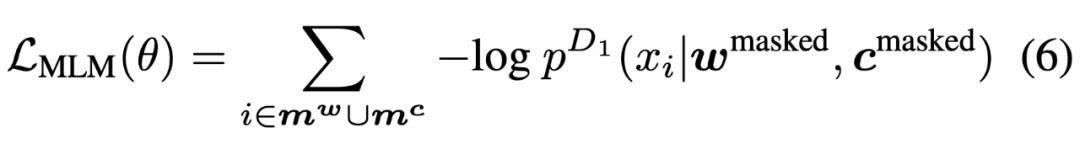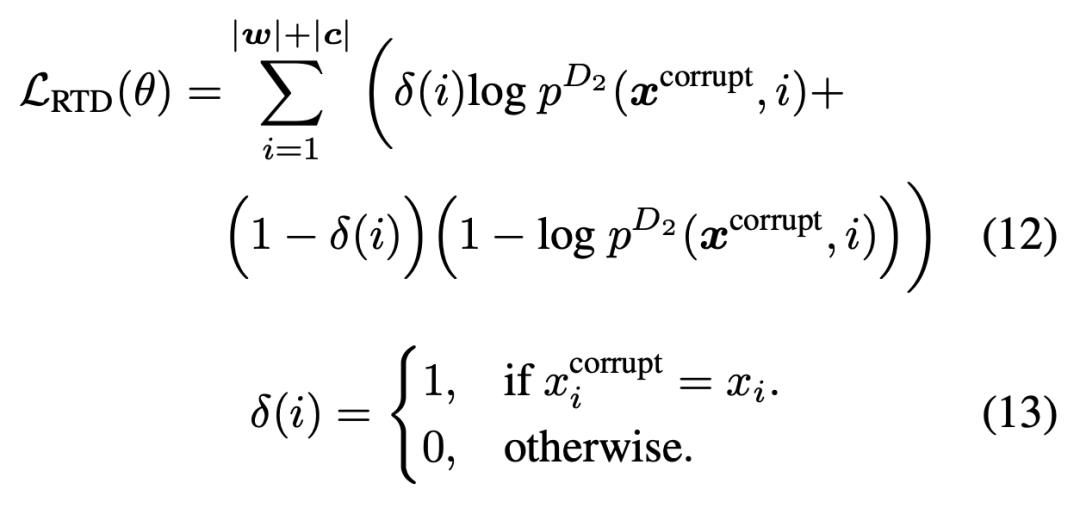新预训练模型CodeBERT出世,编程语言和自然语言都不在话下,哈工大中山大学MSRA出品 Posted 2021-04-12 221数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了新预训练模型CodeBERT出世,编程语言和自然语言都不在话下,哈工大中山大学MSRA出品相关的知识,希望对你有一定的参考价值。
来源: 机器之心
对于自然语言处理从业者来说,BERT 这个概念一定不陌生,自从诞生以来,它在诸多任务检测中都有着非常优秀的表现。近日,来自哈尔滨工业大学、中山大学和微软亚洲研究院的研究者合作提出了一个可处理双模态数据的新预训练模型 CodeBERT,除了自然语言(NL),编程语言(PL)如今也可以进行预训练了。
在这篇名为《CodeBERT: A Pre-Trained Model for Programming and Natural Languages》的论文中,来自哈工大、中山大学和微软的研究人员详细介绍了这一新预训练模型,该模型可处理双模态数据:编程语言(PL)和自然语言(NL)。
CodeBERT 学习能够支持下游 NL-PL 应用的通用表示,比如自然语言代码搜索、代码文档生成,经实验 CodeBERT 模型在两项任务均取得 SOTA 效果,同时研究者构建了 NL-PL 探测数据集,CodeBERT 在 zero-shot 设置中的性能表现也持续优于 RoBERTa。
论文链接:https://arxiv.org/abs/2002.08155
CodeBERT 模型使用基于 Transformer 的神经架构构建而成,训练所用的混合目标函数包括了替换 token 检测(replaced token detection,RTD)预训练任务。RTD 使用从生成器采样的合理替代 token 来替换部分输入 token 从而破坏输入,然后训练一个判别器来预测受损输入中的每个 token 是否被生成器样本替换。
这就使得 CodeBERT 模型可利用双模态数据 NL-PL 对和单模态数据,前者为模型训练提供输入 token,后者有助于学得更好的生成器,研究者通过模型调参的方式评估了 CodeBERT 在两个 NL-PL 应用中的性能。
CodeBERT 既能处理自然语言又能处理编程语言,比如 Python、Java、javascript
为了利用双模态数据实例 NL-PL 对和大量可用单模态代码,研究者使用混合目标函数来训练 CodeBERT,函数包括标准遮蔽语言建模(MLM)和替换 token 检测(RTD),替换 token 检测利用单模态代码学得更好的生成器,从而输出更好的替换 token。
研究使用了 6 种编程语言训练 CodeBERT,其中双模态数据点是具备函数级自然语言文档的代码。CodeBERT 模型的训练设置与多语言 BERT (Pires et al., 2019) 类似,即针对 6 种编程语言学习一个预训练模型,且不使用显式标记来标注输入编程语言。
研究者在两项 NL-PL 任务(自然语言代码搜索和代码文档生成)上评估了 CodeBERT 的性能。实验结果表明调参后的 CodeBERT 模型可在这两项任务上达到当前最优性能。为了进一步了解 CodeBERT 学得的知识类型,研究者构建了 NL-PL 探测数据集,并在 zero-shot 设置中测试 CodeBERT,即不对 CodeBERT 调参。测试结果表明,CodeBERT 的性能持续优于仅基于自然语言的预训练模型 RoBERTa。
以下内容将详细介绍 CodeBERT,包括模型架构、输入和输出表示、目标函数、训练数据,以及将 CodeBERT 应用于下游任务时应如何调参。
研究者遵循 BERT (Devlin et al., 2018) 和 RoBERTa (Liu et al., 2019),并使用了多层双向 Transformer 作为 CodeBERT 的模型架构。
具体而言,CodeBERT 的模型架构与 RoBERTa-base 基本一致,包括 12 个层,每一层有 12 个
自注意力 头,每个
自注意力 头的大小为 64。隐藏维度为 768,前馈层的内部隐藏层大小为 3072。模型参数总量为 1.25 亿。
在预训练阶段,研究者将输入设置为两个片段和一个特殊分隔符的组合,即 [CLS], w1, w2, ..wn, [SEP], c1, c2, ..., cm, [EOS]。其中一个片段是自然语言文本,另一个则是以某种编程语言写成的代码。
CodeBERT 的输出包括:1)每个 token 的语境向量表示(适用于自然语言和代码);2)[CLS] 的表示,作为聚合序列表示(aggregated sequence representation)。
研究者使用双模态数据训练 CodeBERT,即自然语言-代码对平行数据。此外,还使用单模态数据,即不具备平行自然语言文本的代码和不具备对应代码的自然语言。
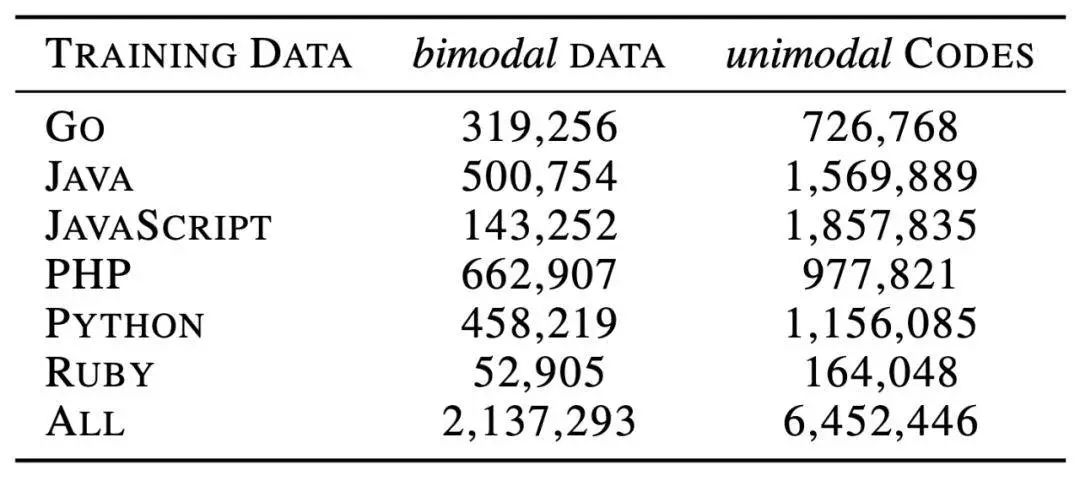
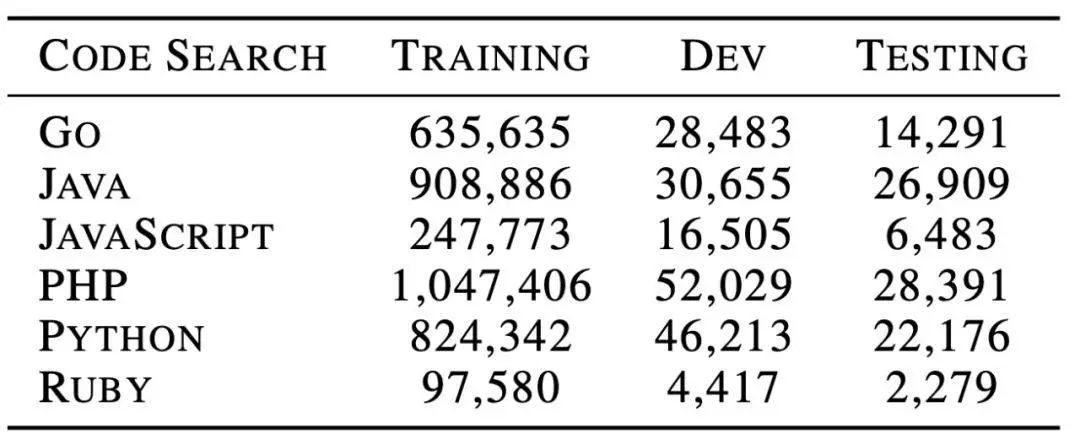
表 1:
CodeBERT 训练数据集的数据统计信息。
图 1:
NL-PL 对示例,其中 NL 是函数文档(黑色虚线框)中的第一段(红色框)。
本节将介绍训练 CodeBERT 使用的两个目标函数。
第一个目标函数是遮蔽语言建模(masked language modeling,MLM),MLM 在多项研究中被证明是有效的方法。研究者在双模态数据 NL-PL 对上应用遮蔽语言建模。
第二个目标函数是替换 token 检测(RTD),它使用大量单模态数据,如不具备对应自然语言文本的代码。
MLM 目标旨在预测被遮蔽的原始 token,其公式如下所示:
RTD 的
损失函数 如下所示,θ 表示判别器,δ(i) 表示指示函数,p^D2 表示预测第 i 个单词真实概率的判别器。
值得注意的是,RTD 目标应用于输入的每个位置,它与 GAN 的不同之处在于:如果生成器输出了正确的 token,该 token 的标签是「real」而非「fake」。
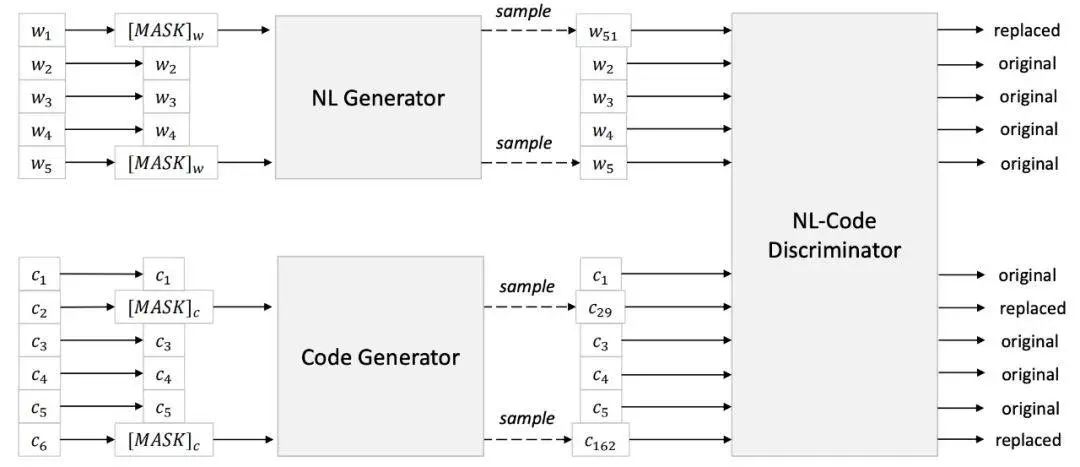
图 2:
RTD 目标图示。NL 生成器和代码生成器都是语言模型,它们基于上下文语境为遮蔽位置生成合理的 token。NL-Code 判别器是目标预训练模型,其训练方式是检测采样自 NL 和 PL 生成器的合理替换 token。NL-Code 判别器用于在调参阶段输出通用表示,而 NL 生成器和代码生成器均不出现在调参阶段。
这一部分内容将介绍 CodeBERT 的实验结果。首先使用 CodeBERT 进行自然语言代码搜索(对 CodeBERT 执行调参),然后在 NL-PL 探测任务中以 zero-shot 设置评估 CodeBERT 的性能(不对 CodeBERT 进行调参)。最后,研究者在生成问题(即代码文档生成任务)上评估 CodeBERT,并进一步使用训练阶段未见过的编程语言来评估 CodeBERT 的性能。
给定自然语言作为输入,代码搜索的目标是从一堆代码中找出语义最相关的代码。研究者在 CodeSearchNet
语料库 上进行实验。
表 3:
CodeSearchNet 语料库 的数据统计信息。
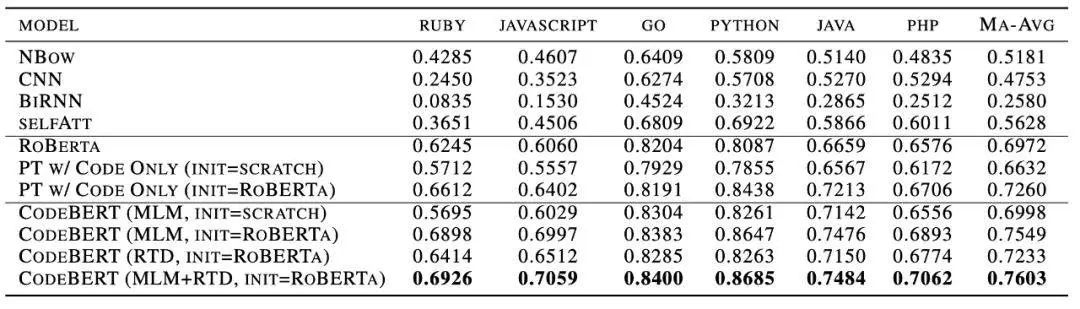
下表 2 展示了不同方法在 CodeSearchNet
语料库 上的性能结果。
表 2:
不同方法在自然语言代码检索任务中的结果。
基线包括四种 NL 和 PL 联合嵌入(第一组),RoBERTa 使用遮蔽语言建模在代码上执行训练(第二组),PT 表示预训练。
研究者使用不同设置训练 CodeBERT(第三组),包括不同的初始化和不同的学习目标。
给出一个 NL-PL 对 (c, w),NL-PL 探测的目标是测试模型在多个干扰词中准确预测/恢复感兴趣的遮蔽 token(代码 token c_i 或单词 token w_j)的能力。
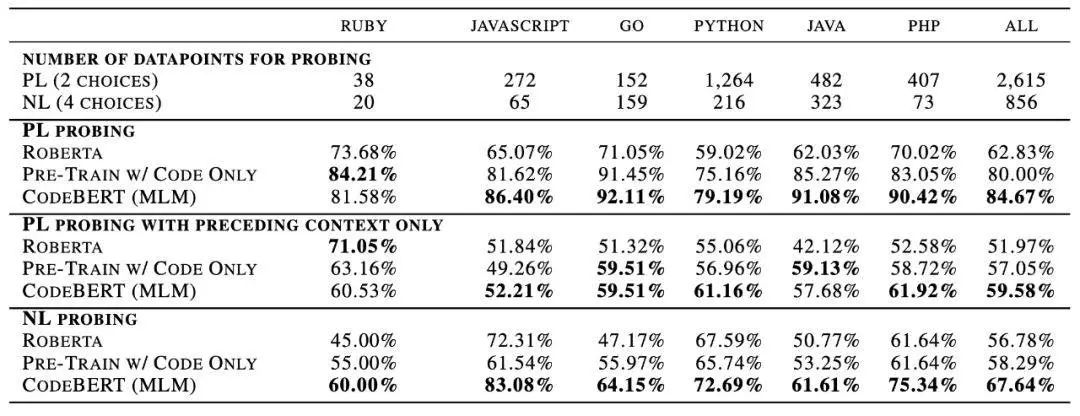
下表 4 展示了不同方法的准确率,即对于每种编程语言,模型准确预测的实例与全部实例数量的比例。表 4 前两行列举了数据统计信息。
表 4:
NL-PL 探测任务的数据统计信息,以及不同预训练模型的性能。
此表报告了模型的准确率(%),每一组中的最佳结果以加粗形式显示。
研究者进一步对 PL-NL 探测任务进行了案例研究。图 4 展示了 Python 代码示例。该示例分别遮蔽了 NL token 和 PL token,然后报告 RoBERTa 和 CodeBERT 的预测概率。
图 4:
PL-NL 探测任务案例研究(以 Python 语言代码为例)。
该示例分别遮蔽 NL token(蓝色)和 PL token(黄色),并报告了 RoBERTa 和 CodeBERT 的预测概率。
本节涉及 code-to-NL 生成任务,报告了在 CodeSearchNet
语料库 上六种编程语言的文档生成任务结果。
下表 5 展示了不同模型的代码-文档生成任务结果:
表 5:
代码-文档生成任务结果,该实验在 CodeSearchNet 语料库 上展开,得到的结果为平滑 BLEU-4 分数。
以上是关于新预训练模型CodeBERT出世,编程语言和自然语言都不在话下,哈工大中山大学MSRA出品的主要内容,如果未能解决你的问题,请参考以下文章