自然语言处理之基于biLSTM的pytorch立场检测实现
Posted 深度学习自然语言处理
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理之基于biLSTM的pytorch立场检测实现相关的知识,希望对你有一定的参考价值。
前面我已经讲过了LSTM的原理,想要了解的看上一篇就行。
LSTM理解了,biLSTM其实也就很容易理解了。这个实验,我是根据黑龙家大学nlp实验室的冯志,王潜升师兄的指导以及一篇基于biLSTM的paper实现的,如果想要这个paper的pdf,可以私聊我,一起进步。
biLSTM是双向循环神经网络,简单的理解就是LSTM正向走一遍,又反向走了一遍而已。而对于立场检测这个实验,在这里我借用此论文的图片:
Stance Detection with Bidirectional Conditional Encoding
先说数据文本格式:
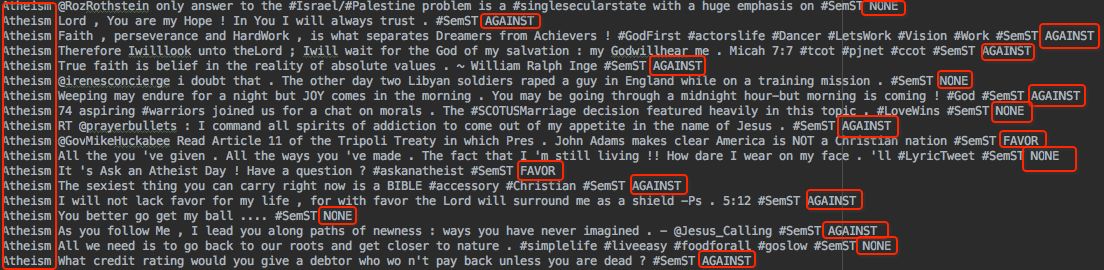
数据截图
前面是topic(图里的target),中间是针对这个topic的谈论文本,最后是这个文本在这个topic下的立场,格式简化为:
sentence = topic + text + label
而这里的topic有5种,分别为:
'Atheism', 'Feminist Movement', 'Hillary Clinton', 'Legalization of Abortion', 'Climate Change is a Real Concern'
而上面biLSTM网络流程图就是选取的topic为Legalization of Abortion的例子。
现在我来结合代码详细解释下这个基于biLSTM网络的立场检测实验:
首先,把网络搭建好:
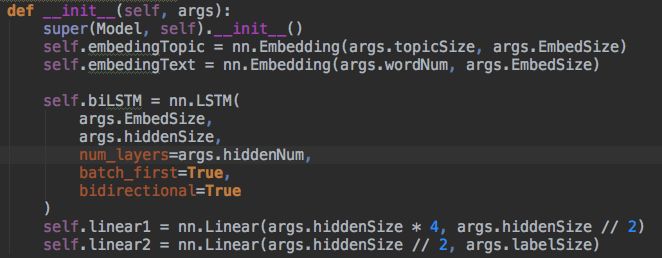
其中,LSTM的参数隐藏层大小hiddenSize和隐藏层数量hiddenNum,我用上面的图详细解释下:
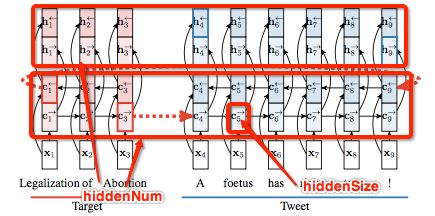
hiddenSize是说LSTM一个cell的参数大小,hiddenNum是说这样大网络循环的个数。
网络搭建好了,数据开始在网络中流动:
假设EmbedSize = 100,hiddenSize = 50
topic,text分别过Embedding Layer,维度分别为:(1,1,100),(1,17,100)

然后分别经过biLSTM Layer,维度为:(1,1,200),(1,17,200)

因为一会要经过一个maxPooling,所以现在先转置下,维度为(1,200,1),(1,200,17):

然后经过一个激活函数tanh,维度不变为(1,200,1),(1,200,17):

在第三维上,分别经过maxPooling,之后的维度为(1, 200, 1),(1, 200, 1):

然后cat在一起,维度为(1, 400, 1):

一会要经过线性层,可以先将没用的第三维扔掉,维度为(1, 400):

然后经过第一个线性层(400->100),维度为(1,100):

然后再经过一个tanh,维度不变(1,100):

最后,经过最后一个线性层(100->3),维度为(1,3):

你或许有疑问,为什么不直接经过一个线性层呢?因为我们要直接从400->3的话,信息会损失很多,如果分别经过两个400->100, 100->3,这样就不会损失那么多信息了,如果你想用三个线性层也可以,自己感觉调到最佳就好。
这个整体的数据流图为:
整个也就算讲完了,其实也想把实验结果摆上来的,可是我的电脑是4G的。。太慢了。。但是如果想要源代码的话,可以留言给我,共同进步。
以上是关于自然语言处理之基于biLSTM的pytorch立场检测实现的主要内容,如果未能解决你的问题,请参考以下文章