微软亚院副院长周明:自然语言处理的历史与未来
Posted 专知
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微软亚院副院长周明:自然语言处理的历史与未来相关的知识,希望对你有一定的参考价值。
【导读】自然语言处理,即Nature Language Processing,一般简称为“NLP”,是人工智能领域的热点及微软赖以生存的技术。微软亚洲研究院副院长、ACL主席周明博士以《自然语言处理前沿技术》为题就NPL对微软的作用,及NPL的历史和未来进行了讲解与讨论。
人工智能的“新浪潮”已经来临
要想了解自然语言处理,就不得不先了解人工智能。人工智能(AI)技术作为当前最炙手可热的词汇,定是耳熟能详,但人工智能究竟是什么呢?
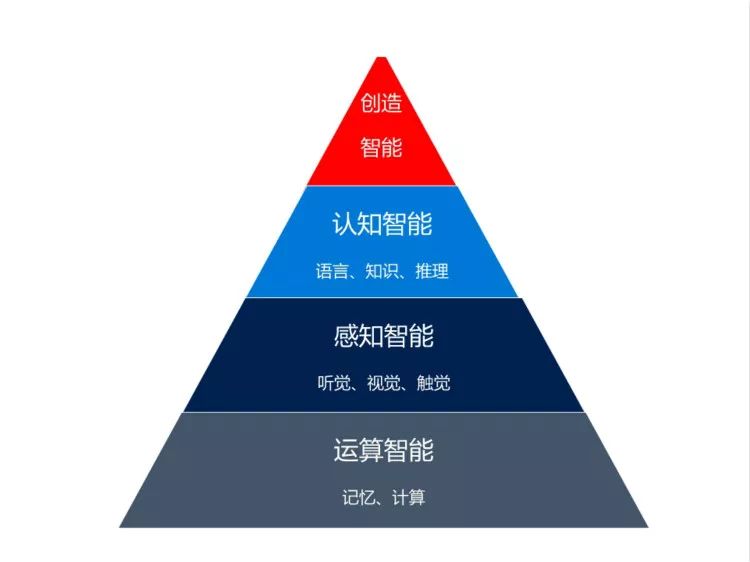
人工智能主要包括以下三个层次:
第一是运算智能:即记忆、计算的能力,这一点机器早已经超过人类;
第二是感知智能:包括听觉、视觉、触觉;最近两年,随着深度学习的引入,大幅度提高语音识别和图像识别的识别率,所以计算机在感知智能层面已经做得相当不错了,在一些典型的测试题下,达到或者超过了人类的平均水平;
第三认知智能:包括理解、运用语言的能力,掌握知识、运用知识的能力,以及在语言和知识基础上的推理能力。过去认知智能主要集中在语言智能这块,即自然语言处理,它简单理解了句子、篇章,实现了帮助搜索引擎、仿照系统提供一些基本的功能、提供一些简单的对话翻译。我认为语言智能是人工智能皇冠上的明珠,如果语言智能能实现突破,跟它同属认知智能的知识和推理就会得到长足的发展,就能推动整个人工智能体系,有更多的场景可以落地;
最高一层是创造智能:即人们利用已有的条件,利用一些想象力甚至有一些是臆断、梦想,想象一些不存在的事情包括理论、方法、技术,通过实验加以验证,然后提出新的理论,指导更多实践,最后产生很好的作品或产品。在创造智能上,人工智能目前还比较空白,如果能进一步推动感知智能和认知智能,尤其是认知智能,可能向创造智能进军一点。
人工智能正在经历的第三次重大浪潮与之前两次相比具有质的飞跃。
首先,数据比以前大了很多倍。以前做人工智能基本上是请一些专家录入数据写一些简单的规则,现在都海量的数据,包括互联网数据。
其次,计算的能力大大发展。以云计算为代表的计算能力使人们在训练或实施时不用再担心。以前的PC机能力非常有限。
再次,所谓的深度学习,实现了点对点、端对端的训练。你需要做的就是掌握并整理标注的数据,放到深度学习框架里面,它自动学习,自动抽取课程完成你所需要完成的任务。这使得机器学习的门槛大幅度下降,人工智能可以走向平民化,很多领域都可以用人工智能实现。
除此之外,还有重要的一点,就是落地的场景,是过去两次浪潮都没有的。过去都是套用系统,做一些小游戏、小玩具像做一个小问答系统。现在人工智能有实实在在的应用场景,比如说现在亿万网民都在使用的搜索引擎背后有很多人工智能的系统;自动驾驶汽车从感知到认知都用到了很多人工智能技术。这个场景有什么好处呢?一开始技术是有限的,能力是有问题的,随着越来越多人将其作为刚需使用,自然而然提供了海量的反馈,整个系统就可以不断提升。比如说搜索引擎,网民使用搜索引擎实际上也在帮助搜索引擎训练。
人工智能和自然语言处理技术(NLP)
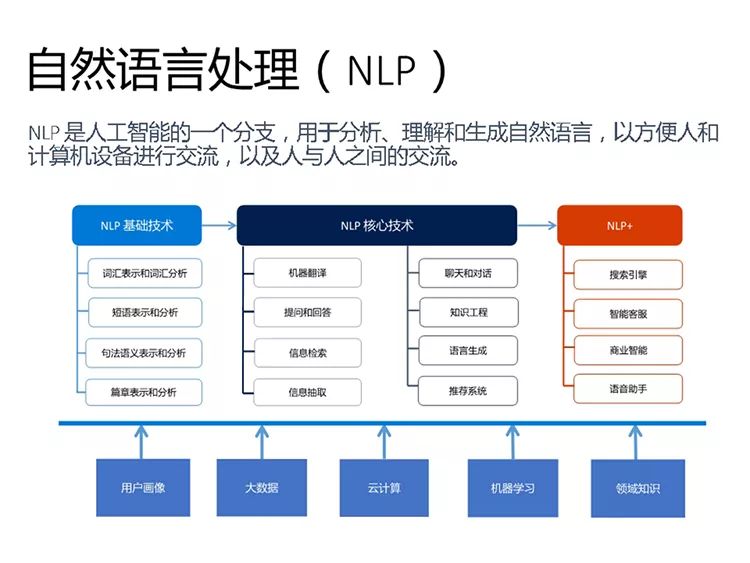
自然语言处理就是体现语言智能重要的技术,它是人工智能一个重要的分支,帮助分析、理解或者生成自然语言,实现人与机器的自然交流,同时也帮助人与人之间的交流。我认为自然语言处理包括以下几方面内容,第一是NLP的基础技术,围绕不同层次的自然语言处理,比如说分词、词性标注、语义分析做一些加工。后面做任何其他新的技术或者应用都必须要用到基础技术。
中间这块是NLP核心技术,包括词汇、短语、句子、篇章的表示,大家所说的Word Embedding就是在研究不同的语言单位的表示方法。它也包括机器翻译、提问和回答、信息检索、信息抽取、聊天和对话、知识工程、语言生成、推荐系统。
最后是“NLP+”,仿照“人工智能+”或“互联网+”的概念,实际上就是把自然语言处理技术深入到各个应用系统和垂直领域中。比较有名的是搜索引擎、智能客服、商业智能和语音助手,还有更多在垂直领域——法律、医疗、教育等各个方面的应用。
正如其他人工智能学科,自然语言处理也要有很多支撑技术、数据——包括用户画像,以提供个性化的服务;包括用来做训练之用的大数据;包括云计算提供、实施、训练的基础设施;包括机器学习和深度学习提供训练的技能……它一定要有各种知识支撑,比如领域知识还有常识知识。这张图就概括了人工智能方方面面的要素。
历史与当下:微软在自然语言处理的深入探索
关于自然语言处理的历史发展,可以说人工智能一开始是以自然语言处理发端的,比如说机器翻译是人们做人工智能最先的尝试。当时用六条规则、200多个词汇做俄英翻译,被认为是人工智能尖端性的改革。后来人们又做了很多大规模的问答系统、搜索系统、广告系统等,实际上都是基于规则的技术发展。人们去写N条规则,比如说机器翻译的词汇规则、转换规则、具体规则等等,优点是可以很快上线,但写规则的代价太大了,一个领域的规则换到另外一个领域几乎没用。
到了上世纪90年代左右,随着统计机器学习的发展,人们把它引用到自然语言处理中,机器翻译由基于规则变成基于统计,这个势头一直延续2007年前后。深度学习兴起,在语音识别和图像识别上崭露头角。2007年到现在,可以归结为深度学习的起步、成熟和大发展的时期。现在语音识别、图像识别等开始使用深度学习,而在自然语言处理方面,主要体现在词嵌入、神经网络、机器翻译、问答系统、对话系统。现在主流技术全部都是用深度学习来体现的。
自然语言对微软的重要作用:依赖NLP技术,微软亚洲研究院在机器翻译、中国文化、聊天机器人和阅读理解这四个领域都取得了不俗进展。
1.机器翻译:2007年,微软基于统计的翻译系统上线,提供免费的对外服务;2012年,微软亚洲研究院与总部研究院合作开发语音翻译系统,翻译部分就是利用自然语言来做的。2012年天津举行的21世纪的计算大会上,当时微软研究院的领导人Rick Rashid博士面对3,000位听众现场成功演示了这个语音翻译系统,轰动一时,堪称整个世界上机器翻译尤其是语音翻译领域的重要里程碑。2015年,微软对外公开发布了Skype Translator,它集成了微软的语音技术和翻译技术,现在在十种语言上提供了语音到语音的翻译。2017年,微软又有了新的长足的进步,首先在语音翻译上,微软全面采用了神经网络机器翻译,并拓展了新的翻译功能,即Microsoft Translator Live Feature(现场翻译功能)。在演讲和开会时,实时自动在手机端或桌面端,把演讲者的话翻译成多种语言。
微软亚洲研究院在神经网络机器翻译的方面也有巨大进展。
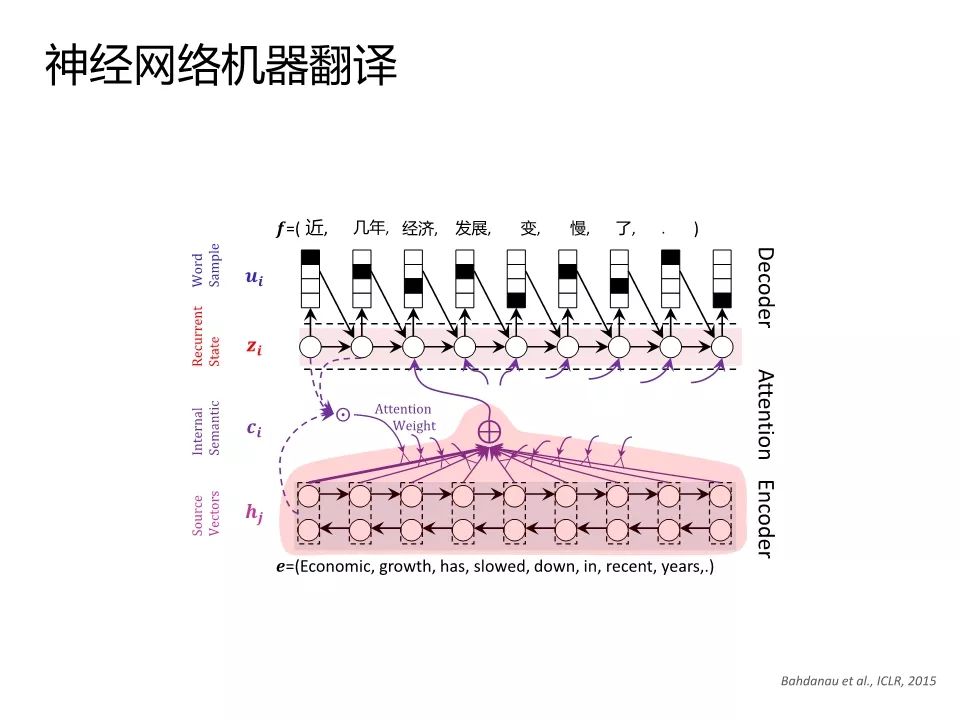
这张图概括了神经网络机器翻译,简要的说,就是对源语言的句子进行编码,一般都是用长短时记忆LSTM进行编码。编码的结果就是有很多隐节点,每个隐节点代表从句首到当前词汇为止,与句子的语义信息。基于这些隐节点,通过一个注意力的模型来体现不同隐节点对于翻译目标词的作用。通过这样的一个模式对目标语言可以逐词进行生成,直到生成句尾。中间在某一阶段可能会有多个翻译,系统会保留最佳翻译,从左到右持续。这里最重要的技术是对于源语言的编码,还有体现不同词汇翻译的,不同作用的注意力模型。
微软亚洲研究院主管研究员张冬冬博士在具体演示中作了进一步介绍:我们又持续做了一些工作,引入了语言知识。因为在编码的时候是仅把源语言和目标语言看成字符串,没有体会内在的词汇和词汇之间的修饰关系。我们把句法知识引入到神经网络编码、解码之中,得到了更佳的翻译,这是大家看到的指标有了很大程度的提升。此外,考虑到在很多领域是有知识图谱的,我们想把知识图谱纳入到传统的神经网络机器翻译当中,来规划语言理解的过程。我们的一个假设就是虽然大家的语言可能不一样,但是体现在知识图谱的领域上可能是一致的,就用知识图谱增强编码、解码。具体来讲,就是对于输入句子,先映射到知识图谱,然后再基于知识图谱增强解码过程,使得译文得到进一步改善。
2.中国文化:中国文化最有代表性的是对联、诗歌、猜谜语等等,它怎么能够用人工智能体现呢?好多人一想这件事就觉得不靠谱,没法做。但是微软亚洲研究院就利用然语言处理的技术,尤其是机器翻译的经验,果断进军到中国文化里,这个在全世界独树一帜。
2004年,微软时任院长沈向洋领导员工制造了一个微软对联:用户输入上联,电脑自动对出下联,语句非常工整,甚至更进一步把横批对出来。这个系统把机器翻译技术巧妙用在中国文化上,解决了这个问题。在对联的基础上,微软继续开发了字谜。字谜是给谜面猜谜底。当然也可以反过来,给定一个谜底,使用者出谜面。现在,微团已经可以用电脑来模拟整个猜字谜和出字谜的过程。我们还会用人工智能技术来发展中国最经典的文化,包括绝句和律诗等。最近,宋睿华博士就在用这种神经网络的技术来进行诗歌的创作。这件事非常有创意:用户提交一个照片,让系统进行,然后变成一首诗,自由体的诗。写诗是很不容易的,因为要体现意境。你说这是山,这是水,这不叫诗。诗歌必须要升华、凝练,用诗的语言来体现此时的情或者景,由景入情,由情入景,这才是诗。大概两周以前,微软小冰发布了微软小冰写诗的技能,引起了很多人的关注。我们也在此基础上展示其他的中国文化,把人工智能和中国文化巧妙结合起来,弘扬中国文化。
3.对话即平台:“对话即平台”,英文叫做“Conversation as a Platform (CaaP)”,微软首席执行官萨提亚在大会上提出了CaaP这个概念,他认为继图形界面的下一代就是对话,它会对整个人工智能、计算机设备带来一场新的革命。
为什么要提到这个概念呢?
第一个原因,源于大家都已经习惯用社交手段,如微信、Facebook与他人聊天的过程。研发者希望将这种通过自然的语言交流的过程呈现在当今的人机交互中,而语音交流的背后就是对话平台。
第二个原因则在于,现在大家面对的设备有的屏幕很小,有的甚至没有屏幕,所以通过语音的交互,更为自然直观的。因此,我们是需要对话式的自然语言交流的,通过语音助手来帮忙完成。而语音助手又可以调用很多Bot,来完成一些具体的功能,比如说定杯咖啡,买一个车票等等。芸芸众生,有很多很多需求,每个需求都有可能是一个小Bot,必须有人去做这个Bot。而于微软而言,我们作为一个平台公司,希望把自己的能力释放出来,让全世界的开发者,甚至普通的学生就能开发出自己喜欢的Bot,形成一个生态的平台,生态的环境。
如何从人出发,通过智能助理,再通过Bot体现这一生态呢?微软在做CaaP的时候,实际上有两个主要的产品策略。
第一个是小娜,通过手机和智能设备介入,让人与电脑进行交流:人发布命令,小娜理解并执行任务。同时,小娜作为你的贴身处理,也理解你的性格特点、喜好、习惯,然后主动给你一些贴心提示。比如,你过去经常路过某个地方买牛奶,在你下次路过的时候,她就会提醒你,问你要不要买。她从过去的被动到现在的主动,由原来的手机,到微软所有的产品,比如Xbox和Windows,都得到了应用。现在,小娜已经拥有超过1.4亿活跃用户,在数以十亿级计的设备上与人们进行交流。现在,小娜覆盖的语言已经有十几种语言,包括中文。小娜还在不断发展,球背后有很多自然语言技术来自微软研究院,包括微软亚洲研究院。
第二个就是小冰。它是一种新的理念,很多人一开始不理解。人们跟小冰一起的这种闲聊有什么意思?其实闲聊也是人工智能的一部分,我们人与人见面的时候,寒喧、问候、甚至瞎扯,天南海北地聊,这个没有智能是完成不了的,实际上除了语言方面的智能,还得有知识智能,必须得懂某一个领域的知识才能聊起来。所以,小冰是试图把各个语言的知识融汇贯通,实现一个开放语言自由的聊天过程。这件事,在全球都是比较创新的。现在,小冰已经覆盖了三种语言:中文、日文、英文,累积了上亿用户。很多人跟它聊天乐此不疲,而平均聊天的回数多达23轮。这是在所有聊天机器人里面遥遥领先的。而平时聊天时长大概是25分钟左右。小冰背后三种语言的聊天机器人也都来自于微软亚洲研究院。
无论是小冰这种闲聊,还是小娜这种注重任务执行的技术,背后单元处理引擎主要有三层技术。第一层:通用聊天,需要掌握沟通技巧、通用聊天数据、主题聊天数据,还要知道用户画像,投其所好。第二层:信息服务和问答,需要搜索的能力,问答的能力,还需要对常见问题表进行收集、整理和搜索,从知识图表、文档和图表中找出相应信息,并且回答问题,我们统称为Info Bot。第三层:面向特定任务的对话能力,例如订咖啡、订花、买火车票,这个任务是固定的,状态也是固定的,状态转移也是清晰的,那么就可以用Bot一个一个实现。你有一个调度系统,你知道用户的意图就调用相应的Bot 执行相应的任务。它用到的技术就是对用户意图的理解,对话的管理,领域知识,对话图谱等等”。
4.阅读理解:阅读理解,顾名思义就是给你一篇文章,看你理解到什么程度。人都有智能,而且是非常高的智能。除了累积知识,还要懂一些常识。具体测试你的阅读能力、理解能力的手段,一般都是给一篇文章,再你一些问题。你能来就说明你理解了,答不上来就说明你不理解。对电脑的测试也是这样。
下面我给大家举个例子:The Rhine is a European river that begins in the Swiss canton of Graubunden in the southeastern Swiss Alps, forms part of Swiss-Austrian, Swiss-lechtestein border, Swiss-German and then the Franco-German border, then flows through the Rhineland and eventually empties into the North Sea in the Netherlands. The biggest city on the river Rhine is Cologne, Germany with a population of more than 1,050,000 people. It is the second-largest river in the central and Western Europe (after the Danube), at about 1,230km, with an average discharge of about 2,900m3/s.(大致意思是说莱茵河畔最大的城市是德国科隆,莱茵河是中欧和西欧区域的第二长河流,仅次于多瑙河之后,约1230公里。问题是:什么河比莱茵河长?)
当你读完了这段话,你就要推断,“after”在这里是什么意思,从而才能得出正确答案是多瑙河。电脑要做这道题,实际上要仔细解析很多问题,最终才能作出回答。
展望:自然语言处理的未来与前景
第二,自然语言的会话、聊天、问答、对话达到实用程度。这是什么意思?这意味着在常见的场景下,通过人机对话的过程完成某项任务。这个是可以完全实现,或者跟某个智能设备进行交流,比如说关灯、打开电脑、打开纱窗这种一点问题都没有,包括带口音的说话都可以完全听懂。但是同样,这也不代表任何话题、任何任务、用任何变种的语言去说都可以达到。目前离那个目标还很远,我们也在努力。
第三,智能客服加上人工客服完美的结合,一定会大大提高客服的效率。我认为很多重复的客服工作,比如说问答,还有简单的任务,基本上人工智能都可以解决。但是复杂的情况下仍然不能解决,所以,实际上是人工智能跟人类智能生产线的完美结合来提高生产力。
第四,自动写对联、写诗、写新闻稿和歌曲等等,我认为今天可能还是一个新鲜的事物,但是五到十年一定都会流行起来,甚至都会用起来。比如说写新闻稿,给你一些数据,这个新闻稿草稿马上就写出来,你要做的就是纠正,添加内容,供不同的媒体使用等。
第五,在会话方面,语音助手、物联网、智能硬件、智能家居等等,凡是用到人机交互的,我认为基本上都可以得到应用,而且促进以上的一些产品推广。
最后,认知智能、感知智能一起努力,在很多场景下,比如说法律、医疗诊断、医疗咨询、法律顾问、投融资等等,这些方面自然语言会得到广泛的应用。
本文经授权转载自新华网智谷:http://zhigu.news.cn/2017-06/08/c_129628590.htm
-END-
专 · 知
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取AI知识资料!
点击“阅读原文”,使用专知!
以上是关于微软亚院副院长周明:自然语言处理的历史与未来的主要内容,如果未能解决你的问题,请参考以下文章
深度 | 周明:自然语言处理的未来之路 | CCF-GAIR 2019
微软亚洲研究院副院长周明:自然语言处理发展迅速,应用更加广泛