自然语言处理SD-NMT机器翻译模型介绍(上)
Posted 没头脑硕士不高兴博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理SD-NMT机器翻译模型介绍(上)相关的知识,希望对你有一定的参考价值。
Sequence-to-Dependency Neural Machine Translation(SD-NMT)
(上卷-文章介绍)
摘
要
Nowadays a typical Neural Machine Translation (NMT) model generates translations from left to right as a linear sequence, during which latent syntactic structures of the target sentences are not explicitly concerned. Inspired by the success of using syntactic knowledge of target language for improving statistical machine translation, in this paper we propose a novel Sequence-to-Dependency Neural Machine Translation (SD-NMT) method, in which the target word sequence and its corresponding dependency structure are jointly constructed and modeled, and this structure is used as context to facilitate word generations. Experimental results show that the proposed method significantly outperforms state-of-the-art baselines on Chinese-English and Japanese- English translation tasks.
关键词: 生成任务、seq2seq、句法依存树
特
色
1、在普通的神经网络机器翻译(NMT)模型中引入句法依存树是本文的创新点之一。
2、生成模型选用的是常见的双向循环神经网络(RNN)。
成
果
1、有助于生成任务中的语法错误纠正。
2、引入的句法信息能一定程度上优化RNN长期记忆消失的问题。
综
述
1、Shen et al., (2008):证明了句法依存树能很好地提升统计机器翻译(SMT)类模型的翻译效果。
句法依存树的结构如图1中的partial tree所示,能明确地将动词与其发生的主语相联系,当失去句法树之后会如ungrammatical structure所指的线一样, foreigners的谓语被误翻译成了is,这是由于翻译模型缺乏了句法的约束,谓语被距离更近的government所影响。Shen发现如果能有句法树的辅助,统计翻译模型(SMT)在此处就会明白该处is的主语其实应该是更远的foreigners,就能正确地将谓语翻译为复数形式如will,因此结构树能有助于让模型纠正语法上的一些如图中红字部分所示的语法问题。 本文SD-NMT模型作者就是被该篇文章所启发,认为句法信息既然对SMT模型有改进效果,那么应用于神经网络翻译模型(NMT)应该也能有改进句法问题的效果。
下面的就是图 1, 快看看句法依存树结构长啥样
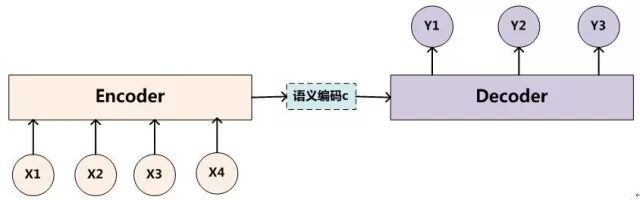
2、Sutskever et al., (2014) :编码器-解码器模型
Sutskever et al., (2014)提出的经典encoder-decoder模型(如图2)一直是翻译任务中最常见的NMT模型之一,它先将待翻译的句子编码成一个中间的向量,即图中的语义编码c,再由解码部分来将这个语义编码进行解码,得到翻译后目标语言的句子。本文SD-NMT模型使用的依旧是这样一传统的经典结构,encoder部分也依旧是是常见的双向RNN,创新不同点在于decoder部分采用了两个双向RNN,类似于两层decoder结构,新加的一层decode RNN用于预测句法信息。
下面的就是图 2,也就是编码器-解码器(encoder-decoder)模型
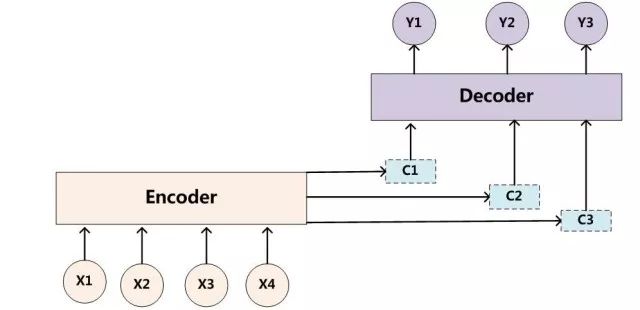
3、Bahdanau et al., (2015): NMT+attention
SD-NMT的模型在Sutskever et al., (2014)的基础上,又沿用了Bahdanau提出的attention结构,以attention的方式得到了上下文的向量表示。如图所示,在即将进行解码时,会指导机器更关注原文中与当前待翻译部分密切相关的部分。然而,SD-NMT模型在此基础上对attention进行了一个微小的改动,基本原理不变,但巧妙地结合进了句法信息,具体的结合方式详见(中卷)中的模型细节。
图在下面,小编懒得措辞了,你们寄几看吧
挑
战
SD-NMT模型主要在decode部分设计了两个子部分,每个子部分都是一个用于生成任务的双向RNN,如图4所示。以下三点为文章的主要挑战:
1、如何设计一个带有句法(Syntactic)结构的模型,即句法依存树和RNN怎么结合?
2、如何使word模型和Syntactic模型同时训练?
3、Syntactic context如何能真正有助于word生成?
图 4就在这里,不离不弃
参考文献:
Libin Shen, Jinxi Xu, and Ralph M Weischedel. 2008. A new string-to-dependency machine translation algorithm with a target dependency language model. In ACL. pages 577–585.
Ilya Sutskever, Oriol Vinyals, and Quoc V Le. 2014. Sequence to sequence learning with neural networks. In Advances in neural information processing systems
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2015. Neural machine translation by jointly learning to align and translate. ICLR 2015 .
想学习更多自然语言处理的知识么?快扫码关注呀!
以上是关于自然语言处理SD-NMT机器翻译模型介绍(上)的主要内容,如果未能解决你的问题,请参考以下文章