深度学习浪潮中的自然语言处理技术
Posted 哈工大SCIR
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习浪潮中的自然语言处理技术相关的知识,希望对你有一定的参考价值。
本文发表于 《中国人工智能学会通讯》第6卷第7期
1. 引言
语言是思维的载体,是人类交流思想、表达情感最自然的工具,也是人类区别其他动物的本质特性。自然语言处理(Natural Language Processing,简称NLP)主要研究用计算机来处理、理解以及运用人类语言(又称自然语言)的各种理论和方法,属于人工智能领域的一个重要的研究方向,是计算机科学与语言学的交叉学科,又常被称为计算语言学[1]。随着互联网的快速发展,网络文本成爆炸性增长,为自然语言处理提出了巨大的应用需求。同时,自然语言处理研究的进步,也为人们更深刻的理解语言的机理和社会的机制提供了一种新的途径,因此具有重要的科学意义。
随着深度学习技术在越来越多的任务中所取得的突破性进展,有越来越多相关领域的学者将注意力转移到了人工智能皇冠上的那颗明珠—自然语言处理问题上。如著名的机器学习专家,美国加州大学伯克利分校的 Michael Jordan教授说:“如果有一笔10亿美金的资助,我会将它用于自然语言处理的研究”。深度学习研究的领军人物之一,美国纽约大学教授、Facebook人工智能研究院负责人Yann LeCun也曾表示“深度学习的下一个前沿课题是自然语言理解”[2]。
然而,由于自然语言所具有的歧义性、动态性和非规范性,同时语言理解通常需要丰富的知识和一定的推理能力,这些都为自然语言处理带来了极大的挑战。目前,机器学习技术为以上问题提供了一种可行的解决方案,成为研究的主流,该研究领域又被称为统计自然语言处理[3]。一个统计自然语言处理系统通常由两部分组成,即训练数据(也称样本)和统计模型(也称算法)。我们总结了目前自然语言处理中常用的模型和数据,如下表所示:
但是,传统的机器学习方法在数据获取和模型构建等诸多方面,都存在严重的问题:首先,为获得大规模的标注数据,传统方法需要花费大量的人力、物力、财力,雇用语言学专家进行繁琐的标注工作。然而由于这种方法存在标注代价高、规范性差等问题,很难获得大规模高质量的人工标注数据,由此带来了严重的数据稀疏问题。
其次,在传统的自然语言处理模型中,通常需要人工设计模型所需要的特征以及特征组合。这种人工设计特征的方式,需要开发人员对所面对的问题有深刻的理解和丰富的经验,这会消耗大量的人力和时间,即便如此也往往很难获得有效的特征。
近年来,如火如荼的深度学习技术为这两方面的问题提供了一种可能的解决思路,有效推动了自然语言处理技术的发展。那么,什么是深度学习,它究竟给自然语言处理带来了哪些创新性的想法,如何将深度学习技术更好的应用于自然语言处理,深度学习与自然语言处理的未来研究方向是什么呢?本文试图就这些问题加以回答。
2. 基于深度学习的自然语言处理
深度学习旨在模拟人脑对事物的认知过程,一般是指建立在含有多层非线性变换的神经网络结构之上,对数据的表示进行抽象和学习的一系列机器学习算法。该方法已对语音识别、图像处理等领域的进步起到了极大的推动作用,同时也引起了自然语言处理领域学者的广泛关注。
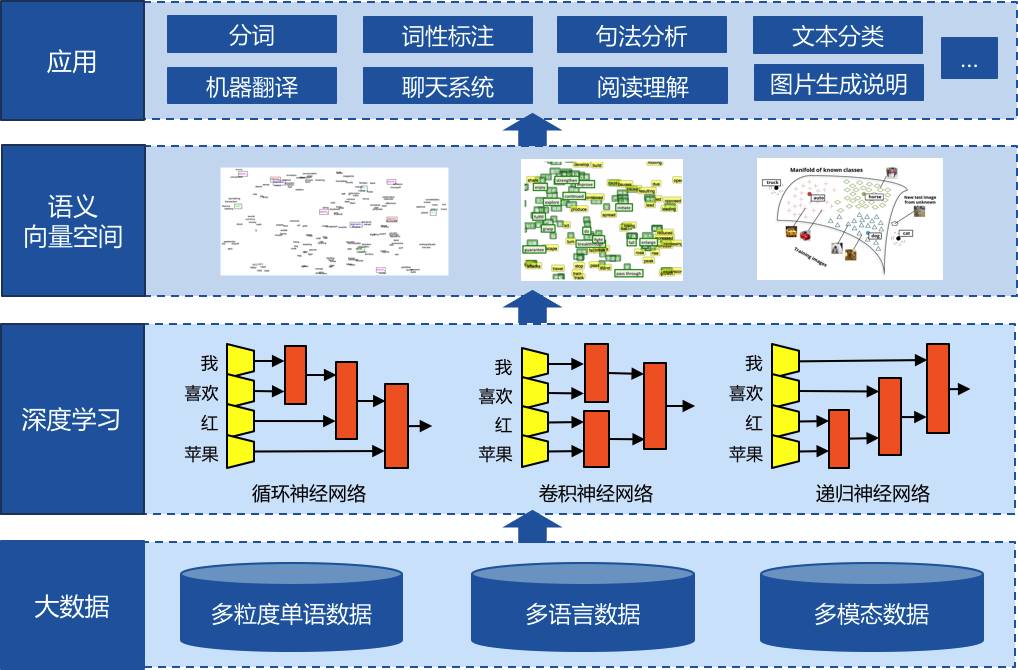
如下图所示,深度学习为自然语言处理的研究主要带来了两方面的变化:一方面是使用统一的分布式(低维、稠密、连续)向量表示不同粒度的语言单元,如词、短语、句子和篇章等;另一方面是使用循环、卷积、递归等神经网络模型对不同的语言单元向量进行组合,获得更大语言单元的表示。除了不同粒度的单语语言单元外,不同种类的语言、甚至不同模态(语言、图像等)的数据都可以通过类似的组合方式,表示在相同的语义向量空间中,然后通过在向量空间中的运算来实现分类、推理、生成等各种能力,并应用于各种相关的任务之中。下面我们分别对这两方面加以详细的阐述:
2.1 分布式表示(Distributed Representation)
深度学习最早在自然语言处理中的应用是神经网络语言模型[4],其背后的一个基本假设是使用低维、稠密、连续的向量表示词汇,又被称为分布式词表示(Distributed Word Representation)或词嵌入(Word Embedding)。从直觉上来讲,使用该项技术,可以将相似的词汇表示为相似的向量,如“马铃薯”和“土豆”的词向量比较相似。这样,如果我们在训练数据中只观察到了“马铃薯”,即使在测试的时候出现了“土豆”,我们也能通过词向量判断其与“马铃薯”比较相似,从而在一定程度上缓解了自然语言处理中常见的数据稀疏问题。
在理论上,将原有高维、稀疏、离散的词汇表示方法(又称One-hot表示)映射为分布式表示是一种降维方法,可有效克服机器学习中的“维数灾难(Curse of Dimensionality)”问题,从而获得更好的学习效果。同时这种分布式表示的表达能力更强,理论上其表达能力与其维度成指数关系,而传统离散表示是线性关系。另外一种对分布式词表示的理解是,不同维度表示了词的不同主题,各维度上的数值表示了一个词对于不同主题的权重,这相当于将原来线性不可分的一个词抽取出其各个属性,从而更有利于分类(最终还是线性分类)。这就好比我们要区分不同种族的人,只通过人名(相当于传统的离散词表示方式)不好区分,而如果能将每个人抽取出各种“属性-值”对(相当于转换为分布式词表示),如眼睛的颜色、鼻子的高度等,就更容易进行人种的区分了。
分布式词表示近年来被广泛应用于自然语言处理中,通常有直接和间接两种应用方式。所谓直接应用,即使用学习到的分布词表示进行词语之间的相似度计算或者句法语义关系的学习。事实上,对词语之间相似度的表达能力,也一度被用于评价学习获得的分布式词表示,常用的评测集有WordSim-353 (英文)等。
另一方面,分布式词表示能够在一定程度上表达特定的句法语义关系则是其另一个非常有趣的性质。这种性质首先由Mikolov等发现[5],他们通过对数据的观察,发现满足相同句法或语义关系的两个词对,其分布式表示的差向量也非常接近,如:V(“Woman” )-V(“Man” )≈V(“Queen” )-V(“King” )。这意味着,只需要通过简单的向量运算,就可以表达词汇之间所蕴含的句法或语义关系。该性质后来被广泛应用于知识图谱(Knowledge Graph)或本体(Ontology)的构建等任务[6]。
分布式词表示的另一方面应用为间接应用,即将其作为上层系统的输入,利用该表示的各种优秀性质,提高上层系统的准确率。最简单的做法是将分布式词表示作为额外的特征输入给上层系统[7],这样上层系统可以不进行任何修改,仍然使用传统的线性模型,通过分布式词表示增强词汇特征的泛化能力,提高准确率。另一种做法是将上层系统替换为多层非线性神经网络模型,这样分布式词表示在作为特征输入给系统的同时,也可以通过反向传播机制进行微调(Fine-tuning),从而更加适用于具体的自然语言处理任务。
2.2 语义组合(Semantic Composition)
分布式词表示的思想可以进一步扩展,即通过组合(Composition)的方式来表示短语、句子甚至是篇章等更大粒度的语言单元。目前,主要通过三种神经网络结构来实现不同的组合方式,即:循环神经网络(顺序组合)、卷积神经网络(局部组合)和递归神经网络(根据句法结构进行组合)[8]。下面我们以句子“我 喜欢 红 苹果”为例,说明不同组合方式的基本原理及其优缺点,具体可以参见上图中“深度学习”部分。
循环神经网络(RNN,Recurrent Neural Network)从左至右顺序的对句子中的单元进行两两组合,首先将“我”和“喜欢”组合,生成隐层h1,然后将h1与“红”进行组合,生成h2,以此类推。传统的循环神经网络模型存在严重的梯度消失(Vanishing Gradient)或者梯度爆炸(Exploding Gradient)问题,尤其是当句子较长,即网络的层数较多时。深度学习中一些常用的技术,如使用ReLU激活函数、正则化以及恰当的初始化权重参数等都可以部分解决这一问题。另一类更好的解决方案是减小网络的层数,以LSTM和GRU等为代表的带门循环神经网络(Gated RNN)都是这种思路,即通过对网络中门的控制,来强调或忘记某些输入,从而缩短了其前序输入到输出的网络层数,从而减小了由于层数较多而引起的梯度消失或者爆炸问题。
卷积神经网络(CNN,Convolutional Neural Network)目前被广泛应用于图像处理领域,它考虑了生物神经网络中的局部接收域(Reception Field)性质,即隐含层神经元只与部分输入层神经元连接,同时不同隐含层神经元的局部连接权值是共享的。这一性质在很多自然语言处理的任务中也有所体现,如对评论文本进行分类,最终的褒贬性往往由局部的一些短语决定,同时不需要顾及这些短语在文本中的位置信息。例如,只要评论中含有“我 喜欢”,就说明该评论是褒义的。由于存在局部接收域性质,各个隐含神经元的计算可以并行的进行,这就可以充分利用现代的硬件设备(如GPU),加速卷积神经网络的计算,这一点在循环神经网络中是较难实现的。
递归神经网络(RecNN,Recursive Neural Network)首先对句子进行句法分析,将顺序结构转化为树状结构,然后利用该结构来构建深度神经网络。因此在对句子“我 喜欢 红 苹果”进行组合时,首先组合“红”和“苹果”,生成隐层h1,然后再组合“喜欢”和h1,获得h2,以此类推。由此可见,该方法充分考虑了语言的递归组合性质,不会出现在循环或者递归神经网络中可能出现的任意无意义的组合,如“喜欢 红”等。同时,对于如语义关系分类等任务,往往需要识别两个距离较远的实体之间的语义关系,如句子“在哈尔滨工业大学本科生院成立典礼上,校长周玉表示,……”中,“哈尔滨工业大学”和“周玉”距离较远,他们中间的词汇往往对循环或者卷积神经网络模型构成了干扰,而递归神经网络利用句法结构,会将两个实体的距离拉近,从而去除不必要的干扰,提升分析的准确率。当然,递归神经网络模型也受限于句法分析的准确率,因为一旦句法分析出现了错误,则会产生错误的组合方式,从而影响最终的结果。
2.3 应用
通过组合,产生不同粒度语言单元的(向量)表示方式,然后通过在向量空间中的运算,就可以支撑多种多样的应用。例如,想要识别两个句子是否互为复述(Paraphrase),就可以使用以上任意一种神经网络结构,将两个句子分别表示为两个向量,并通过在其之上再构建神经网络构成二元分类器的方式,判断两个向量之间是否互为复述[9]。然后通过反向传播(Back Propagation)算法,就可以学习获得三个神经网络的参数。
另外,两个单元也可以是不同的粒度,如完形填空,空白处的上下文可以使用神经网络表示为向量,候选词也可以使用向量表示,然后同样使用另一个神经网络模型判断它们之间是否匹配从而判断填入该词是否合适。
这种以向量的形式表示,然后再计算的思想可以扩展为多种语言,从而实现机器翻译等功能。对于机器翻译,我们首先将源语言表示为向量,该向量代表了源语言的语义信息,然后根据该向量,逐词的生成目标语言[10]。这套方法又被称为编码-解码(Encoder-Decoder)或者序列到序列(seq2seq,sequence to sequence)的框架。现实情况中,很难用一个向量表示源语言全部的信息,所以在生成一个目标语言词的时候,如果能有其对应的源语言词作为输入,则生成的词会更准确。由于两种语言之间的词并非一一对应,所以很难判断当前的目标语言的词是由那个源语言生成的,于是人们设计出注意力(Attention)机制[11],即当前目标语言的词是全部源语言的词经过加权求和后的向量及前一个目标词的隐含层向量(ht-1)共同生成的,每个权重由ht-1和每个源语言词的隐层向量(hs)共同决定,源语言的词权重越大说明其对生成该目标语言的贡献越大,这其实也隐含说明这两个词越对齐。
以上的这种seq2seq思想又可以进一步被应用于更多的自然语言处理任务中,如抽象式文摘(Abstractive Summarization)这一前人很难触及的任务。传统的文摘研究多集中于抽取式文摘(Extractive Summarization),即从篇章中摘取重要的句子组成文摘,而缺乏有效的手段能够将句子打破。基于seq2seq技术,就可以将原文表示为一个向量,然后通过该向量,逐词的生成连贯的文摘,从而不受限于必须抽取原文中的句子。
再进一步将该思想进行扩展,我们是否也可以将图片或者视频表示为向量,然后在生成对应的文字描述呢?这正是图像字幕生成(Image Caption Generation)这一非常有趣的研究任务所采用的基本思想,其中图像的向量可以由卷积神经网络来生成[12]。
另外,一些传统的自然语言处理任务,如词性标注、句法语义分析等也都受益于深度学习方法。我们以基于转移的句法分析器为例,该方法使用一系列由初始到终止的状态(State或Configuration)表示句法分析的过程,一个状态经过一个转移动作(Action),如移进(Shift)或归约(Reduce),变为一个新的状态。我们的目的就是要学习一个分类器,其输入为一个状态,输出为该状态下最可能的动作。具体介绍可以参见Google最新发布的SyntaxNet文档 ( )。传统的方法通过抽取一系列人工定义的特征来表示状态,即分类的依据,如栈(Stack)顶的词、词性,缓存(Buffer)顶的词、词性以及各种特征组合等。显然,这种人工定义特征的方式存在特征定义不完备等问题。因此, 可以采用任一种神经网络结构,如LSTM循环神经网络[13],来更全面地表示一个状态,从而省去了繁琐的特征定义过程,并能够获得更好的分类效果。
2.4 数据
在应用以上深度学习模型的过程中,一个比较棘手的问题是随着网络变得越来越复杂,其表示能力也越来越强,其中的参数也越来越多,由此带来的问题是如果训练数据规模不够大,则很容易使模型陷入过拟合的状态。
传统利用语言学专家进行数据标注的方法需要花费大量的人力、物力、财力,存在标注代价高、规范性差等问题,很难获得大规模高质量的人工标注数据。为了解决数据获取的难题,比较直接的是利用众包的方式获取大规模的标注数据。当然,对于大公司而言,还可以利用宝贵的平台数据,如搜索引擎的日志、聊天记录等。除此之外,还可以利用大规模的弱标注数据,其实生文本自身就是非常有价值的弱标注数据,借此我们已经能够训练语言模型、词或句子的分布式向量表示等等。另外,我们还需要积极寻找大规模的弱标注数据,如DeepMind曾利用新闻网站提供的人工新闻摘要数据自动生成完型填空数据[14]、电子商务网站中用户对商品的评分数据等等。
最后,受到图像处理研究的启发,我们还可以利用大规模人工自动构造数据,如可以通过对原始图像进行旋转、伸缩等操作,获取更多的训练图像,在自然语言处理中,是否也可以通过对文本进行一定的变换,从而获得大规模的训练数据呢?如将正规文本中的词随机地替换为错误的词,从而构建语法纠错任务的训练数据等。相关的研究还处于起步阶段,相信今后会被给予更多的关注。
3. 总结
通过分布式表示以及语义组合这两个特性,深度学习为自然语言处理带来了很多新的发展机遇:一方面可以通过更好地表达特征,来提高自然语言处理系统的性能;另一方面通过seq2seq等机制,实现过去较难实现的一些任务。为了更好地训练深度学习模型,寻找和构建大规模弱标注数据成为我们需要关注的另一个主要的研究方向。
基于深度学习的自然语言处理技术方兴未艾,不但目前已近取得了良好的效果,而且具有非常广阔的研究前景。首先,可以进一步发挥分布式表示和语义组合的潜力,拓展更多的应用,如目前被很多大公司关注的阅读理解问题;其次,除了多粒度、多语言以及多模态以外,不同的学习任务也可以共享同一套向量表示,从而将一种任务中学习获得的表示应用于另一种任务中,实现迁移学习或多任务学习这些更类似人类学习的方式;再次,很多自然语言处理任务,如对话生成,有赖于更大的上下文或者语境的,传统基于人工定义特征的方式很难对其进行建模,而深度学习模型则提供了一种对语境进行建模的有效方式;最后,无论何种神经网络模型,都是基于固定的网络结构进行组合,我们是否有可能基于动态变化的网络结构进行学习呢?传统的有监督学习框架很难实现该目标,而强化学习(Reinforcement Learning)框架为我们提供了一种自动学习动态网络结构的途径。
参考文献
[1] 宗成庆, 统计自然语言处理, 北京: 清华大学出版社, 2013.
[2] C. Manning, “Computational linguistics and deep learning,” Computational Linguistics, 41(4), pp. 701-707, 2015.
[3] C. Manning , H. Schütze, Foundations of Statistical Natural Language Processing, Cambridge, MA: MIT Press, 1999.
[4] Y. Bengio, R. Ducharme, P. Vincent , C. Jauvin, “A Neural Probabilistic Language Model,” Journal of Mahcine Learning Research, 2003.
[5] T. Mikolov, W.-t. Yih 和 G. Zweig, “Linguistic Regularities in Continuous Space Word Representations,”NAACL-HLT-2013, Atlanta, 2013.
[6] R. Fu, J. Guo, B. Qin, W. Che, H. Wang , T. Liu, “Learning Semantic Hierarchies: A Continuous Vector Space Approach,”ACL-2014, Baltimore, 2014.
[7] J. Guo, W. Che, H. Wang, T. Liu, “Revisiting Embedding Features for Simple Semi-supervised Learning,”EMNLP-2014, Doha, 2014.
[8] Y. LeCun, Y. Bengio, G. Hinton, “Deep Learning,” Nature, 2015.
[9] R. Socher, H. Eric, J. Pennington, A. Y. Ng, C. D. Manning, “Dynamic Pooling and Unfolding Recursive Autoencoders for Paraphrase Detection,”NIPS-2011, Granada, 2011.
[10] D. Bahdanau, K. Cho, B. Yoshua, “Neural Machine Translation by Jointly Learning to Align and Translate,” CoRR, abs/1409.0473, 2014.
[11] V. Mhih, N. Heess, A. Graves, K. Kavukcuoglu, “Recurrent Models of Visual Attention,”NIPS-2014, 2014.
[12] Karpathy and L. Fei-Fei, “Deep Visual-Semantic Alignments for Generating Image Descriptions,”CVPR-2015, 2015.
[13] Dyer, M. Ballesteros, W. Ling, A. Matthews, N. Smith, “Transition-Based Dependency Parsing with Stack Long Short-Term Memory,”ACL-2105, Beijing, 2015.
[14] K. M. Hermann, T. Kočiský, E. Grefenstette, L. Espeholt, W. Kay, M. Suleyman, P. Blunsom, “Teaching Machines to Read and Comprehend,” CoRR, abs/1506.03340, 2015.
作者简介:
编辑部:郭江,李家琦,徐俊,李忠阳,俞霖霖
本期编辑:李家琦
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。点击左下角“阅读原文”,即可查看原文。
以上是关于深度学习浪潮中的自然语言处理技术的主要内容,如果未能解决你的问题,请参考以下文章
车万翔《基于深度学习的自然语言处理》中英文PDF+涂铭《Python自然语言处理实战核心技术与算法》PDF及代码
《基于深度学习的自然语言处理》中文PDF+英文PDF+学习分析