TF前沿推出 Semantic Reactor:让电子表格理解自然语言
Posted GDG
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TF前沿推出 Semantic Reactor:让电子表格理解自然语言相关的知识,希望对你有一定的参考价值。
文 / Dale Markowitz,应用 AI 工程师
机器学习有时可能很麻烦,因此,如果能快速创建 ML 应用的原型,绝对是一大福音。如需构建具有语言功能的应用(如可和玩家对话的游戏 NPC 或者客服机器人)Semantic Reactor 将是理想选择。
Semantic Reactor 是 Google 表格的新插件,让您可以基于自己的数据直接从电子表格运行自然语言理解 (NLU) 模型(Universal Sentence Encoder 变体)。
Semantic Reactor
https://gsuite.google.com/marketplace/app/semantic_reactor/509042860915Google 表格
https://www.google.com/sheets/about/Universal Sentence Encoder
https://ai.googleblog.com/2018/05/advances-in-semantic-textual-similarity.html
在本文中,我将介绍如何使用该工具及其所用的 NLU 模型,但首先要介绍的是 NLP 的工作原理以及它的支持技术(想直接了解工具使用?可跳过下一步部分)。
了解嵌入向量
什么是单词嵌入向量?
在机器学习中,嵌入向量是指一种通过在空间表示数据(如 n 维网格上绘制的点)以使点间距有意义的学习方式。单词向量是一种常见示例:
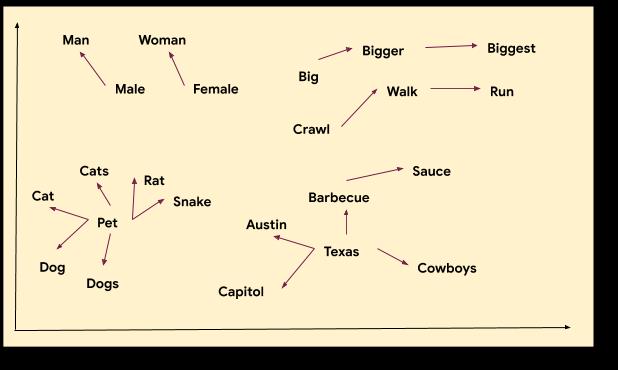
上图以可视方式描述了单词之间如何互相靠近或远离。请注意,“Austin”、“Texas”和“barbecue”等词之间关系密切,“pet”和“dog”、“walk”和“run”也是如此。每个单词都通过一组坐标(或一个向量)表示,呈现在关系图中。如上,我们可以看出单词“rat”与“pet”和“cat”关系密切。
这些量化来自哪里?它们是机器学习模型通过大量对话和语言数据而习得的。通过这些示例,模型会学习哪些单词通常出现在句子中的相同位置。
-
“My mother gave birth to a son.” “My mother gave birth to a daughter.”
因为“daughter”和“son”经常用在类似的上下文中,所以模型就会学习到,它们在空间中的表示应该互相靠近。单词嵌入向量在自然语言处理中很有用。它们可用于查找同义词(“语义相似度”)、解决类比或作为更复杂模型的预处理步骤。您可以使用 TensorFlow 快速训练自己的基本单词嵌入向量。
使用 TensorFlow 快速训练自己的基本单词嵌入向量
https://www.tensorflow.org/tutorials/text/word_embeddings
什么是句子嵌入向量?
Universal Sentence Encoder
https://ai.googleblog.com/2018/05/advances-in-semantic-textual-similarity.html
Semantic Reactor
-
本地版本 - 可完全在网页中运行的 Universal Sentence Encoder 的小型 TensorFlow.js 版本。 -
在线基本版本 - Universal Sentence Encoder 的全尺寸通用版本。 -
在线多语言版本 - 在 16 种语言的问题/答案对上训练的实际大小 Universal Sentence Encoder 模型。
-
本地版本
https://github.com/tensorflow/tfjs-models/tree/master/universal-sentence-encoder
在线基本版本
https://tfhub.dev/google/universal-sentence-encoder/4-
在线多语言版本
https://tfhub.dev/google/universal-sentence-encoder-multilingual-qa/3
-
语义相似度:两个文本块有多相似?
非常适合于您可以预测用户所提问题的应用,例如常见问题解答机器人。(许多客户服务机器人都使用语义相似度来帮助向用户提供合适的回答。)
-
输入/响应:一个文本块对另一个文本块的响应有多好?
适用于动态大量文本集但您又不知道用户可能询问什么的情况。例如, Talk to Books 是一个语义搜索工具,用于定期更新的 100,000 本书的收藏,它使用输入/响应。
-
Talk to Books
https://books.google.com/talktobooks/
您可以使用 Semantic Reactor 根据每种模型和排名方法测试响应列表。有时候,在得到您认为适合您的应用程序的响应列表和模型选择之前,需要进行一些测试。好消息是在 Google 表格中可以快速而简便地完成这些测试。
通过获取响应列表、选择模型和确定排名方法之后,您可以开始编写代码。如果您希望所有计算都在网站中或设备上运行(不需要在线 API 调用),可以使用最新更新的 TensorFlow.js 模型。
TensorFlow.js
https://github.com/tensorflow/tfjs-models/tree/master/universal-sentence-encoder
综上所述,NLU 技术有着众多出色的用途,每天都会涌现出许多更有趣的应用。每个智能助手、客户服务机器人和搜索引擎都可能利用某种机器学习。Gmail 中的“智能回复”和“智能撰写”是两个好用的功能,它们充分利用了语义技术。
但在质量要求不是很高、可以接受失败甚至有些娱乐性的应用中,使用语义技术不但很有趣,也很有用。为此,我们使用 Semantic Reactor 中相同的技术来创建多个示例游戏。Semantris 是一个词语联想游戏,使用输入-响应排名方法,而 The Mystery of the Three Bots 使用语义相似度。
Semantris
https://research.google.com/semantris/The Mystery of the Three Bots
https://google.github.io/mysteryofthreebots/
体验这两个游戏,并了解它们在哪些地方有效,这让您明白自己可能会创造什么样的体验。
Semantris,一个使用单词嵌入向量的词语联想游戏。
The Mystery of the Three Bots 是一个由 NLU 提供支持的简单游戏,以开源代码形式提供/体验
体验
https://google.github.io/mysteryofthreebots/
采用这项技术最酷的应用之一是来自 Anna Kipnis,她是 Double Fine 的前游戏设计师,现在就职于 Stadia。她使用 Semantic Reactor 为一款电子游戏设计原型,这款游戏使用 ML 推断环境应如何对玩家的输入做出反应。在这里查阅我们的对话。
“狐狸,我能喝点咖啡吗?”
-
“狐狸开灯。” -
“狐狸打开收音机。” -
“狐狸走向你。” “狐狸给你杯子。”
游戏使用句子编码器模型确定最佳响应,并执行该响应(本例中最佳响应是“狐狸给你杯子”,因此游戏会播放狐狸给你杯子的动画)。如果这听起来有点抽象,请一定要去观看上面链接的视频。
我们来看看如何使用 Semantic Reactor 构建像 Anna 的游戏这样的应用(要了解狐狸演示的全部细节,请参阅她的原创文章)。
原创文章
https://stadia.dev/intl/fr_ca/blog/creating-game-ai-using-mostly-english/
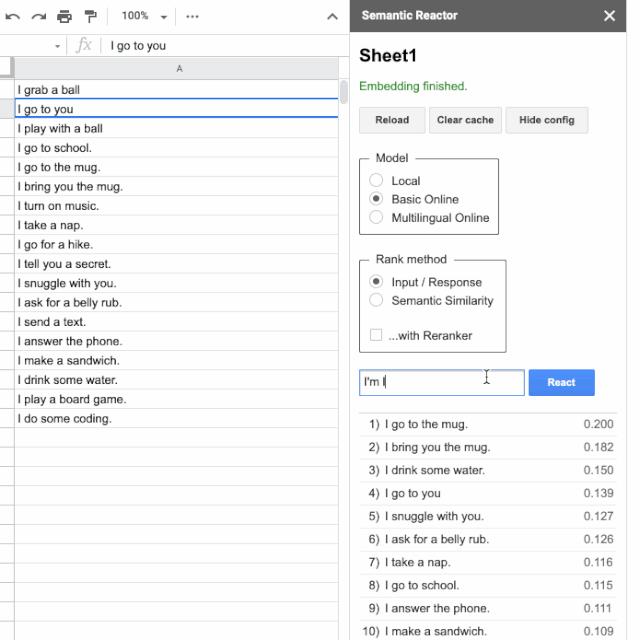
先新建一个 Google 表格,在第一列写一些句子。我在 Google 表格的第一列中输入以下句子:
I grab a ball
I go to you
I play with a ball
I go to school.
I go to the mug.
I bring you the mug.
I turn on music.
I take a nap.
I go for a hike.
I tell you a secret.
I snuggle with you.
I ask for a belly rub.
I send a text.
I answer the phone.
I make a sandwich.
I drink some water.
I play a board game.
I do some coding.
在这里必须运用您的想象力,思考潜在角色(如聊天机器人或电子游戏中的角色)可能执行的“动作”。
在申请并获得 Semantic Reactor 的使用权限后,你可以点击“Add-ons -> Semantic Reactor -> Start”来启用它。
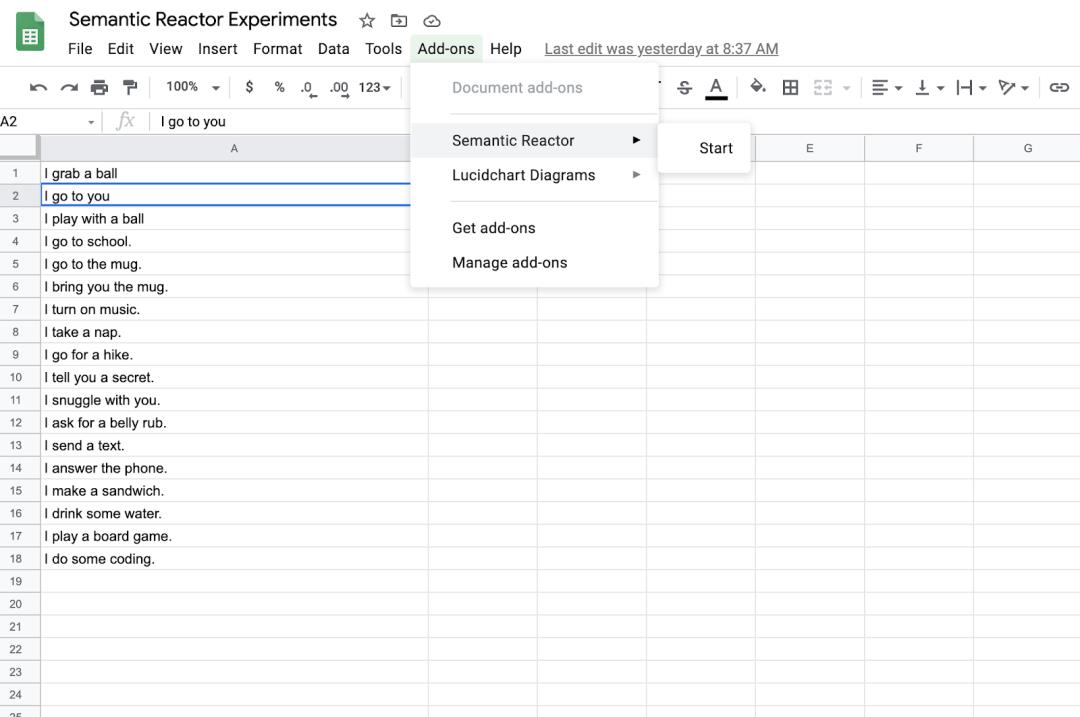
随后会打开一个面板,您可以在这里输入,然后点击“React”:
点击“React”时,Semantic Reactor 会使用模型将您在第一列中输入的所有句子进行嵌入,计算得分(这个句子对查询的响应有多好?),然后对结果分类。例如,当我的输入是“I want some coffee”,电子表格中排名最高的响应是“I go to the mug”和“I bring you the mug”。您还会注意到,使用此工具对句子排名有两种不同的方式:“输入/响应”和“语义相似度”。顾名思义,前者按响应适合给定查询的程度对句子排名,而“语义相似度”只是评价句子与查询的相似度。
使用 TensorFlow.js 转换为代码
在处理过程中,Semantic Reactor 采用这里的开源 TensorFlow.js 模型。
这里
https://www.npmjs.com/package/@tensorflow-models/universal-sentence-encoder
我们来看看如何在 javascript 中使用这些模型,以便将电子表格原型转换为实际应用。
1 - 创建一个新 Node 项目并安装模块:
npm init
npm install @tensorflow/tfjs @tensorflow-models/universal-sentence-encoder
2 - 创建新文件 (use_demo.js) 并加载库:
require('@tensorflow/tfjs');
const encoder = require('@tensorflow-models/universal-sentence-encoder');3 - 加载模型:
const model = await encoder.loadQnA();
4 - 对句子和查询编码:
const input = {
queries: ["I want some coffee"],
responses: [
"I grab a ball",
"I go to you",
"I play with a ball",
"I go to school.",
"I go to the mug.",
"I bring you the mug."
]
};
const embeddings = await model.embed(input);
5 - 成功!您已将响应和查询转换为向量。遗憾的是,向量只是空间中的点。要对响应排名,您需要计算这些点之间的距离(可通过计算点积来完成,得出点之间的平方欧几里得距离):
//zipWith :: (a -> b -> c) -> [a] -> [b] -> [c]
const zipWith =
(f, xs, ys) => {
const ny = ys.length;
return (xs.length <= ny ? xs : xs.slice(0, ny))
.map((x, i) => f(x, ys[i]));
}
// Calculate the dot product of two vector arrays.
const dotProduct = (xs, ys) => {
const sum = xs => xs ? xs.reduce((a, b) => a + b, 0) : undefined;
return xs.length === ys.length ?
sum(zipWith((a, b) => a * b, xs, ys))
: undefined;
}
如果运行此代码,输出应该如下所示:
[
{ response: 'I grab a ball', score: 10.788130270345432 },
{ response: 'I go to you', score: 11.597091717283469 },
{ response: 'I play with a ball', score: 9.346379028479209 },
{ response: 'I go to school.', score: 10.130473646521292 },
{ response: 'I go to the mug.', score: 12.475453722603106 },
{ response: 'I bring you the mug.', score: 13.229019199245684 }
]
请参阅这里的完整代码示例。
这里
https://github.com/google/making_with_ml/blob/master/semantic_ml/use_sample.js
从 Semantic ML 电子表格转换为代码就是这么快!
编者注:本文的早期版本已发布在 Dale 的博客上:https://daleonai.com/semantic-ml。
以上是关于TF前沿推出 Semantic Reactor:让电子表格理解自然语言的主要内容,如果未能解决你的问题,请参考以下文章
DRL前沿之:Benchmarking Deep Reinforcement Learning for Continuous Control
DRL前沿之:Benchmarking Deep Reinforcement Learning for Continuous Control
DRL前沿之:Benchmarking Deep Reinforcement Learning for Continuous Control