基于NLTK的Python自然语言处理-字符串的操作(切分)
Posted 自然语言处理爱好者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于NLTK的Python自然语言处理-字符串的操作(切分)相关的知识,希望对你有一定的参考价值。
预计阅读需14分钟
上篇文档已经介绍了做自然语言处理中我们使用比较的python语言,以及使用的python集成开发环境(IDE,Integrated Development Environment )。从本篇文章将陆续介绍如何使用python进行自然语言处理。这里将参考《精通Python自然语言处理》、《Python自然语言处理》以及NLTK的官方文档http://www.nltk.org/。订阅号回复“python自然语言处理书籍”,即可获取《Python自然语言处理》电子版的百度云盘链接。不过还是建议购买或借阅纸质书籍。

由于国内网速过慢,作者已经下载完毕,读者可以点击原文链接进行下载。
需要注意的是将下载后的文档放在程序能够检测的位置
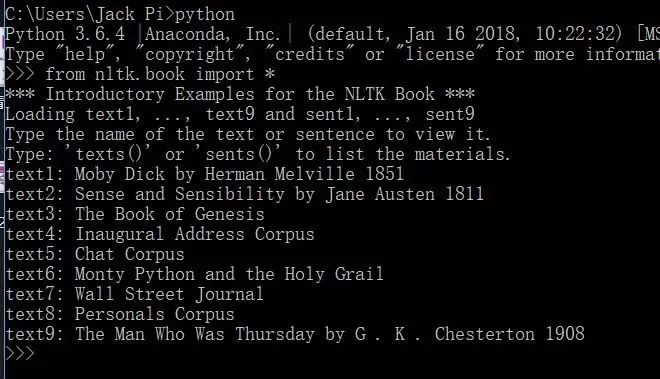
通过:from nltk.book import * 可以检测nltk是否下载成功
这里主要使用的是:sent_tokenize以及tokenizer.tokenize
from nltk.book import * #导包
#自定义一个字符串
text=" Welcome readers. I hope you find it interesting. Please do reply"
#导入nltk中tokenize下的sent_tokenize,以实现分句
from nltk.tokenize import sent_tokenize
result=sent_tokenize(text)
print(result)
结果:
[' Welcome readers.', 'I hope you find it interesting.', 'Please do reply']
应对大批量句子方法:
import nltk
#获取tokenizer对象
tokenizer=nltk.data.load('tokenizers/punkt/english.pickle')
#定义字符串
text="Hello everyone. Hope all are fine and doing well.Hope you find the book intersting"
result=tokenizer.tokenize(text)
print(result)
结果
['Hello everyone.', 'Hope all are fine and doing well.Hope you find the book intersting']
这里使用的是word_tokenize()函数,也可使用其下的TreebankWordTokenizer进行切分。
import nltk
#对需要切分的字符串进行切分
text=nltk.word_tokenize("PierreVinken, 59 years old, will join as a nonexecutive director on Nov. 29.")
print(text)
结果
['PierreVinken', ',', '59', 'years', 'old', ',', 'will', 'join', 'as', 'a', 'nonexecutive', 'director', 'on', 'Nov.', '29', '.']
使用TreebankWordTokenizer进行切分:
from nltk import word_tokenize
import nltk
#用户输入
r=input("请输入一行英文字符串:")
print("这个字符串的长度为:",len(word_tokenize(r)),"words","分词结果为:",word_tokenize(r))
结果
请输入一行英文字符串:Today is a pleasant day
这个字符串的长度为: 5 words 分词结果为: ['Today', 'is', 'a', 'pleasant', 'day']
如果出现缩略词的话使用TreebankWordTokenizer(继承于Tokenizer):
import nltk
text=nltk.word_tokenize(" Don't hesitate to ask qustions")
print(text)
结果
['Do', "n't", 'hesitate', 'to', 'ask', 'qustions']
但是效果并不是很好Don分开了,这里使用WordPunctTokenizer进行改进:
from nltk.tokenize import WordPunctTokenizer
tokenizer=WordPunctTokenizer()
print(tokenizer.tokenize(" Don't hesitate to ask qustions"))
结果
['Don', "'", 't', 'hesitate', 'to', 'ask', 'qustions']
还有的就是使用正则表达式进行切分,但是正则表达式的内容比较多,将在下篇文章进行介绍。
每日雅思
gist n.主旨,要点,依据
semiofficial adj.半官方的
orientation n.定位;熟悉情况;定向;信仰;倾向
matriculate n.被录取者 v.准许...入学
canter n.慢跑(多用于马)

以上是关于基于NLTK的Python自然语言处理-字符串的操作(切分)的主要内容,如果未能解决你的问题,请参考以下文章
在PyCharm中安装nltk,以及nltk data的下载。