贝叶斯公式在自然语言处理中的应用
Posted 六等星F
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了贝叶斯公式在自然语言处理中的应用相关的知识,希望对你有一定的参考价值。
统计学中有一个基本的工具叫贝叶斯公式,原理是支持某项属性的事件发生得愈多,则该属性成立的可能性就愈大。一个浅显易懂的例子:因为学生经常去教室上课,如果一个人经常去教室上课,那么这个人多半是学生。
贝叶斯公式可以表述为
P(A|B)=P(B|A)*P(A)P(B)
其中:
P(A)为不考虑任何B方面的因素A事件发生的概率
P(B)为不考虑任何A方面的因素B事件发生的概率
P(A|B)为已知B事件确定会发生时A事件发生的概率
P(B|A)为已知A事件确定会发生时B事件发生的概率
情感分析是机器学习领域自然语言处理的一个关键问题:判断一句评价/点评/影评的正/负倾向性。情感分析的应用场景很广泛,例如电子商务中用户关于购物产品的质量体验、公司根据用户反馈竞争对手的弱点来指定营销策略、对文本词汇的可视化分析等等。
词袋模型是一种基于频率的统计方法,它假设文本的正负倾向性不依赖于词汇出现的顺序,仅统计文章中各个词汇出现的频率。
应用词袋模型进行文本情感分析时,文档中每个词对应空间中一个单位向量。有朴素贝叶斯假设:如果给定目标值时属性之间相互条件独立,则有
A:正/负情感
B:文档向量
已知文档是否正向,需要知道这篇文档出现的概率,则只需将每个词在已知这个词代表的正负情感时出现的概率依次相乘。
由于P(B)是一个常数,因而P(A|B)与P(B|A)*P(A)成正比。与将朴素贝叶斯假设公式两边同乘P(A)得到
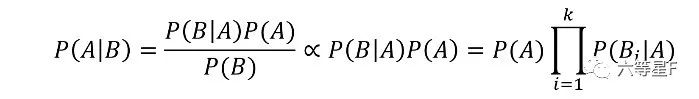
进行判定时只需分别计算P(A=1|B)和P(A=0|B),若P(A=1|B)>P(A=0|B)则文档判定为正向文档,反之则为负向文档。
而进行训练时则需要统计所有文档中正负向文档各自的比例以及各个词在正/负向文章中出现的概率。

demo实现:(使用python库snowNLP)
SnowNLP是一个python写的类库,可以方便的处理中文文本内容。如中文分词、词性标注、情感分析、文本分类、提取文本关键词、文本相似度计算等。
python代码:
# coding=utf-8
from snownlp import SnowNLP
import sys
import json
arg = sys.argv
c = SnowNLP(unicode(arg[1], "utf-8"))
string = ""
output = {"sentiments": c.sentiments}
for i in c.words:
string += i
string += "|"
output["words"] = string
output["pinyin"] = c.pinyin
print (json.dumps(output))
java后端主要代码:
byte[] bytes = new byte[10240];
try {
InputStream inputStream = Runtime.getRuntime().exec("python /root/test.py " + emInEntity.getText()).getInputStream();
inputStream.read(bytes);
} catch (IOException e) {
e.printStackTrace();
}
String trim = new String(bytes).trim();
java后端调用python脚本并处理结果。
前端页面代码省略(采用html5+angularJs)
实现效果:
火狐浏览器:
手机端:
http://104.194.157.10:8080/em/
以上是关于贝叶斯公式在自然语言处理中的应用的主要内容,如果未能解决你的问题,请参考以下文章