正经说-自然语言处理
Posted 京东金融大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正经说-自然语言处理相关的知识,希望对你有一定的参考价值。
策划 | 孟非
前言
久违了,各位父老乡亲们!啊哈~我胡汉三终于又回来了!经过一个月的蛰伏,我精准地在大家完全忘记我的时候出现了!微信里有零星好友问我,这个月你都干啥正经事儿了?为下一系列文章做准备?还是躺平了在家养膘啊!我真的不好意思说…我就在公司搬了一个月砖啊!!!(TAT四月份好多需求…)
为了能保持我们能站在时下流行科技的风口浪尖,特意挑选了这个主题。自然语言处理(Natural language processing,简称NLP),是一门结合了语言学、人工智能、数学于一体的科学。它研究的领域就是让计算机能理解人类的语言,并和人类进行有效沟通的各种理论和方法。
语言是区别人类与其他物种的本质特性,想指望计算机和我们高等生物一样理解语言,根本做不到。毕竟至今为止我们自己都没有完全摸清大脑的各种套路。大自然赋予了我们一颗very神秘的头颅…但是冰冷的机器也有其擅长的地方,那就是计算!我们如果能把每段语言都转化成可以计算的量,那即使再大量的运算它都能搞定!这就是自然语言处理的核心思路。计算的过程有点类似于人类逻辑思维的过程,说白了这就相当于机器的智商。整好了机器可以是T-800,红皇后,无往而不利甚至可以毁灭人类!整不好的话…试想一下,你回家的时候敲门和机器管家说“可以帮我开一下门吗?”它在屋里说:“能!”然后…就没有然后了。那你破门而入之后第一件事肯定是拆了它。机器肯定不服啊!心想昨儿晚上你搂着我的时候说“可以帮我保守秘密吗”,我回答“能”你很高兴啊,怎么现在我也回答“能”你就要弄死我…这两个问题看起来没毛区别啊!

由此可见,想让机器明白人语言中的意图是很有挑战的一件事儿。接下来的数月时间,我就和各位一起迎接这个挑战。于之前不同的是,这次我们是站在同一个起跑线上的,对于NLP,我现在也是个雏儿,不过我是个站在巨人肩膀上的雏儿。我会借助我们NLP团队的各位大咖,不断深入的探索他们的研究成果,汲取他们的精华,解锁NLP的各项技能。本文更像我学习的心得笔记,可以清晰地看出一个由浅入深的过程和我解决问题的思路,以及我蠢萌的各种心理。由于有各位高手把关,文章知识的权威性绝对毋庸置疑。文章的风格当然还是一贯的正经、亲民。
经常看到某某作品在前言部分写到,本文预设读者是XXX领域研究者、XXX从业者,我也跟个时髦,本文预设的读者是有计算机基础的AI爱好者!文章中可能涉及到的有阶段性成果的领域包括:智能客服,智能问答系统,医疗问诊,旅游,评论观点抽取,AI舆情系统。但不仅限于此。
处理方法
想必各位看客中有对于NLP完全不了解的,如果有那就太好了,请坚持观看!我们的文章就是面向大众AI爱好者的!这一章我们先抛开技术细节不谈(毕竟臣妾也在学习中…),来大致的看一下自然语言处理都在干些什么,我会挑选一些比较有代表性的处理环节,就不面面俱到了。
预处理
预处理的意思就是对语句进行计算前的处理,把每一句话格式化成统一的数据格式。那咱就先说说汉语处理所避之不开的一个步骤:分词。
分词很好理解,就是把一句话切分成一个一个的词。这算是我们大天朝的特色了吧,因为英文根本不需要分词啊!英文单词之间是以空格作为自然分隔符的。而我们复杂的汉语,以句子为单位,但从这个层面上来说,处理中文的难度要比处理英文上几个台阶。
别小看了分词,在NLP中这是极其重要也比较复杂的一步!肯定有不少朋友接触过lucene、elasticsearch、solr等检索服务器,对jieba分词,IK-Analyzer等分词器一定不陌生。确实和NLP的分词有相似之处,我们也会用到这些分词器,但是随着研究的深入,只做字面上的分词已经有些力不从心了。我们还需要基于语义理解、统计等原理,对语言进行理解性的分解,其中最常用的应该属HMM(隐马尔科夫模型),CRF(条件随机场)了。
市面上绝大多数的自然语言处理方法都是基于分词的,但也不是说没有不分词的,正某人也曾经见过对单个字符进行处理的,大概的思路就是分字,然后每个字进行向量化去计算(把中文用英文的处理方式来处理)。我们先不讨论算法上的可行性和计算难度。想必单个字是没有词性的,直接导致歧义满天飞啊!就拿“牛”这个字来说,单拿出来你能说他是名词还是形容词吗?你说通过上下文判断来修正?那你上下文也都是一个字一个字的…这计算的复杂度可想而知。我对这种处理方式不看好,保持观望态度。
听起来就很厉害吧!下一章,我们将在首战挑战分词技术,介时详细讲解各种各样的黑科技,千万不要错过。
分完词,预处理还不算完。还得继续进行一些规范化和去停用词。规范化包括数字和号码的区分,阿拉伯数字和汉语数字的转换,是否保留标点符号等。去停用词(stop words),就是去掉一些没有什么实际意义的词,比如“的”、“了”、“呢”。或者根据你的需求去掉一些词,比如你只处理名词等。就是为了简化样本,可以节约空间并提高效率,后文我们实际用到的时候再细细体会。
向量化
我们再来介绍一个极其重要的步骤:向量化。上文说了机器是不能直接处理汉字的,哪怕是分好的词他也束手无策。我们还得嚼碎了喂给它…把这些词转化为机器可以直接用来计算的向量,转化方法有最基础的one-hot,tf-idf,还有谷歌开源的word2vec,都在我们涉猎的范围。如果后续的处理中带有情感分析、聚类相似词等步骤的,可以说是必须要进行向量化的。只可惜正某人现在对这些理解的也比较浅,稍后肯定会奉上精彩内容。
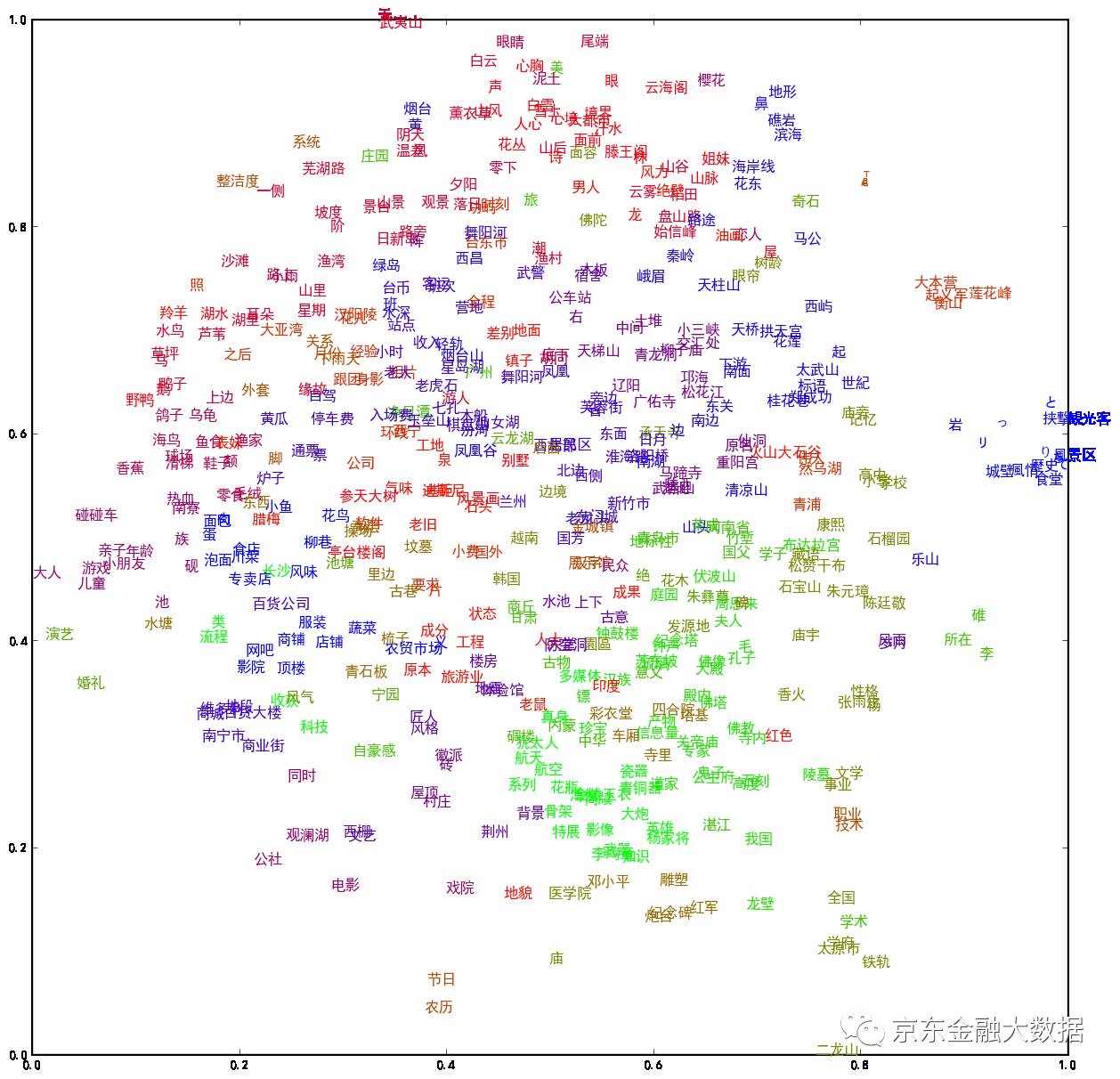
注:旅游评论分词聚类
另一个不做向量化的分支,可以直接标注词性或者直接对句法进行分析,这里的典型代表就是哈工大的语言云和斯坦福NLP,效果也是相当可以。
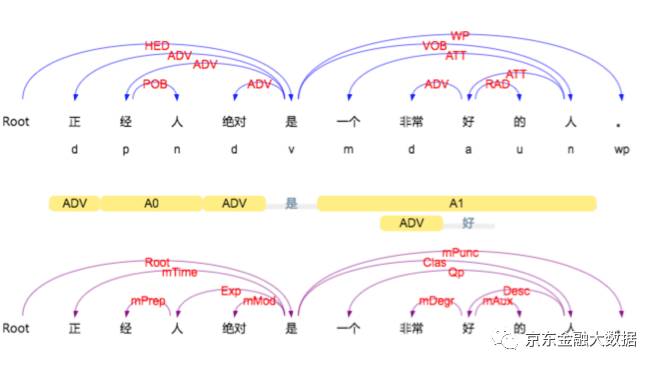
注:哈工大语言云在线演示
可以看出来词性标注和我们汉语中的“主谓宾定状补”还是有一定的区别的,分的要更加细致。
还有一些很重要的技术点,包括可以说是难度最大的消除歧义,语义理解,LDA主题模型,利用现在最火的CNN、RNN进行训练等等高科技,后续文章中肯定是一应俱全!具体就不做赘述了(臣妾现在也不会啊TAT)。
应用场景
NLP已经早已经悄悄地随风潜入夜,滋润着我们生活的方方面面了。曾几何时,以头条为代表的新闻类APP越来越吸引你,总能把有趣的新闻推送给你,就好像给你量身定做的;当你有疑问,想要询问客服的时候,再也不用排队了。总有一个秒回的小姐姐一直守候着你;在首富家或某东买东西的时候,再也不需要翻阅冗长的评论,几个标签言简意赅的准确的描述了该商品。
这些都是NLP为我们谋的福利。对文章进行分词,加权,可以准确的总结文章的主题,再综合用户的阅读习惯,可以做到精准推荐;通过分析客户咨询的问题,向量化后基于文本的相似性,定位最接近的问题,机器人客服可以准确地回答你问题;通过对商品的评论信息进行语义分析,情感分析,总结出现最多的正面评价,负面评价,一目了然的展示给更多用户。
假以时日,我前文中提到的机器管家的还会远吗?
以上是关于正经说-自然语言处理的主要内容,如果未能解决你的问题,请参考以下文章