一文助你解决90%的自然语言处理问题(附代码)
Posted 数据派THU
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文助你解决90%的自然语言处理问题(附代码)相关的知识,希望对你有一定的参考价值。
来源:机器之心
本文约5000字,建议阅读9分钟。
本文为大家解析了人工智能领域中的自然语言如何处理。
自然语言处理(NLP)与计算机视觉(CV)一样,是目前人工智能领域里最为重要的两个方向。如何让机器学习方法从文字中理解人类语言内含的思想?本文中,来自 Insight AI 的 Emmanuel Ameisen 将为我们简述绝大多数任务上我们需要遵循的思路。

文本数据的 5W 和 1H!
文本数据无处不在
无论是成立的公司,还是致力于推出新服务,你都可以利用文本数据来验证、改进和扩展产品的功能。从文本数据中提取信息并从中学习的科学是自然语言处理(NLP)的一个活跃的研究课题。
NLP 覆盖领域很广,每天都会有新的令人兴奋的结果。但经过与数百家公司合作,Insight 团队发现其中有几个重要应用出现得尤其频繁:
识别不同的用户/客户群(例如预测客户流失、顾客终身价值、产品偏好)
准确检测和提取不同类别的反馈(正面和负面的评论/意见,提到的特定属性,如衣服尺寸/合身度等)
根据意图对文本进行分类(例如寻求一般帮助,紧急问题)
尽管网上有很多 NLP 论文和教程,但我们很难找到从头开始高效学习这些问题的指南和技巧。
本文给你的帮助
结合每年带领数百个项目组的经验,以及全美国最顶尖团队的建议,我们完成了这篇文章,它将解释如何利用机器学习方案来解决上述 NLP 问题。我们将从最简单的方法开始,然后介绍更细致的方案,如特征工程、单词向量和深度学习。
阅读完本文后,您将会知道如何:
收集、准备和检验数据
建立简单的模型,必要时转化为深度学习
解释和理解模型,确保捕获的是信息而非噪声
这篇文章我们将给你提供一步一步的指导;也可以作为一个提供有效标准方法的高水平概述。
这篇文章附有一个交互式 notebook,演示和应用了所有技术。你可以随意运行代码,同步学习:
https://github.com/hundredblocks/concrete_NLP_tutorial/blob/master/NLP_notebook.ipynb
第 1 步:收集数据
数据源示例
每个机器学习问题都从数据开始,例如电子邮件、帖子或推文(微博)。文本信息的常见来源包括:
产品评论(来自亚马逊,Yelp 和各种应用商店)
用户发布的内容(推文,Facebook 上的帖子,StackOverflow 上的问题)
故障排除(客户请求,支持票据,聊天记录)
「社交媒体中出现的灾难」数据集
本文我们将使用由 CrowdFlower 提供的一个名为「社交媒体中出现的灾难」的数据集,其中:
编者查看了超过 1 万条推文,其中包括「着火」、「隔离」和「混乱」等各种搜索,然后看推文是否是指灾难事件(排除掉用这些单词来讲笑话或评论电影等没有发生灾难的情况)。
我们的任务是检测哪些推文关于灾难性事件,排除像电影这种不相关的话题。为什么?一个可能的应用是仅在发生紧急事件时(而不是在讨论最近 Adam Sandler 的电影时)通知执法官员。
这篇文章的其它地方,我们将把关于灾难的推文称为「灾难」,把其它的推文称为「不相关事件」。
标签
我们已经标记了数据,因此我们知道推文所属类别。正如 Richard Socher 在下文中概述的那样,找到并标记足够多的数据来训练模型通常更快、更简单、更便宜,而非尝试优化复杂的无监督方法。
Richard Socher 的小建议
第 2 步:清理数据
我们遵循的首要规则是:「你的模型受限于你的数据」。
数据科学家的重要技能之一就是知道下一步的工作对象是模型还是数据。一个好的方法是先查看数据再清理数据。一个干净的数据集可以使模型学习有意义的特征,而不是过度拟合无关的噪声。
下面是一个清理数据的清单:(更多细节见代码 code (https://github.com/hundredblocks/concrete_NLP_tutorial/blob/master/NLP_notebook.ipynb)):
1. 删除所有不相关的字符,如任何非字母数字字符
2. 把文字分成单独的单词来标记解析
3. 删除不相关的词,例如推文中的「@」或网址
4. 将所有字符转换为小写字母,使「hello」,「Hello」和「HELLO」等单词统一
5. 考虑将拼写错误和重复拼写的单词归为一类(例如「cool」/「kewl」/「cooool」)
6. 考虑词性还原(将「am」「are」「is」等词语统一为常见形式「be」)
按这些步骤操作并检查错误后,就可以使用干净的标签化的数据来训练模型啦!
第 3 步:寻找好的数据表示
机器学习模型的输入是数值。如图像处理的模型中,用矩阵来表示各个颜色通道中每个像素的强度。
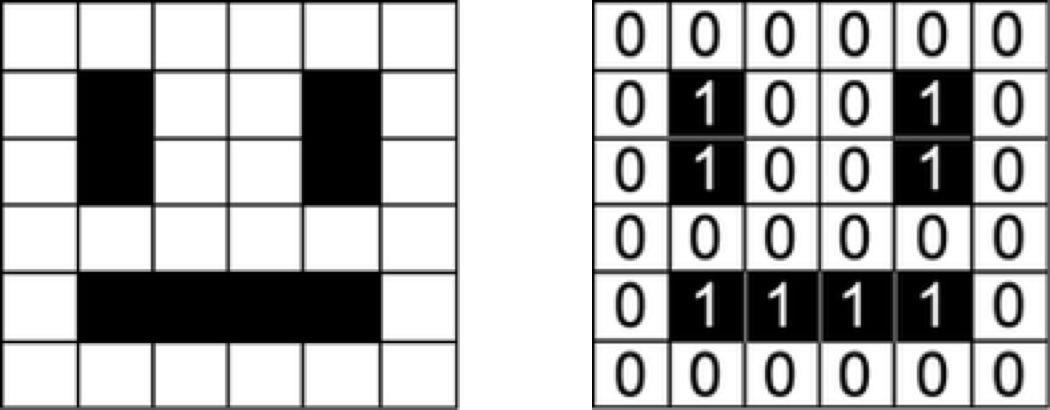
一个笑脸可以表示为一个数字矩阵。
如果我们的数据集是一系列的句子,为了使算法可以从数据中提取特征,我们需要表示为可以被算法识别的形式,如表示为一系列数字。
One-hot encoding(词袋模型)
表示文本的一种常见方法是将每个字符单独编码为一个数字(例如 ASCII)。如果我们直接把这种简单的形式用于分类器,那只能基于我们的数据从头开始学习单词的结构,这对于大多数数据集是不可实现的。因此,我们需要一个更高级的方法。
例如,我们可以为数据集中的所有单词建立一个词汇表,每个单词对应一个不同的数字(索引)。那句子就可以表示成长度为词汇表中不同单词的一个列表。在列表的每个索引处,标记该单词在句子中出现的次数。这就是词袋模型(Bag of Words),这种表示完全忽略了句子中单词的顺序。如下所示。
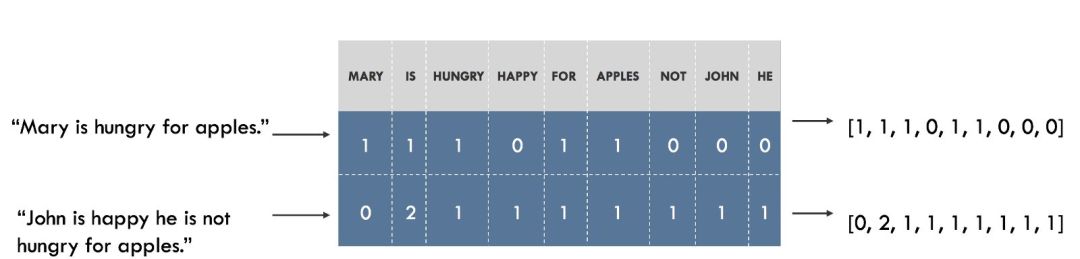
将句子表示为词袋。左边为句子,右边为对应的表示,向量中的每个数字(索引)代表一个特定的单词。
可视化词嵌入
在「社交媒体中出现的灾难」一例中,大约有 2 万字的词汇,这代表每个句子都将被表示为长度为 2 万的向量。向量中有很多 0,因为每个句子只包含词汇表中非常小的一个子集。
为了了解词嵌入是否捕获到了与问题相关的信息(如推文是否说的是灾难),有一个很好的办法,就是将它们可视化并看这些类的分离程度。由于词汇表很大,在 20,000 个维度上可视化数据是不可能的,因此需要主成分分析(PCA)这样的方法将数据分到两个维度。如下图所示。
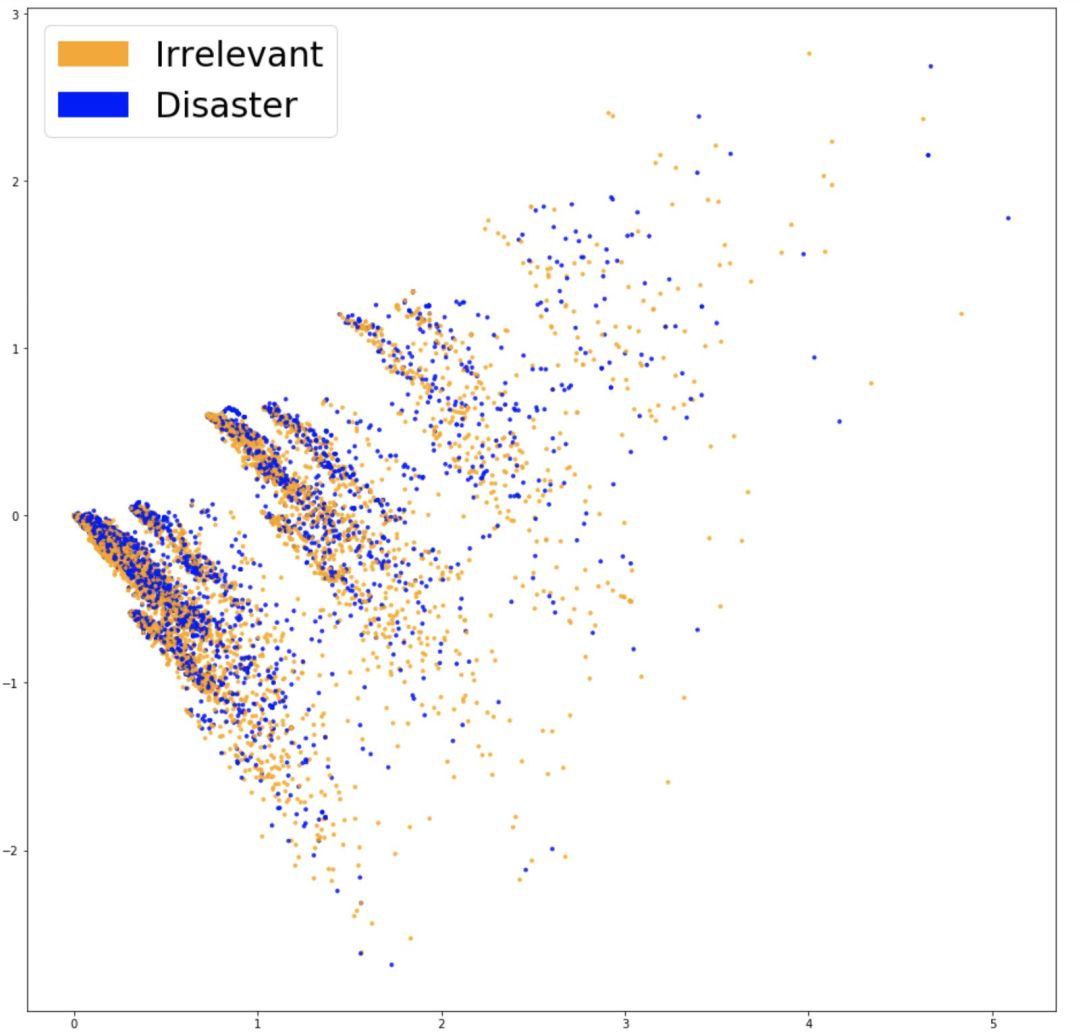
将嵌入的词袋可视化。
看起来很难分为两类,也不好去降低维度,这是嵌入的一个特点。为了了解词袋模型特征是否有用,我们可以基于它们训练一个分类器。
第 4 步:分类器
遇到一个问题时,通常从寻找解决问题的工具入手。当我们要对数据进行分类时,出于通用性和可解释性的考虑,通常使用 Logistic 回归(Logistic Regression)。训练非常简单,结果也可解释,因为易于从模型提取出最重要的参数。
我们将数据分成一个用于拟合模型的训练集和一个用于分析对不可见数据拟合程度的测试集。训练结束后,准确率为 75.4%。还看得过去!最频繁的一类(「不相关事件」)仅为 57%。但即使只有 75% 的准确率也足以满足我们的需要了,一定要在理解的基础上建模。
第 5 步:检验
混淆矩阵(Confusion Matrix)
首先要知道我们模型的错误类型,以及最不期望的是哪种错误。在我们的例子中,误报指将不相关的推文分类为灾难,漏报指将关于灾难的推文归为不相关事件。如果要优先处理每个可能的事件,那我们想降低漏报的情况。如果我们优先考虑资源有限的问题,那我们会优先降低误报的情况,从而减少误报的提醒。我们可以用混淆矩阵来可视化这些信息,混淆矩阵将我们模型预测的结果与真实情况进行比较。理想情况下(我们的预测结果与真实情况完全相符),矩阵为从左上到右下的一个对角矩阵。
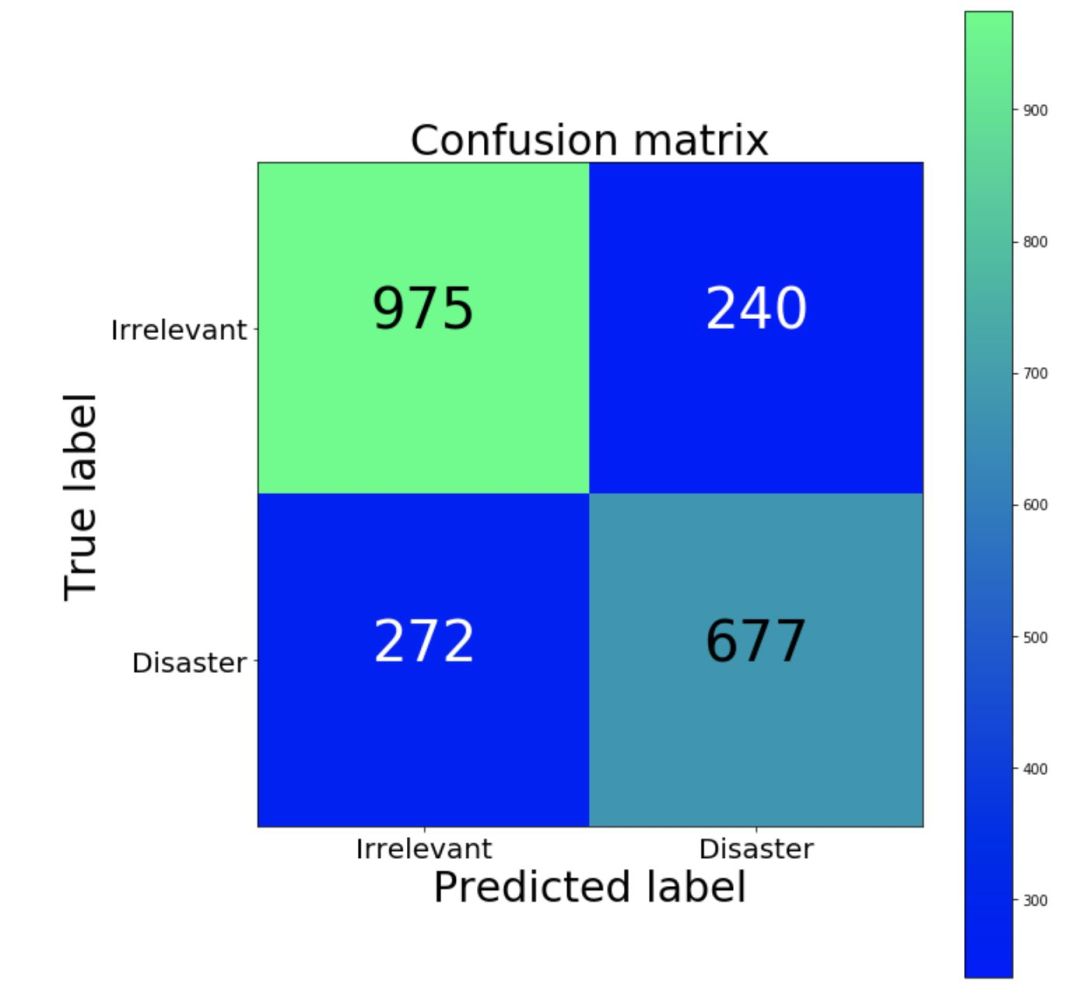
混淆矩阵(绿色比例大,蓝色比例小)
我们的分类器的漏报情况(相对)高于误报情况。也就是说,这个模型很可能错误地将灾难归为不相关事件。如果误报情况下执法的成本很高,那我们更倾向于使用这个分类器。
解释模型
为了验证模型并解释模型的预测,我们需要看哪些单词在预测中起主要作用。如果数据有偏差,分类器会对样本数据作出准确的预测,但在实际应用时模型预测的效果并不理想。下图中我们给出了关于灾难和不相关事件的重要词汇。我们可以提取并比较模型中的预测系数,所以用词袋模型和 Logistic 回归来寻找重要词汇非常简单。
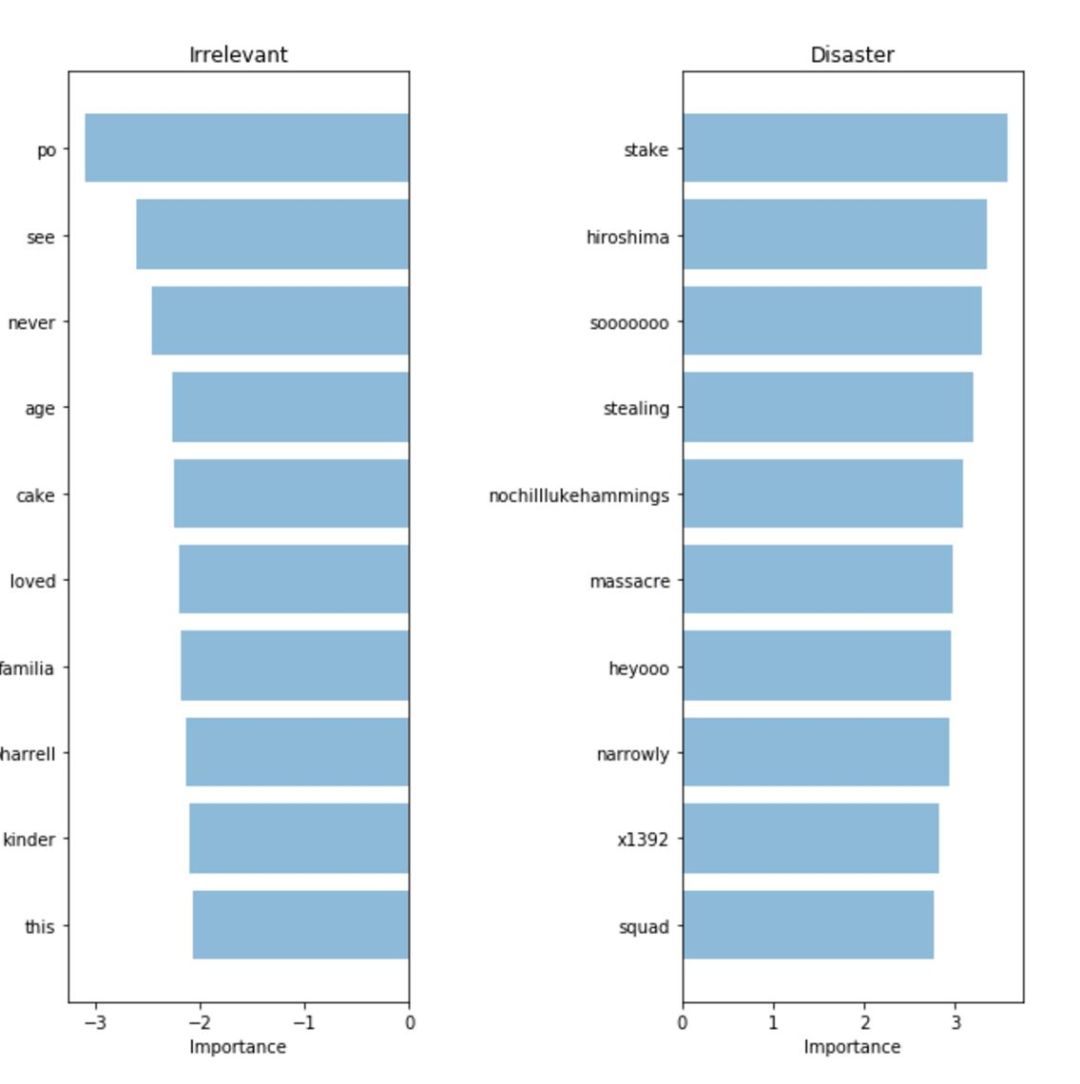
词袋:重要词汇
我们的分类器正确地找到了一些模式(广岛,大屠杀),但显然这是无意义数据的过度拟合(heyoo, x1392)。现在我们的词袋模型正在处理一个庞大的词汇表,所有词汇对它来说都是一样的。但一些词汇出现地非常频繁,而且只会对我们的预测加入噪声。接下来,我们试着用一个方法来表示词汇出现的频率,看我们能否从数据中获得更多的信号。
第 6 步:统计词汇
TF-IDF
为了使模型更关注有意义的单词,我们可以使用 TF-IDF(词频-逆文档频率)对我们的词袋模型进行评估。TF-IDF 通过对数据集中词汇出现的频率来加权,并减小高频但只是增加噪音的单词的权重。这是我们新嵌入的 PCA 预测。
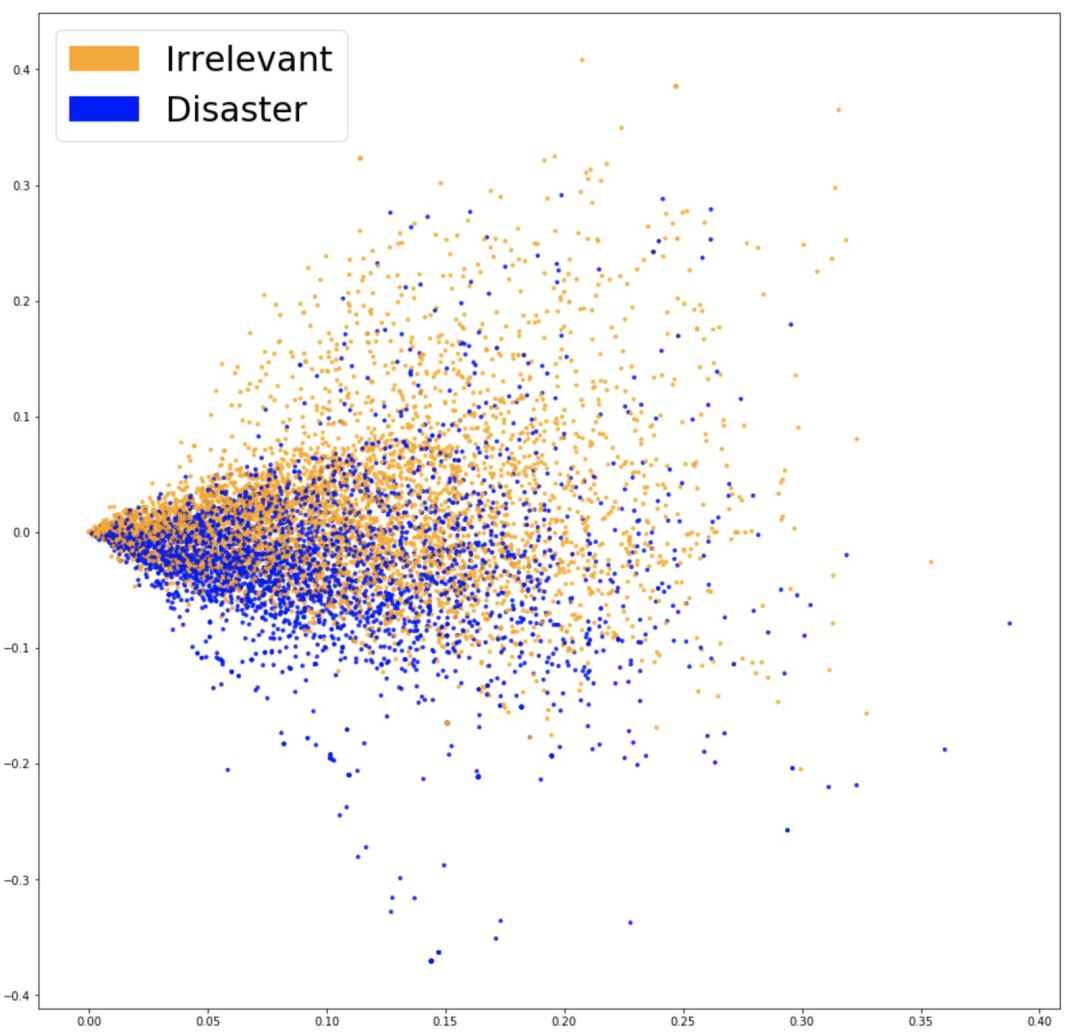
将 TF-IDF 嵌入可视化。
由上图我们看到,两种颜色的数据差别更加明显。这使分类器分组更加容易。让我们来看一下这样结果是否会更好。训练新嵌入的 Logistic 回归,我们得到了 76.2%的准确率。
只是稍稍地进行了改进。那现在我们的模型可以选择更重要的单词了吗?如果模型预测时有效地绕过了「陷阱」,得到了更好的结果,那就可以说,这个模型得到了优化。
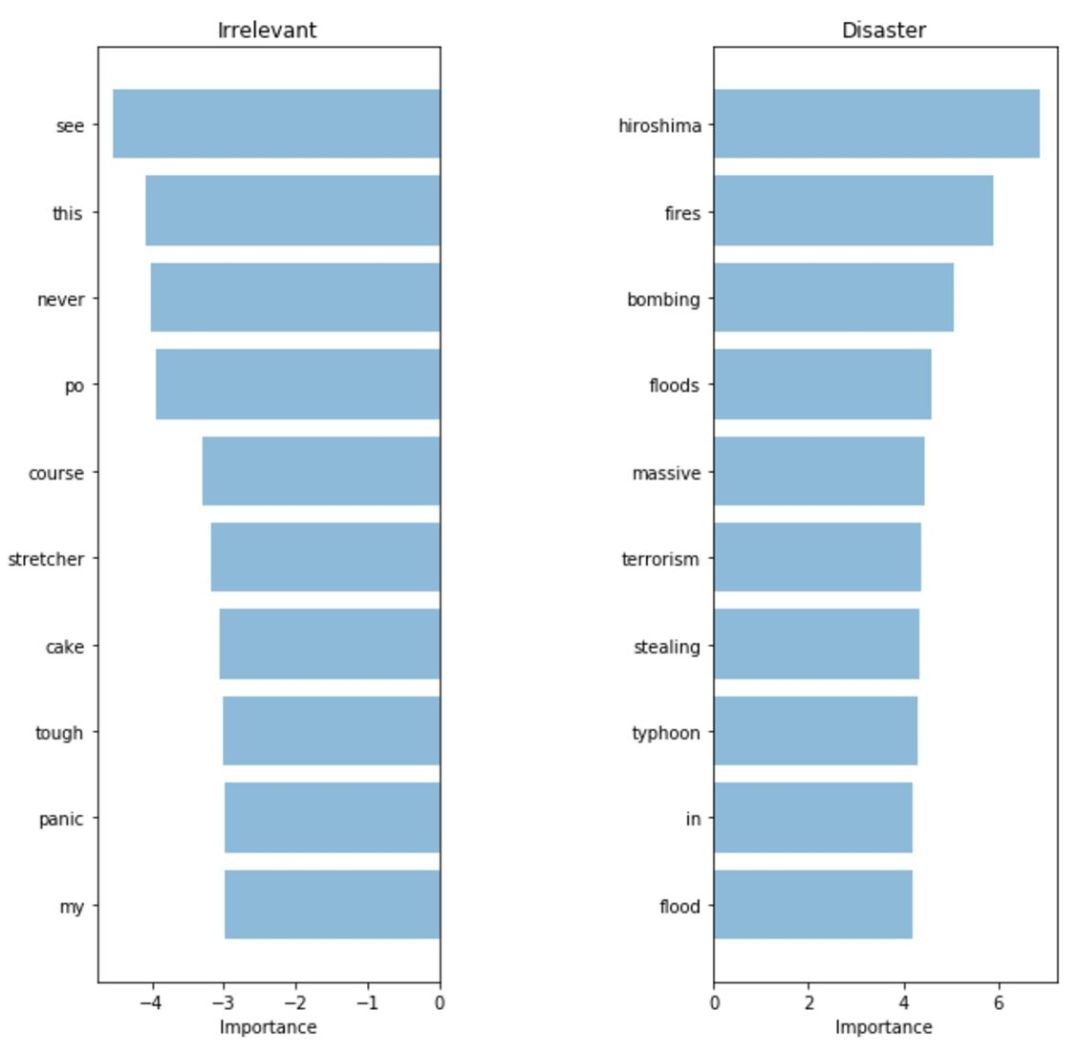
TF-IDF:重要词汇
挑出来的单词似乎更加相关了!尽管我们测试集的指标稍有增加,但模型使用的词汇更加关键了,因此我们说「整个系统运行时与客户的交互更加舒适有效」。
第 7 步:利用语义
Word2Vec
我们最新的模型可以挑出高信号的单词。但很可能我们运作模型时会遇到训练集中没有单词。因此,即使在训练中遇到非常相似的单词,之前的模型也不会准确地对这些推文进行分类。
为了解决这个问题,我们需要捕获单词的含义,也就是说,需要理解「good」和「positive」更接近而不是「apricot」或「continent」。用来捕获单词含义的工具叫 Word2Vec。
使用预训练的单词
Word2Vec 是寻找单词连续 embedding 的技术。通过阅读大量的文本学习,并记忆哪些单词倾向于相似的语境。训练足够多的数据后,词汇表中的每个单词会生成一个 300 维的向量,由意思相近的单词构成。
论文《Efficient Estimation of Word Representations in Vector Space》的作者开源了一个模型,对一个足够大的可用的语料库进行预训练,将其中的一些语义纳入我们的模型中。预训练的向量可以在这篇文章相关的资源库中找到:https://github.com/hundredblocks/concrete_NLP_tutorial。
句子的表示
快速得到分类器的 sentence embedding 的一个方法是平均对句子中的所有单词的 Word2Vec 评估。这和之前词袋模型是一个意思,但这次我们保留一些语言信息,仅忽略句子的语法。
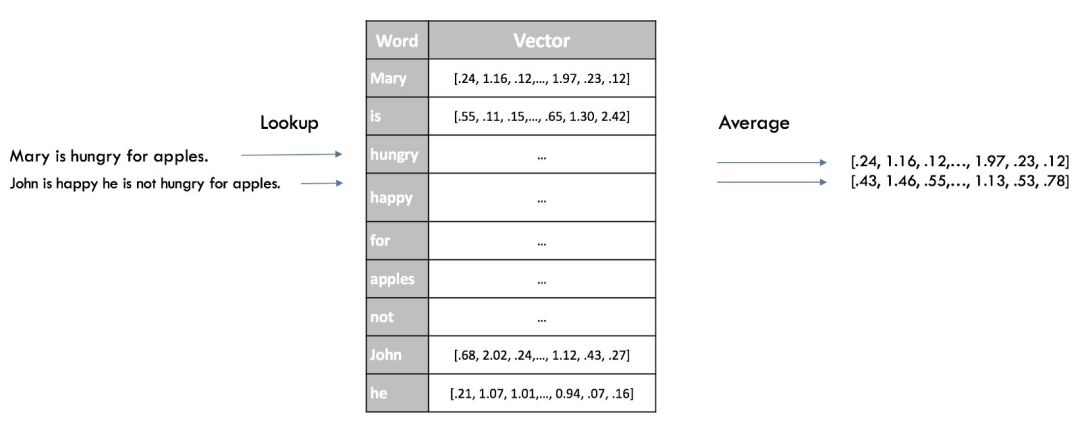
以下是之前技术的新嵌入的可视化:
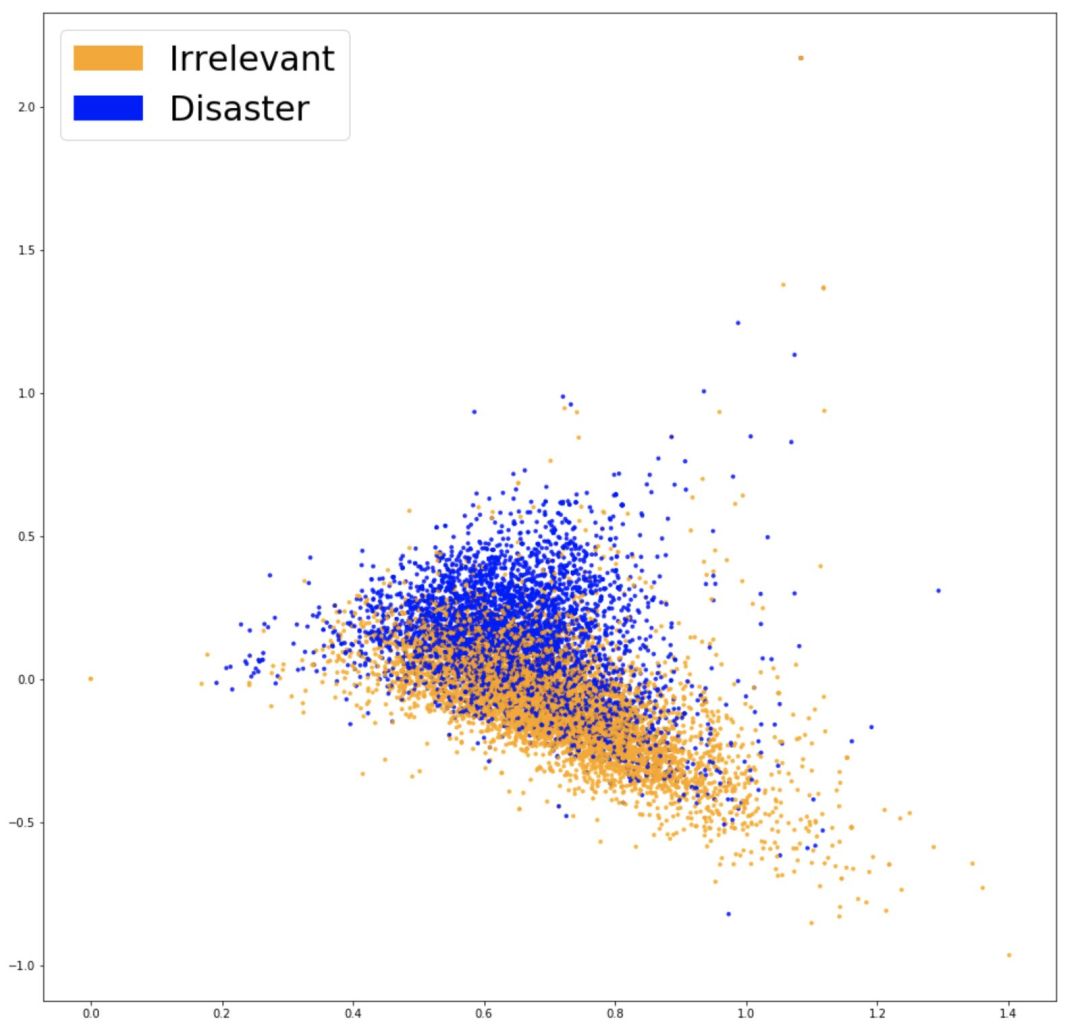
可视化 Word2Vec 嵌入
这两种颜色的数据更明显地分离了,我们新的嵌入可以使分类器找到两类之前的分离。经过第三次训练同一个模型后(Logistic 回归),我们得到了 77.7%的准确率,这是目前最好的结果!可以检验我们的模型了。
复杂性/可解释性的权衡
我们的 embedding 没有向之前的模型那样每个单词表示为一维的向量,所以很验证看出哪些单词和我们的向量最相关,。虽然我们仍可以使用 Logistic 回归的系数,但它们和我们 embedding 的 300 个维度有关,而不再是单词的索引。
它的准确率这么低,抛掉所有的可解释性似乎是一个粗糙的权衡。但对于更复杂的模型来说,我们可以利用 LIME 之类的黑盒解释器(black box explainers)来深入了解分类器的工作原理。
LIME
可以通过开源软件包在 Github 上找到 LIME:https://github.com/marcotcr/lime
黑盒解释器允许用户通过扰乱输入并观察预测的变化来解释一个特定例子的任何分类器的决定。
让我们看一下数据集中几个句子的解释。
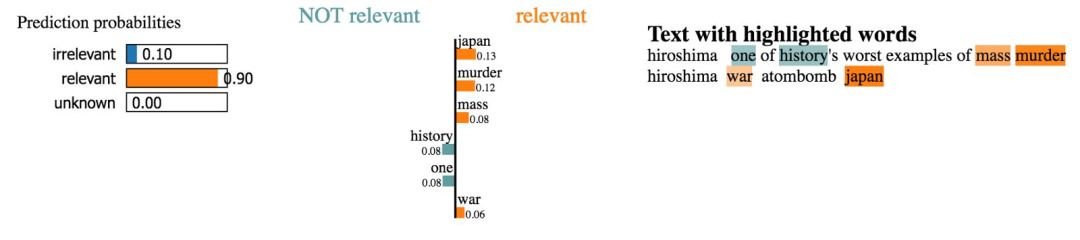
挑选正确的灾难词汇并归类为「相关」。
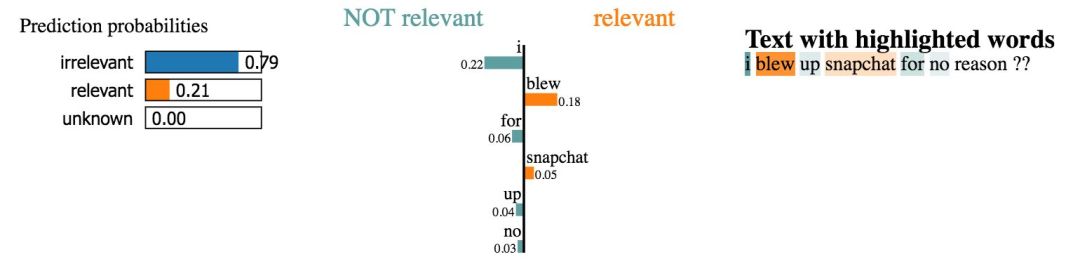
这里,这个词对分类器的造成的影响似乎不太明显。
但是,我们没有时间去探索数据集中的数千个示例。我们要做的是在测试例子的代表样本上运行 LIME,看哪些词汇做的贡献大。使用这种方式,我们可以像之前的模型一样对重要单词进行评估,并验证模型的预测结果。
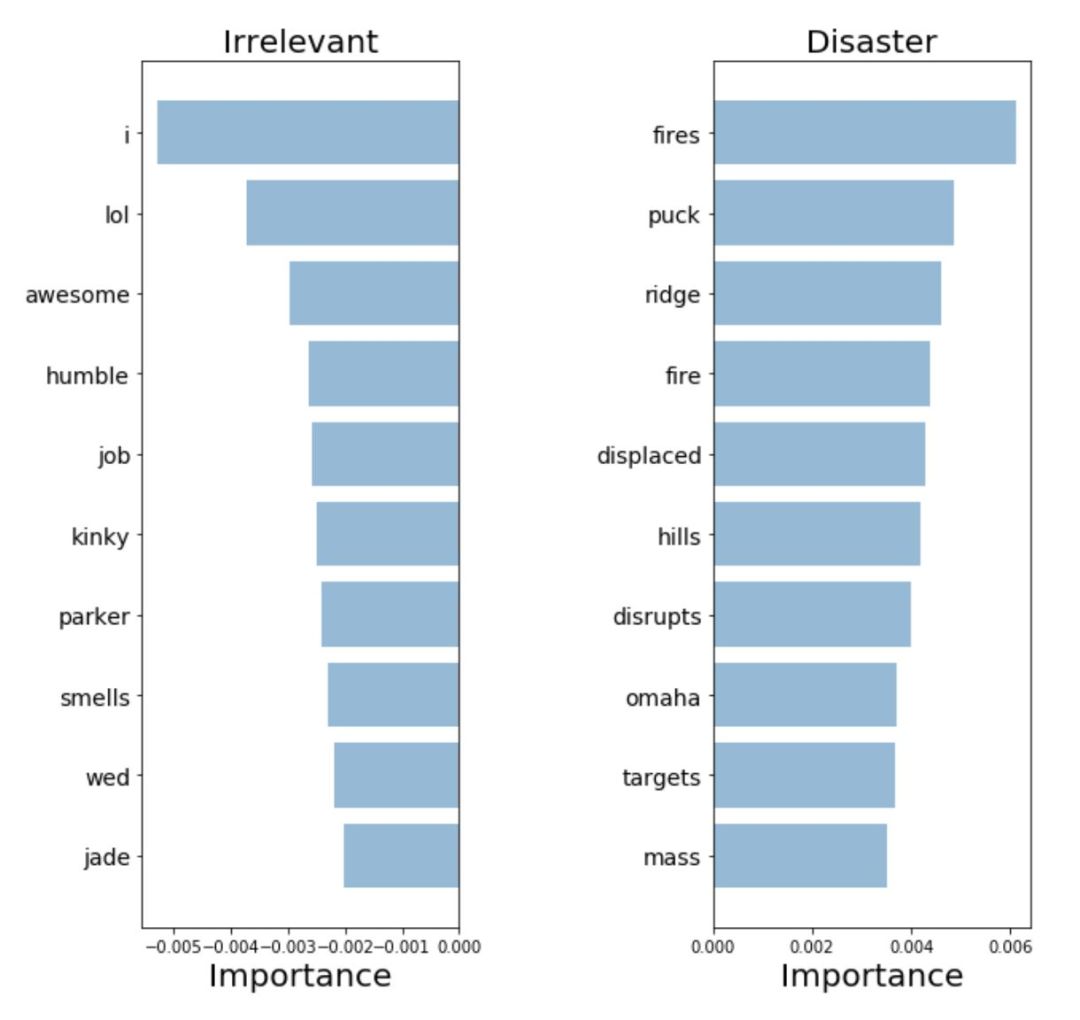
Word2Vec:重要单词
模型提取的高度相关的词意味它可以做出更加可解释的决定。这些看起来像是之前模型中最相关的词汇,因此我们更愿意将其加入到我们的模型中。
第 8 步:使用端到端(end-to-end)方法
我们已经介绍了生成简洁句嵌入快速有效的方法。但是由于忽略了单词的顺序,我们跳过了句子所有的语法信息。如果这些方法提供的结果不充分,那我们可以使用更复杂的模型,输入整个句子并预测标签,而不需要中间表示。一个常见的方法是使用 Word2Vec 或更类似的方法(如 GloVe 或 CoVe)将句子看作一个单词向量的序列。这就是我们下文中要做的。
高效的端到端结构
用于句子分类的卷积神经网络训练非常迅速,作为入门级深度学习体系效果非常理想。虽然卷积神经网络(CNN)主要因为在图像处理的使用而广为人知,但它们在处理文本相关任务时得到的结果也非常好,而且通常比大多数复杂的 NLP 方法(如 LSTMs 和 Encoder/Decoder 结构)训练地更快。这个模型考虑了单词的顺序,并学习了哪些单词序列可以预测目标类等有价值的信息,可以区别「Alex eats plants」和「Plants eat Alex」。
训练这个模型不用比之前的模型做更多的工作,并且效果更好,准确率达到了 79.5%!详见代码:https://github.com/hundredblocks/concrete_NLP_tutorial/blob/master/NLP_notebook.ipynb
与上述模型一样,下一步我们要使用此方法来探索和解释预测,以验证它是否是给用户提供的最好的模型。到现在,你应该对这样的问题轻车熟路了。
结语
下面对我们成功使用的方法进行简要回顾:
从一个简单快速的模型开始
解释其预测
了解其错误类型
根据以上知识来判断下一步的工作——处理数据还是寻找更复杂的模型
这些方法只用于特定的例子——使用适当的模型来理解和利用短文本(推文),但这种思想适用于各种问题。希望这篇文章对你有所帮助,也欢迎大家提出意见和问题!
原文链接:https://blog.insightdatascience.com/how-to-solve-90-of-nlp-problems-a-step-by-step-guide-fda605278e4e
以上是关于一文助你解决90%的自然语言处理问题(附代码)的主要内容,如果未能解决你的问题,请参考以下文章