电影影评的自然语言处理方法介绍
Posted TiBeing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了电影影评的自然语言处理方法介绍相关的知识,希望对你有一定的参考价值。
在人工智能行业范围内,自然语言处理(NLP)算是比较热门的一个领域。关于自然语言处理的方法也有很多种。例如,非常热门的字词向量化、分词、命名实体识别、词袋子算法、TF-IDF算法等,也有基于神经网络(RNN和CNN)进行NLP工作。
本文中,我基于NLTK 为大家简单介绍下自然语言处理如何在电影影评中应用。最主要的目的是从实战的角度讲解项目构建过程。当然,NLTK 是以英文为词库,因此,下述介绍中处理的电影影评是英文字符。
自然语言处理,即将我们日常交流的语言转换为机器可以进行处理的符号。在算法中,惯常使用的思路是Word 2 Vectors,即将字、词等向量化。这个思想很重要。一般来说,机器只能识别符号。在人工智能目前阶段,机器处理数据的本质是进行矩阵运算。等同的说,机器是在数学计算。因此,只有将字、词等向量化,机器才能进行计算。
一、构建数据
我们首先从依赖包中导入数据,接着对我们即将处理的数据进行详细的了解。
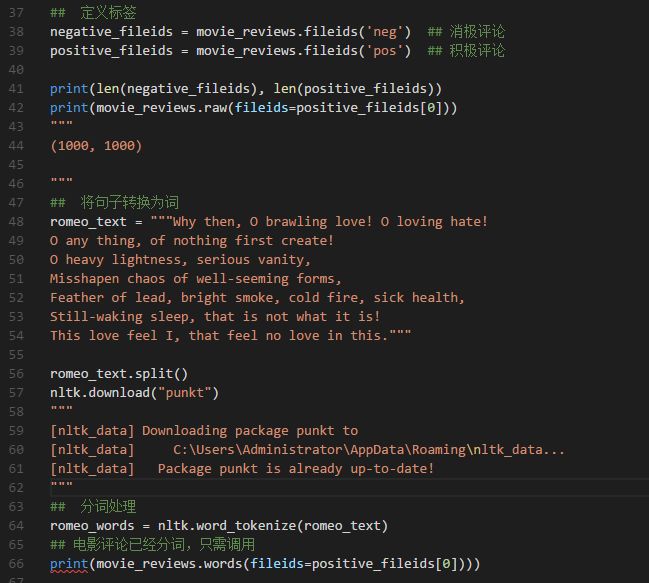
二、定义标签
我们了解数据的方法有很多种,上述方法是针对文本类数据。掌握了数据的基本情况,我们需要对数据进行标记,也就是打标签。本例子中,我们需要对电影影评数据打两个标签,一个是积极评论,一个是消极评论。
三、模型构建
本文中,我们主要使用词袋子(Bag-of-Words)算法模型。
词袋子模型。词袋子模型是基于统计。简言之,就是计算机会统计样本数据中各个词出现的频率。当然,从直观上理解,这样理解人类语言有点不符合人类思维方式,但是,从另一个角度讲,在一个大的文本中,某个词出现的频率越高,那么这个词的意义对整个文本有很重要的影响。当然,这需要除了一些经常出现却没有实际意义的词。例如,你,他,这等等。
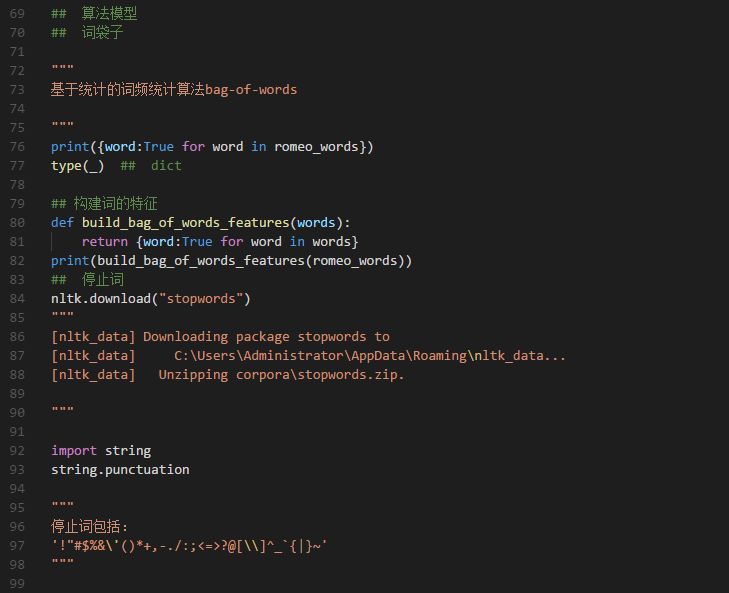
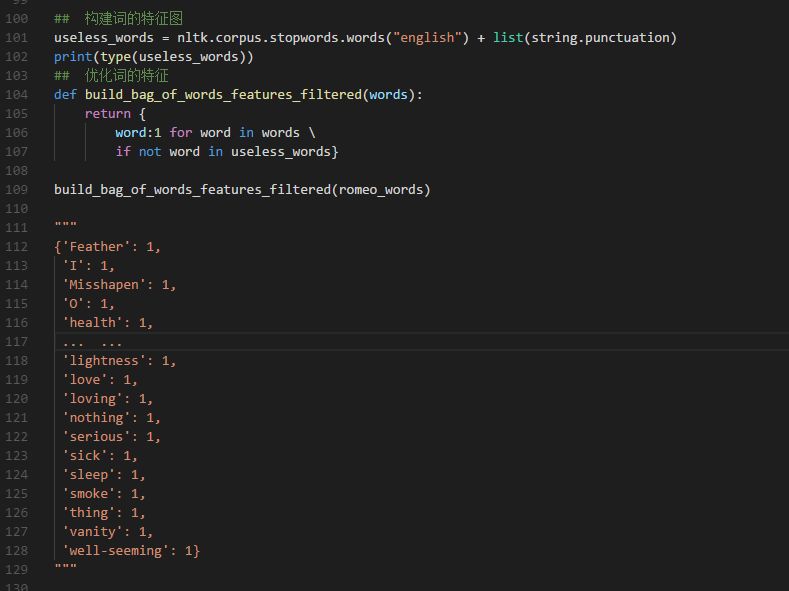
我们在对词语进行预处理的阶段,需要构建关于字词的特征图。即需要将我们认为重要或者机器能够理解我们的欲加之意能够清晰的体现出来。因此,从语言学角度讲。符号语言学更适合当前的自然语言智能化处理。
需要注意的是,在这个过程中,我们要人为的去除那些不对认知结果产生影响的特征。例如,标点符号,无意义的词语等。
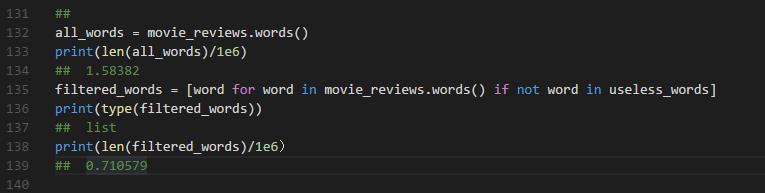
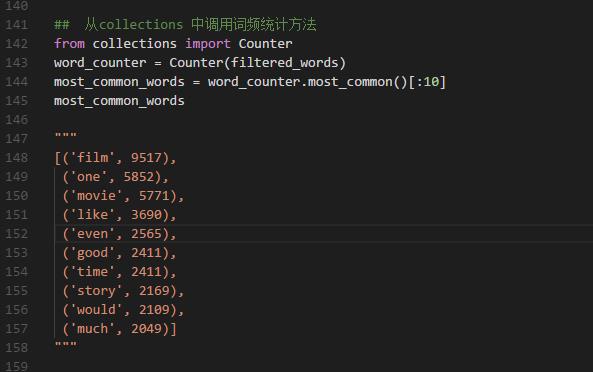
四、可视化
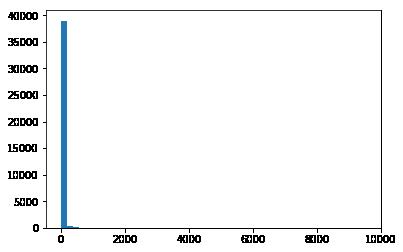
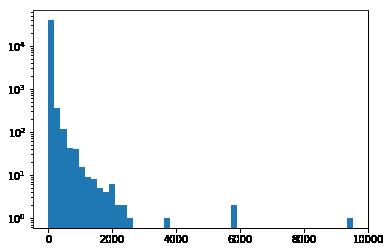
在处理机器学习问题过程中,适当的引入可视化工具,能够增强整个问题的可解释性。
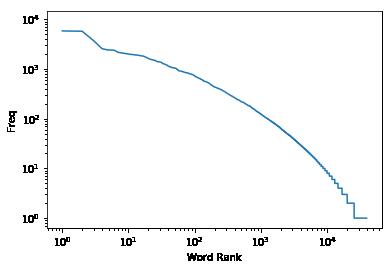
本文中,我们可以通过可视化直观的查看特征词的分布图。例如:
五、语义理解
对语言的理解需要从语型(句型式子)、语义、语境三个层面展开。在目前阶段,机器理解自然语言还不能够从深层次的语义出发,但是,也可以做到初步的从语义特征出发。这就需要我们人为的构建语义特征。本文中,我们构建积极语义和消极语义的特征。
六、模型预测
在进行了前期工作后,我么最终需要找到合适的模型,对我们的新数据进行预测。也就是说,我们优化好模型,当产生新的电影评论数据,就可以大概知道这个电影的市场反响度如何。当然,后续随着新的热词的出现,我们需要不断的重新构建词特征,以完成分析。
本篇完
“欢迎关注,后台留言,获取源码”
以上是关于电影影评的自然语言处理方法介绍的主要内容,如果未能解决你的问题,请参考以下文章
NLP⚠️学不会打我! 半小时学会基本操作 6⚠️ 电影影评分析
NLP⚠️学不会打我! 半小时学会基本操作 7⚠️ Word2vec 电影影评建模