最新Apache Spark平台的NLP库,助你轻松搞定自然语言处理任务
Posted 专知
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最新Apache Spark平台的NLP库,助你轻松搞定自然语言处理任务相关的知识,希望对你有一定的参考价值。
【导读】这篇博文介绍了Apache Spark框架下的一个自然语言处理库,博文通俗易懂,专知内容组整理出来,希望大家喜欢。
▌引言
Apache Spark是一个通用的集群计算框架,对分布式SQL、流媒体、图形处理和机器学习的提供本地支持。现在,Spark生态系统也有Spark自然语言处理库。
从GitHub开始或从quickstart 教材开始学习:
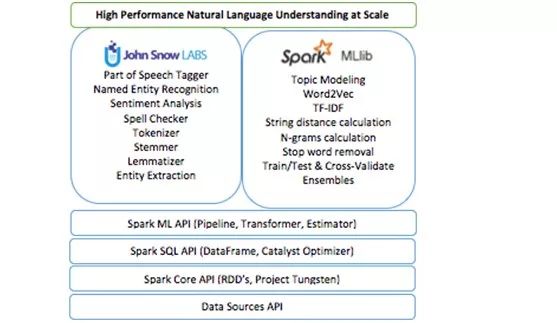
John Snow Labs NLP库是在Apache 2.0许可下,他是用Scala语言编写的,不依赖于其他NLP或ML库。它本身就扩展了SparkML API。你将从中获得如下益处:
无与伦比的时间性能,因为是直接在Spark DataFrames上进行数据处理而没有经过任何拷贝,执行和优化都是在二进制数据格式进行的。
可以与现有的Spark库进行无缝重用,包括分布式主题建模、词嵌入、n-gram、字符串距离计算等。
通过使用统一的API,可以在跨自然语言理解、机器学习和深度学习部分使用统一的API。
创始团队说:“我们将向John Snow实验室提供NLP,让客户能够利用最新的开源技术和数据科学的学术突破,在高性能、企业级代码基础上都能做到这一点”。此外,“John Snow实验室NLP包含了大量高效的自然语言理解工具,用于文本挖掘、问答、聊天机器人、事实提取、主题建模或搜索,这些任务在规模上运行取得了迄今还没有的性能。”
该框架提供了注释器(annotators)的概念:
Tokenizer(分词器)
Normalizer(标准化器)
Stemmer(词干分析器)
Lemmatizer(词形还原工具)
Entity Extractor(实体提取器)
Date Extractor(日期提取器)
Part of Speech Tagger(词性标注)
Named Entity Recognition(命名实体识别)
Sentence boundary detection(句子边界识别)
Sentiment analysis(语义分析)
Spell checker(拼写检查器)
此外,考虑到与SparkML的紧密集成特性,在构建NLP pipelines时,还可以使用更多的东西。这包括词嵌入、主题模型、停用词删除、各种功能(tf-idf、n-gram、相似性度量、……),以及使用NLP注释作为机器学习工作流的特征。如果您不熟悉这些术语,那么理解NLP任务的指南是一个良好的开端。
我们的虚拟团队一直在开发商业软件,这在很大程度上依赖于自然语言的理解,因此,我们有以下工具的实践经验:spaCy, CoreNLP, OpenNLP, Mallet, GATE, Weka, UIMA, nltk, gensim,Negex, word2vec, GloVe等。
我们是这些库的忠实的粉丝,我们模仿这些库进行开发自己的库。但当我们不得不为实际生产提交可伸缩、高性能、高精度的软件时,我们也反对他们的局限性。
▌性能
我们处理的三个需求中的第一个是运行性能。随着spaCy以及它的benchmarks的出现,你可能会认为这是一个已经被解决的问题,因为spaCy是一个经过深思熟虑和巧妙实现的方案。然而,在利用它构建Spark应用程序时,您仍然会得到不合理的低于平均水平的吞吐量。
要理解原因,请考虑NLP pipeline始终只是一个更大的数据处理管道的一部分:例如,问答系统涉及到加载训练、数据、转换、应用NLP注释器、构建特征、训练提取模型、评估结果(训练/测试分开或交叉验证)和超参数估计。
将您的数据处理框架(Spark)从NLP框架中分离出来,这意味着您的大部分处理时间将花费在序列化和复制字符串上。
一个大的并行框架是tensorframe,它极大地提高了在Spark数据帧上运行TensorFlow工作流的性能。这张照片来自于Tim Hunter的tensorframe概述:
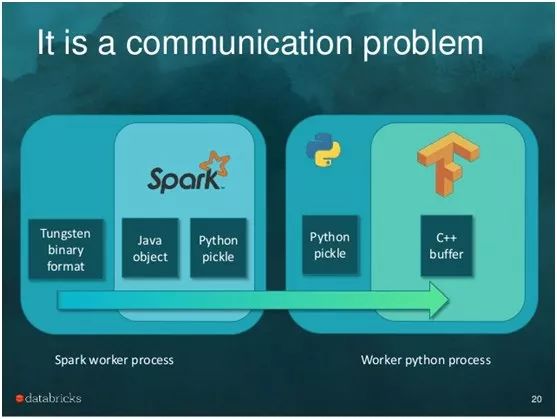
Spark和TensorFlow都针对性能和规模进行了优化。然而,由于DataFrames在JVM中,而TensorFlow在Python进程中运行,所以这两个框架之间的任何集成都意味着每个对象必须被序列化,通过这两种方式进行进程间通信,并在内存中至少复制两次。Tensorframe的公共benchmark通过在JVM进程中复制数据获得了四倍的速度提升(当使用GPU时能用更多的数据)。
在使用Spark时,我们看到了同样的问题:Spark对加载和转换数据进行了高度优化,但是,运行NLP管道需要复制Tungsten优化格式之外的所有数据,将其序列化,将其压到Python进程中,运行NLP管道(这一点速度非常快),然后将结果重新序列化到JVM进程中。这会丧失您从Spark的缓存或执行计划中获得的任何性能好处,至少需要两倍的内存,并且不会随着扩展而改进。使用CoreNLP可以消除对另一个进程的复制,但是仍然需要从数据帧中复制所有的文本并将结果复制回来。
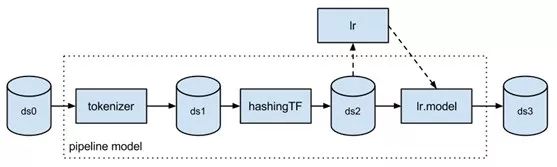
因此,我们的第一项业务是直接对优化的数据框架进行分析,就像Spark ML已经做的那样:
▌生态系统
我们的第二个核心需求是与现有Spark库的无缝重用。这个问题是我们自己难以忍受的——为什么每个NLP库都必须建立自己的主题建模和word嵌入实现?另一部分是务实的——我们是一个在紧迫deadlines下的小团队,需要充分利用现有的一切。
当我们开始思考一个Spark NLP库时,我们首先要求Databricks指出我们已经在构建的一个库。当没有答案时,下一个问题是帮助我们确保库的设计和API完全符合Spark ML的API指南。这种协作的结果是,新建库是Spark ML的无缝扩展,因此您可以构建这样的管道:
val pipeline = newmllib.Pipeline().setStages(
Array(docAssembler,tokenizer,stemmer,stopWordRemover,hasher,idf,dtree,labelDeIndex))
在这段代码中,文档汇编器、分词器和词干分析器,都来自于Spark NLP的com.jsl.nlp.*库。
TF hasher,IDF和labelDeIndex都来自于MLlib’sorg.apache.spark.ml.feature.*包。
dtree stage是一个spark.ml.classification.DecisionTreeClassifier。
所有这些阶段都运行在一个可配置的、可序列化和可测试的管道(pipeline)中。它们运行在数据框架上,不需要任何数据的复制(不像Spark-corenlp),可以享受Spark在内存中的优化、并行和分布式扩展。
这意味着,John Snow实验室NLP库提供了完全分布式的,经过严格测试和优化的主题模型,词嵌入,n-gram,和余弦相似工具。这些工具都是来自于Spark,我们不需要构建。
最重要的是,这意味着你的NLP和ML管道现在已经统一了。上面的代码示例是比较典型的,在某种意义上,它不是“只是”NLP管道——NLP被用于生成用于训练决策树的特征,这是典型的问答任务。一个更复杂的示例还可以应用命名实体识别,通过POS标记和指代消解来过滤。训练一个随机的森林,考虑到基于nlp的特征和来自其他来源的结构化特征;使用网格搜索来进行超参数优化。当您需要测试、复制、序列化或发布这样的管道时,能够使用统一的API,它带来的好处甚至不止有性能和重用的好处。
▌企业级
我们的第三个核心需求是交付一个关键任务,企业级NLP库。如今,许多最流行的NLP包都有学术的根源——这在设计上体现了在运行时性能方面的优势,包括极简的API的选择范围,淡化可扩展性,错误处理,节约的内存消耗和代码重用。
John Snow实验室NLP库是用Scala写的,它包括从Spark中使用的Scala和Python api,它不依赖任何其他NLP或ML库。对于每种类型的注释器,我们都要进行学术文献回顾,以找到最流行的方法,进行小组讨论,并决定要实现哪种算法。实现的评估有三个标准:
准确性:如果它有低于标准的算法或模型,那么这个框架就没有意义。
性能:运行时效应该比任何公共基准都要高或更好。不应该放弃精确性,因为注释器的运行速度不够快,无法处理流媒体用例,或者在集群环境中不能很好地扩展。
可训练性和可配置性:NLP是一个固有的特定领域的问题。不同的语法和词汇在社交媒体文章和学术论文、SEC filings、电子医疗记录和报纸文章中使用。
该库已经在企业项目中使用——这意味着第一级bug、重构、意外瓶颈和序列化问题已经得到解决。单元测试覆盖和参考文档使我们能够轻松地使该代码开源。
John Snow Labs是该公司的领导者,并赞助了SparkNLP库的开发。该公司为其提供商业支持、保障和咨询服务。这为库提供了长期的资金支持,一个资金支持的活动开发团队,以及不断增长的现实项目,这些项目驱动了健壮性和路线图的优先次序。
▌Gettinginvolved(介入策略)
如果你需要NLP来做你当前的项目,你可以去JohnSnow Labs NLP的Apache Spark主页或者快速入门指南,并试一试。可以使用预构建的maven central(Scala)和pip安装(Python)版本。给我们发送问题或反馈给nlp@johnsnowlabs.com,或通过Twitter、LinkedIn或Facebook。
让我们知道您接下来需要什么功能。
以下是我们得到的一些请求,并且正在寻找更多的反馈进行设计和优先考虑:
Provide a SparkR client(提供SparkR客户端)
Provide “Spark-free” Java and Scala versions(提供Spark的java和scala免费版本)
Add a state of the art annotator for coreference resolution(添加一个流行的指代消解注解器)
Add a state of the art annotators for polarity detection(添加一个极性检测注解器)
Add a state of the art annotator for temporal reasoning(添加一个时序推理注解器)
Publish sample applications for common use cases such as question answering, text summarization or information retrieval(为常见的用例发布样例应用程序,如问答、文本摘要或信息检索)
Train and publish models for new domains or languages(训练并发布语言领域新的模型)
Publish reproducible, peer reviewed accuracy and performance benchmarks(发布可复制的、同行评审的准确性和性能benchmarks)
如果您想要扩展或为库做贡献,请从复现John Snow Labs NLP的Spark GitHub库开始。我们使用合并请求和GitHub的问题跟踪器来管理代码变更、bug和特性。该库还在起步阶段,我们对任何形式的贡献和反馈都非常感激。
注:David Talby是Usermind的首席技术官,专门在医疗保健领域应用大数据和数据科学。
相关内容:
[eBook] A Gentle Introduction to Apache Spark(tm)
Building a Wikipedia Text Corpus for Natural Language Processing
Search Millions of Documents for Thousands of Keywords in a Flash
参考文献:
https://www.kdnuggets.com/2017/11/natural-language-processing-library-apache-spark.html
https://www.analyticsvidhya.com/blog/2017/01/ultimate-guide-to-understand-implement-natural-language-processing-codes-in-python/
-END-
专 · 知
人工智能领域主题知识资料查看获取:
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!
请加专知小助手微信(Rancho_Fang),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等,或者加小助手咨询入群)交流~
点击“阅读原文”,使用专知!
以上是关于最新Apache Spark平台的NLP库,助你轻松搞定自然语言处理任务的主要内容,如果未能解决你的问题,请参考以下文章