的),其中,我们定义了表示标签倾向和准确性的两类因子:
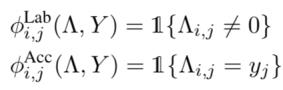
定义与一个给定数据点xj的向量为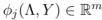 ,定义模型为:
,定义模型为:
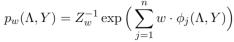
其中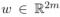 是权重向量,Zw是归一化常量。为了在不知道真正标签Y的情况下学习模型,我们最小化给定观测标签
是权重向量,Zw是归一化常量。为了在不知道真正标签Y的情况下学习模型,我们最小化给定观测标签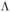 的负log边缘似然:
的负log边缘似然:
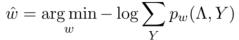
使用SGD和Gibbs采样进行推理,然后使用边缘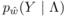 作为概率训练标签。
作为概率训练标签。
判别模型:利用标签聚合器输出的带噪声标签的训练集来训练任意的判别模型。在任务上训练判别模型而不是直接使用标签聚合器作为分类器的一个优点是,标签聚合器仅考虑LF中包括的那些信息。另一方面,判别模型可以结合用户未识别但信息量大的特征。因此,即使所有LF被弃用的例子也可以被正确分类。我们的评估结果显示,对于三个任务,使用判别模型高于直接使用标签聚合器4.3个F1点。
对于本文的结果,我们的判别模型是一个简单的逻辑回归分类器,具有定义在依赖路径上的一般特征。这些特征包括引理的一元、二元、三元文法、依存标签,以及在兄弟、父结点中发现的词性标签。我们发现,平均而言,这比biLSTM的性能更好,特别是对于训练集大小较小的传统监督的基线;它还提供了易于解释的特征用于分析。
实验与分析
我们评估了BabbleLabble在三种关系提取任务中的准确性,我们称之为Spouse, Disease和 Protein。每个任务的目标是训练用于预测示例中的两个实体是否具有兴趣关系的分类器,下表中报告了每个数据集的统计数据。
下图中给出了每个数据集的一个示例和一个解释。

我们根据用户输入的数量、对正确解析的逻辑形式的依赖以及使用逻辑形式的机制来评估BabbleLabble的性能。
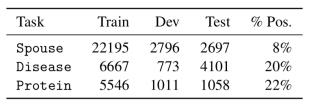
在下表中,我们报告使用BabbleLabble训练的分类器的平均F1得分,使用30种解释或具有指示标签数量的传统监督。平均来说,收集30个解释花费的时间与收集60个标签花费的时间相同。我们注意到,在所有三个任务中,BabbleLabble用比传统监督少得多的用户输入获得给定的F1分数,在Spouse任务的情况下多达100倍。因为解释被应用于许多未标记的示例,来自用户的每个单独输入可以隐式地为学习算法贡献许多(噪声)标签。
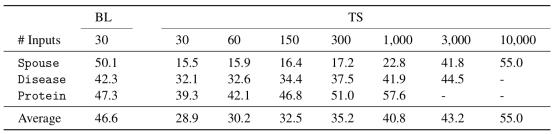
在下表中,我们报告过滤之前和之后的LF汇总统计。LF正确性指的是提取结果与每个手动生成的解析的精确匹配度。令人惊讶的是,简单的基于启发式的过滤器组在所有三个任务中成功地去除了超过95%的不正确LF,最终得到的LF集平均正确率为86%。此外,在通过过滤器组的那些LF中,我们发现正确和不正确解析之间的最终任务精度的平均差异小于2.5%。直观地,这些过滤器是有效的,因为从解释中解析LF、正确地标记自己的示例(通过语义过滤器)以及不用相同的标签或相同的标签标记训练集中的所有示例(通过语用文件)是非常困难的。
我们更进一步:使用由完美语义解析器生成的LF作为起点,我们在测试集上搜索具有更高端任务准确性的“附近”LF(LF仅与一个谓词不同),并且成功率为57%(参见下图)。

换句话说,当用户提供解释时,他们所描述的信息提供了良好的辅助,但是实际上它们不太可能是最佳的。下表进一步印证这种观察,它表明需要过滤器组来移除明显不相关的LF,简单的基于规则的语义解析器和完美的解析器具有几乎相同的平均F1分数。
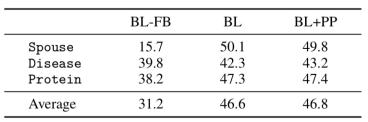
在下表中,我们直接比较这两种方法,发现数据编程方法与基于规则的解析器相比,性能优于基于特征的方法。
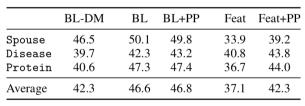
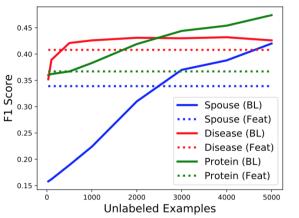
我们把这种差异主要归因于数据编程利用未标记数据的能力。在下图中,我们展示了数据编程方法如何随着未标记示例的数量而改进,即使LF的数量保持不变。我们还定性地观察到,数据编程将分类器暴露于与我们的解释相关但没有直接提到的附加模式。
总结
从机器学习的角度来看,标签是主要的资产,但它们提供了注释器和学习算法之间的较少的信息量。自然语言解释开辟了更多信息传输的通道。在关系抽取方面,本文已经显示了较好的结果(其中一种解释可以“比得上”100个标签),未来将我们的框架扩展到其他任务和更多交互式设置上将是一个非常有趣的研究方向。本文的代码、数据和实验可以在CodaLab平台上通过https://worksheets.codalab.org/worksheets/0x900e7e41deaa4ec5b2fe41dc50594548/获得。
论文下载链接:
http://aclweb.org/anthology/P18-1175
我们一起分享AI学习与发展的干货
推荐文章阅读
读芯君爱你
以上是关于ACL 2018|斯坦福大学:用自然语言解释训练分类器的主要内容,如果未能解决你的问题,请参考以下文章