自然语言处理简介
Posted 笑笑的耕地记录
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理简介相关的知识,希望对你有一定的参考价值。

今天金泽下雪了。
哈哈,就不感叹大雪纷飞了。
咳咳
这个系列开始梳理之后,
本篇
可爱的笑笑本人决定
主要搞明白一下三点:
第一: 什么是自然语言处理
第二:自然语言处理的主要研究方向
第三:相关的统计学以及机器学习工具
哈哈哈,什么是自然语言处理呢。
Natural Language Processing 简称NLP。
自然语言处理是研究人与人交际中以及人与计算机交际中的语言问题的一门学科。自然语言处理要研制表示语言能力和语言应用的模型,建立计算框架来实现这样的语言模型
一般认为,自然语言处理中存在两种不同的研究方法,一种是理性主义方法,一种是经验主义方法。
理性主义的代表人物是乔姆斯基,主张建立符号处理系统,试图刻画人类思维的模型或方法,由人工编写自然语言处理规则。系统根据规则将自然语言理解为符号结构,再通过符号的意义推导出该结构的意义。
而经验主义认为,人脑并不是从一开始就具有一些具体的处理原则和对具体语言成分的处理方法,而是假定孩子的大脑一开始具有处理联想、模式识别和泛化处理的能力,这些能力能够使孩子充分利用感官输入来掌握具体的自然语言处理结构。
它涉及
• 语言学
• 语言心理学
• 逻辑学
• 计算机科学
• 人工智能
• 数学与统计学
等多门学科。
第二:自然语言处理的主要研究方向
• 自动作文评分
• 自动摘要
• 指代消解
• 语法错误纠正
• 字素音素转换
• 语种猜测语种辨别
• 语言建模
• 机器翻译
• 词形变化分析
• 词性标记
• 问答系统
• 关系提取
• 语义角色标注
• 情绪分析
• 语音身份分离
• 语音合成
• 语音文本转换
• 术语提取
• 文本语音转换
• 语法分析
• 词嵌入
• 词分割
• 词义消歧
• 图像释义
• 图像匹配
• 文本特征提取
• 文本相似度计算
第三:相关的统计学以及机器学习工具
熵
• 熵
• H(X)又称自信息,是描述一个随机变量不确定性大小的量,可以将熵看作是一个系统“混乱程度”的度量,熵越大则不确定性越大
• 联合熵
• 联合熵H(X,Y)就是描述两个随机变量X和Y所需要的信息量,联合熵大于或等于这两个变量中任一个的熵。
• 条件熵
• 条件熵H(Y|X)就是在已知X的条件下,Y的熵。
• 互信息
• 互信息I(X;Y)描述的是两个随机变量X和Y之间的相关性,也即已知X后,Y不确定性的减少量(熵H(Y)的减少量)
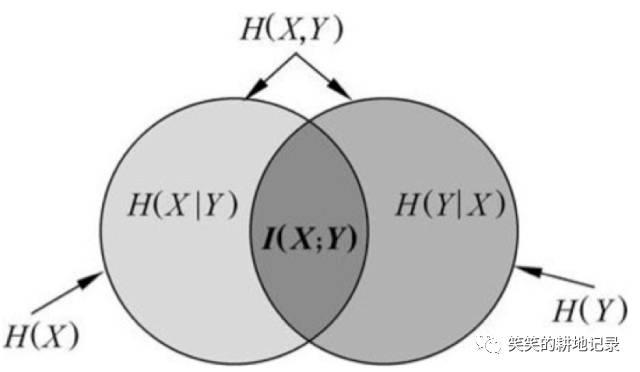
熵在自然语言处理中的应用
• 例如说应用在文本分类中,假设我们要判断一个词汇【和谐社会】与四个主题【经济】【运动】【政治】【军事】分别的相关性,便可以用互信息去解决
• 词汇事件的熵的计算是一个二元模型(由两个事件组成),即【该文档中含有该词汇】,【该文档中不含有该词汇】
• 主题事件的熵的计算是一个四元模型(由四个时间组成),即【该文档属于经济主题】.....
通过计算【和谐社会】这个词汇事件的熵和,【政治】这个主题事件熵的互信息便可以计算出【和谐社会】与【政治】主题的相关性。
语料库与语言知识库
• 语料库
• 语言知识库
• 可以分为两种不同的类型:一类是词典、规则库、语义概念库等,分别与解析过程中的词法分析、句法分析和语义分析相对应;另一类语言知识存在于语料库之中,每个语言单位的出现,其范畴、意义、用法都是确定的。
• 介绍一种知识库组织形式
• 知网
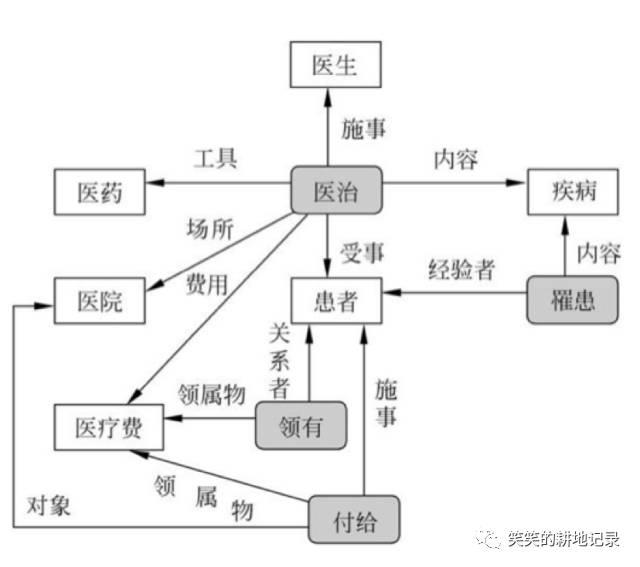
• 知网
• 反映了概念之间以及概念的属性之间的各种关系,通过对各种关系的标注,知网把这种知识网络系统明确教给了计算机,进而使知识对计算机而言成为可计算的。
• 知网定义了如下各种关系:上下位关系、同义关系、反义关系、对义关系、部件-整体关系、属性-宿主关系、材料-成品关系、施事/经验者/关系主体-事件关系(医生、雇主)、受事/内容/领属物等-事件关系(患者、雇员)、工具-事件关系(手表、计算机)、场所-事件关系(银行、医院)、时间-事件关系(假日、孕期)等等
神经网络
• 让我们来看一个经典的神经网络。这是一个包含三个层次的神经网络。红色的是输入层,绿色的是输出层,紫色的是中间层(也叫隐藏层)。
• 在自然语言中的应用:垃圾邮件识别
现在有一封电子邮件,把出现在里面的所有词汇提取出来,送进一个机器里,机器需要判断这封邮件是否是垃圾邮件
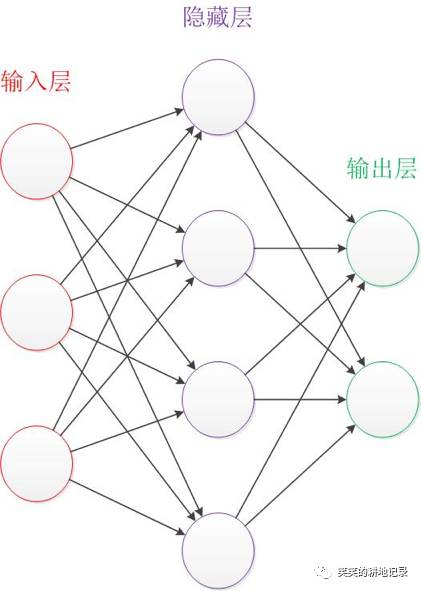
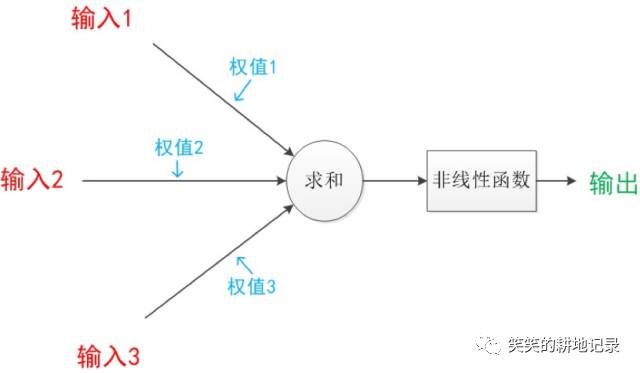
朴素贝叶斯算法
一种纯概率的方法,基于贝叶斯公式
还是以垃圾邮件分类为例子
• 这里的x是指词汇,c指邮件
• p(c|x):知道词汇x的情况下,c邮件是垃圾邮件的概率
• p(x|c):c是垃圾邮件的情况下,即指垃圾邮件中词汇x的出现概率
• p(c):是指垃圾邮件占总邮件数的比例
• p(x):是指词汇x在所有邮件的出现概率
马尔科夫模型
基于一个假设,即一个状态的判断至于其前一个时刻的状态有关。
如果一个系统有N个有限状态,那么随着时间的推移,该系统将从某一状态转移到另一个状态。
例如,一段文字中名词、动词、形容词三类词性出现的情况可由三个状态的马尔可夫模型描述:s1:名词、s2:动词、s3:形容词。假定状态之间的转移矩阵如下:

那么根据这一模型M,一个以名词开头的句子O的词性序列为名词、动词、形容词、名词的概率为:
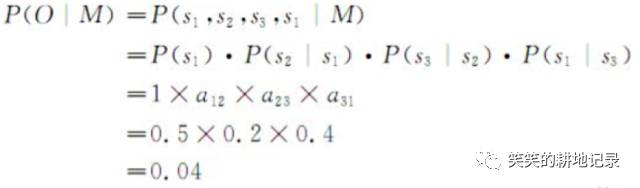
隐马尔科夫模型
• 一个有隐藏状态的马尔科夫模型
• 三个问题
• 已知词汇序列,以及各个转移概率,求该词汇序列成立的概率(判断句子是否合法)
• 已知词汇序列,以及各个转移概率,求其最优的词性序列(判断词汇词性)
• 已知词汇序列和词性序列,确定最优的转移概率(训练隐马尔科夫模型)
聚类方法
• k-means聚类算法
• k-means算法以k为参数,把n个对象分成k个簇,使簇内具有较高的相似度,而簇间的相似度较低。
• 层次聚类算法
• 凝聚型层次聚类的策略是先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到所有对象都在一个簇中,或者某个终结条件被满足。
• SOM聚类算法(忽略)
• FCM聚类算法(忽略)
SVM模型
• 是一种分类模型,分类与聚类的不同是,分类是有标准的,需要有已经分类过的数据去训练模型,而聚类不需要
• SVM模型的原理:想象一个高维空间,有很多点,现在想找出一个高维平面去把这些个点分为两部分,能够做到这个的就是SVM模型。
• 在自然语言处理中的应用:利用SVM、抽出日語中的固有表現。先把一个句子分成一个词汇列表,利用词汇的位置,词性,文字種之类的情报作为其特征向量,即用这些东西去定位一个词在高维空间中的位置。接着利用SVM去判定其是不是固有表现

自然语言处理的主要工具
形式语言
• 四类文法
• 0型语法(短语结构文法)
• 1型语法(上下文无关文法)
• 2型语法(上下文有关文法)
• 3型语法(正则文法)
• 形式语法
• G=(VN,VT,P,S)
• VT :终止符 :一个语言中的所有词汇的集合,不可再转化
• VN :非终止符 :基于基本词汇抽象的结构,可以转化为终止符
• P :重写规则 :转化规则
• S :句子 :句子
• 语法体系的一个简单例子
非终止符VN = {S, NP, VP, ART, N, V}
终止符VT = {the , a , boy , sees , cat}
重写规则
S→NP VP
VP→V NP
NP→ART N
ART→the | a
N→ boy| cat
V→saw
句子 The boy saw a cat
• 四类文法
• 0型语法(短语结构文法)
• 没有限制的语法,重写规则可以任意写,自然语言都是0型语言,但是难以用计算机处理
• 1型语法(上下文有关文法)
• 依据上下文的语法,即重写规则的被转化方中可以含有终止型
• 2型语法(上下文无关文法)
• 独立于上下文的语法,即重写规则的被转化方中不可以含有终止型,适合计算机处理,因此计算机在处理自然语言是采用此文法
• 3型语法(正则文法)
• 重写规则的转化方中必须含有终止型
句法分析
• 对于3型文法而言,其句法分析器称作[有限状态自动机]
• 对于2型语法而言,其句法分析器称作[上下文无关句法分析器]
• 句法分析器的功能:
• 确认输入句子是否可以由给定的语法来描述 , 即输入句子是否合乎给定的语法
• 识别句子各部分是如何依据语法规则组成合法句子 , 同时生成句法树
• 解决一部分的结构歧义
• 需要:
• 形式语法
• 句子
句法分析器
• 范畴语法CG
• 赋予每个词一个符号,符号与符号之间可以通过逻辑运算进行简约,最后一个完整的句子中,各个词汇简约之后,会得到S,这个代表着句子的符号。
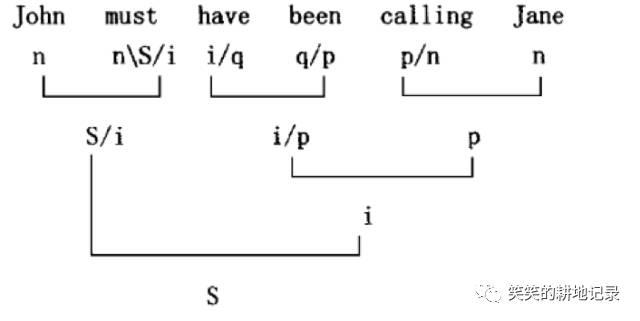
句法分析(概率上下文无关语法)
• 利用前述通常的上下文无关语法的句法分析算法 ,得到句子的句法分析树 ; 然后 , 为每个结点附带上一个概率值 , 每个结点的概率值就是对该结点进行进一步重写所使用的规则后面附带的概率。
• 例子:
Astronomers saw stars with ears

语义分析
目的:
• 为了解决语义带来的歧义
几个基本概念:
• 义位-义位关系(空间关系)
• 语义场(相当于一个词汇间义位关系的网络)
• 由于义位相互关联的方式不同 , 因此 , 构成的语义场也有多种。
• 义素分析(义素是比义位更基本的语义单位)
• 例:男人 = 男性+人
原型说
• 概念主要是以原型即它的最佳实例表征出来的
• 人们对一个概念的理解不仅包含着原型 , 而且也包含维量。
• 词义选择
• 论旨角色->格语法:给予每个词汇一个角色
指代消解
指代关系发生在涉及到同一个人或物的多个名词短语之间,是一种语用现象,受世界知识的约束对信息抽取至关重要:识别、跟踪事件中的参与者及其他信息
例:Hurricane Hugo destroyed 20000 Floridahomes. At an estimated cost of one billiondollars, the disaster has been the most costlyin the state’s history.
要解决例文中的指代关系,就必须知道hurricane是一种disaster
句义分析
句义 = 词义+词与词之间的组合方式
如何表示句义->形式化句义表示
构建词表表示词汇,词表中包含了词汇的语音信息,语法,语义信息等等->词义的建模
基于词表构建模型->组合方式
研究的对象实体D(把一些固有名词,代词,转换为一个实体)
映射函数F,为词表中的每一个词指派合适的语义值
例子:Marry loves Jack
实体D={d1,d2}
F(Marry) = d1 F(Jack) = d2 F(love)={d1,d2}love
构建逻辑表示语言,利用基本逻辑运算符号
Marry loves Jack and Jerry
实例展示
Sue laughs and opens the door .
-> (&
( LAUGHS1 E1 ( NAME s1“Sue” )
( OPENS1 E2 ( NAME s1“Sue” ) (OBJ o1“the door” ) )
)
)
句义分析器
HPSG理论(中心语驱动短语结构语法)
特殊的词汇特征结构
(词表格式)
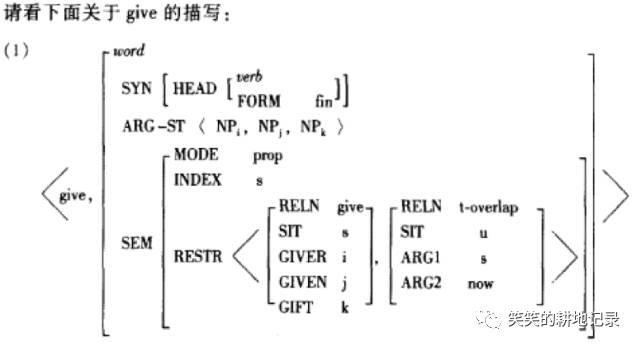
句法规则
HPSG的规则都是围绕中心语展开的
中心语~补足语规则,中心语-指定语规则....
语言理解的步骤
文本预处理
句子切分
形态分析(Morphological Analysis)
分词
词性标注(Part-of-Speech Tagging)
句法分析
词义消歧(Word Sense Disambiguation)
语义关系分析
指代消解(Anaphora Resolution)
逻辑形式(Logic Form)
Zipf统计定律
对于大量的低频词(N元对)来说,无论训练语料库的规模如何扩大,其出现频度依然很低或根本不出现,无法获得其足够的统计特性,用于可靠的概率估计。
向量空间模型
对文本内容的处理简化为向量空间中的向量运算,并且它以空间上的相似度表达语义的相似度,直观易懂。
相似度计算方式
余弦相似度
Jaccard相似系数
缺点
文档中词与词往往存在一定的关联性,信息检索的本质就是语义的检索,孤立的用关键字来表示文档内容,通过简单的词汇模式匹配进行检索,忽视上下文语境的影响作用
词嵌入(词向量模型)
将词汇符号化,数字化的一种方式
最直观的方式是one-hot向量:
这种方法把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个维度就代表了当前的词。
在经过语言模型处理后便可以得到词向量,将上面的很长的向量压缩为100维左右的向量
词向量可以做什么?
相似度计算,利用向量的内积
将机器学习引入自然语言处理
词汇类比任务,如king – queen = man - woman
......
语言模型
语言模型就是用来计算一个句子的概率的模型,即P(W1,W2,...Wk)。利用语言模型,可以确定哪个词序列的可能性更大,或者给定若干个词,可以预测下一个最可能出现的词语。广泛应用于各种自然语言处理问题,如语音识别、机器翻译、分词、词性标注。
p ( 我是一个学生) = p ( 我 , 是 , 一 , 个 , 学生 ) = p ( 我 ) ⋅p ( 是 | 我 ) ⋅p ( 一 | 我 , 是 ) ⋅p ( 个 | 我 , 是 , 一 ) ⋅p ( 学生 | 我 , 是 , 一 , 个 )
模型种类
n-gram
神经概率语言模型
解决歧义的神经概率语言模型
......
n-gram
它有一个有限历史假设:当前词的出现概率仅仅与前面n-1个词相关。
当n取1、2、3时,n-gram模型分别称为unigram、bigram和trigram语言模型。n-gram模型的参数就是条件概率P(Wi|Wi-n+1,...,Wi-1)。假设词表的大小为100000,那么n-gram模型的参数数量为100000的n次方。n越大,模型越准确,也越复杂,需要的计算量越大。最常用的是bigram,其次是unigram和trigram,n取≥4的情况较少。
缺点:
数据稀疏:
对于任何一种语言 , 通常只有部分常用词经常使用 , 这些词在一般的训练语料中出现的频次都比较高 ; 而 另 外有 大量 的是 不常 用 的词 , 这 些词 同时 出 现的 情况 会 更少。因此 , 对于一个确定的训练语料 , 即使规模相当大 , 也会有大量的词串没有同时出现 ,这就不可避免地会出现大量的估计值为 0 的条件概率
神经概率语言模型
神经概率语言模型利用了词向量和神经网络两个工具。
模型简介:输入为一个句子的前n-1个词的词向量,输出该句子第n个词的词向量。输入和输出之间含有大量参数。调整参数去提高预测的准确度。调整参数的方法是,利用大的语料库去训练。
最后可以通过前n个词经由网络得到的第n个词的向量与被预测词汇的词向量的距离,来判断其概率
解决歧义的神经概率语言模型
神经概率语言模型中的词向量,每个词对应一个向量,会产生词义的歧义,使结果不准确
改进方案为:先对某个词汇的共现词汇进行分类,分几类设其有几个义位,其次对每个义位赋予一个词向量,在进入神经概率语言模型进行训练。
哈哈哈终于完了。
以上是关于自然语言处理简介的主要内容,如果未能解决你的问题,请参考以下文章