永久免费的百度自然语言处理技术,了解一下?
Posted 简言
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了永久免费的百度自然语言处理技术,了解一下?相关的知识,希望对你有一定的参考价值。
背景
突然想起来著名的“汉语堂”发过一篇文章《》,这么大的便宜我竟然后知后觉。写篇小文,给同学们展示一下如何薅社会主义的羊毛。
正文
一、用百度账号登录百度云并创建应用
既然是要去薅羊毛,自然是首先要找到羊毛在哪里:
随便点击上面的一个链接进入,并使用自己的百度账号登录:
在左侧的“产品服务”中找到“自然语言处理”:
进入之后果然发现了一团团毛茸茸的免费的羊毛:

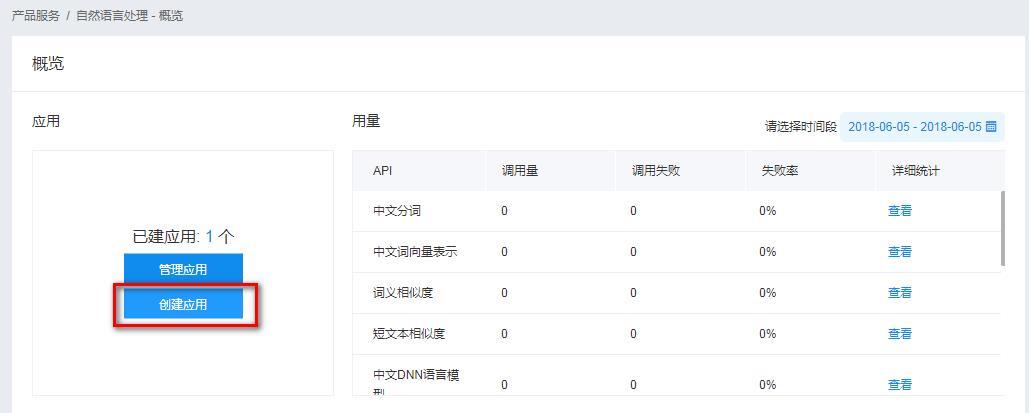
我准备试一下最下方的“词法分析(定制)”API,做一个提取文本中全部名词的小工具,于是点击了上方的“创建应用”:
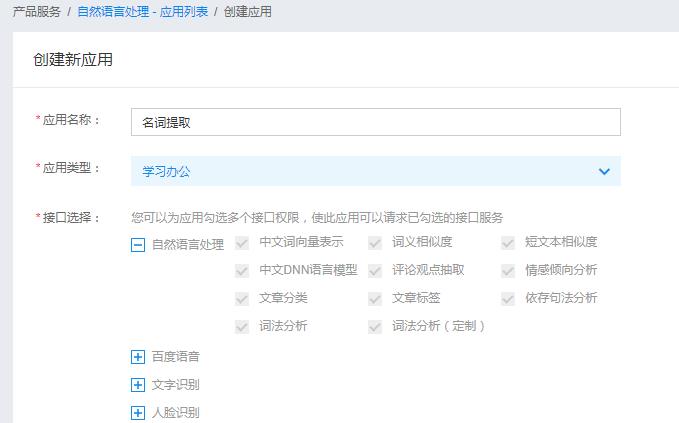
填写一下应用的名字、类型和简单描述:
点击底部的“立即创建”后看到如下的界面:

点击“查看应用详情”:
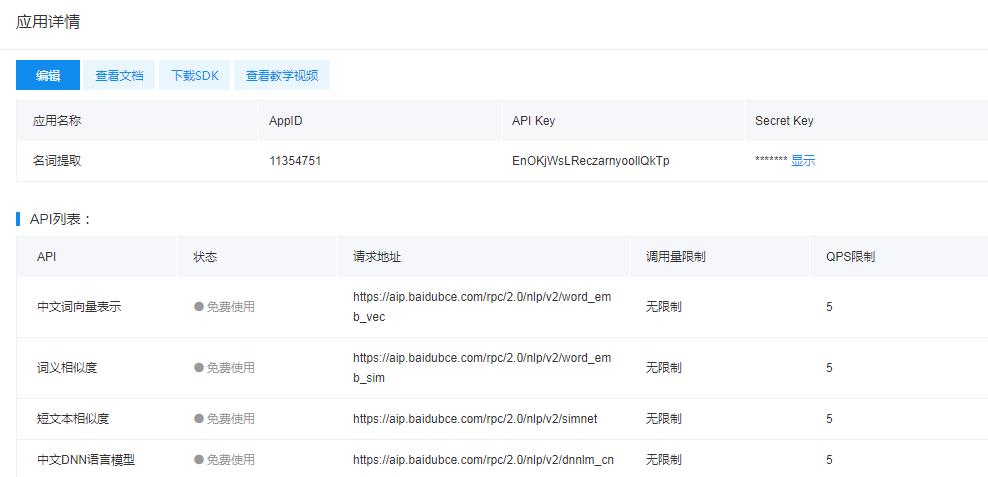
在这里我看到了百度给我的一些基本信息,这就是我用百度的自然语言处理来开发工具的“通行证”啦。
二、下载开发工具包,并在工具包内添加“通行证”
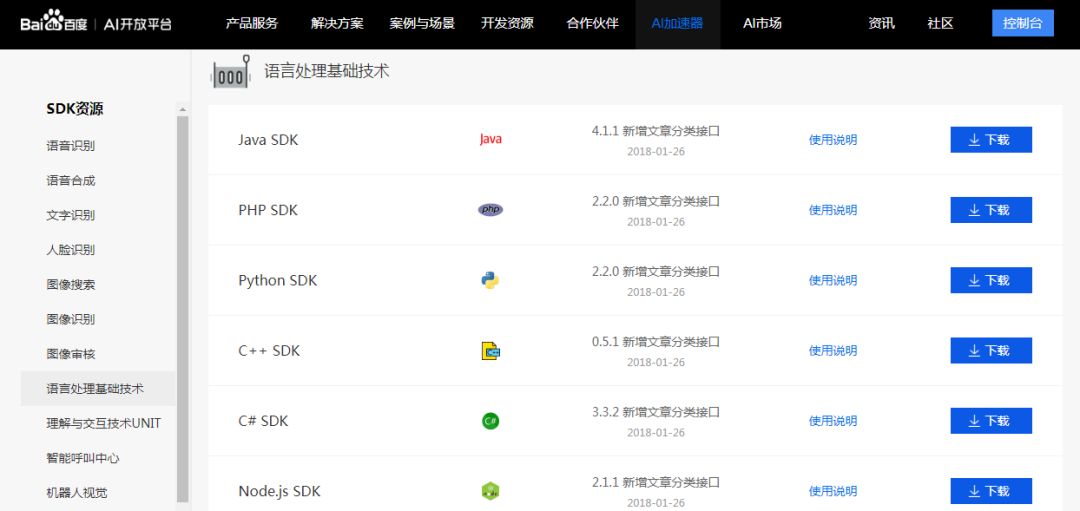
在这里可以看到面向不同开发语言的现成的开发工具。我不由自主地选择了世界上最好的编程语言“php”对应的SDK,点击了右侧的“下载”:

将文件保存到我的程序开发环境XAMPP根目录指定文件夹下:
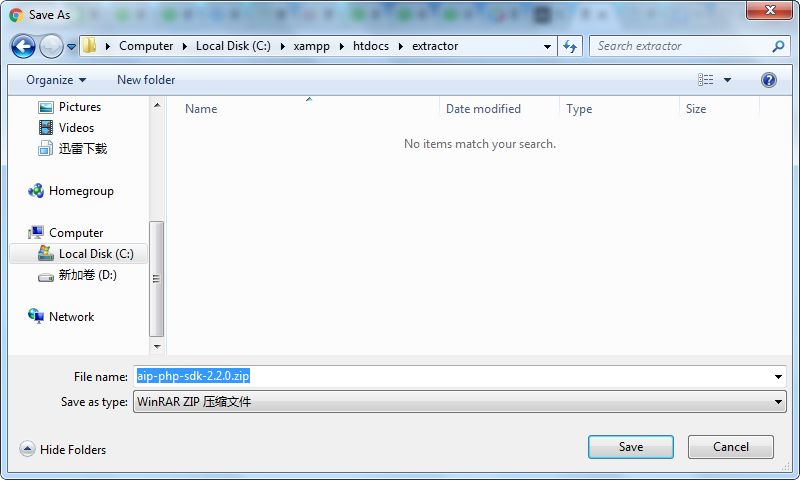
下载之后将压缩包解压,看到了如下文件:
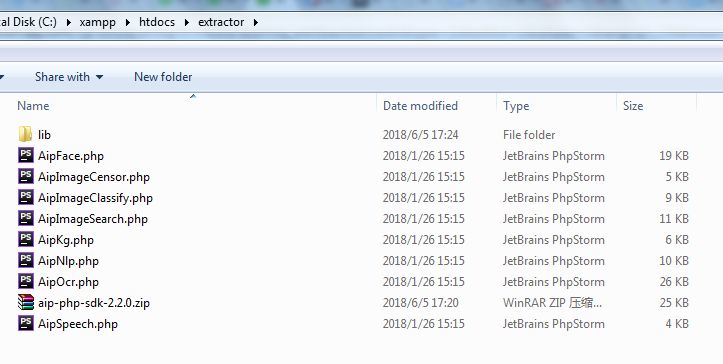
目前对我来说,只有其中的AipNlp.php文件和lib文件夹有用,其他还不需要,所以我将他们通通删掉:
这时候先不着急使用这些文件,而是先去看SDK的使用说明,点击这里的“使用说明”:
随后进入到下面这个界面:
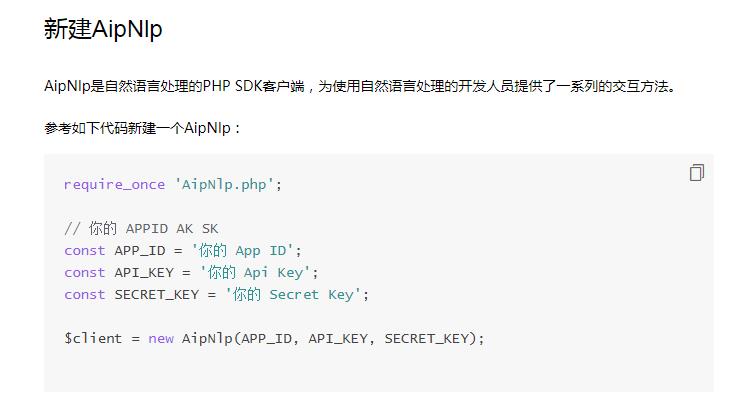
这里有比较全面的入门指南,比如非常清晰的告诉你,应该这样创建创建你的第一部分的代码:
于是我在我的开发目录中创建了一个名为“index.php”的文件,并且用编辑器打开index.php文件(这里我用的编辑器是Notepad++,也是免费的):
这是一个空白的文档,打开后将说明中的代码全部粘贴进去(注意要在两端加上<?php ?>):
然后把我刚才创建应用时生成的“通行证”添加进去:
这样我们就正式拥有了免费薅百度羊毛的工具了。
三、使用词法分析工具来分析原文
再次回到使用说明网页,拖到“词法分析(定制版)”模块:
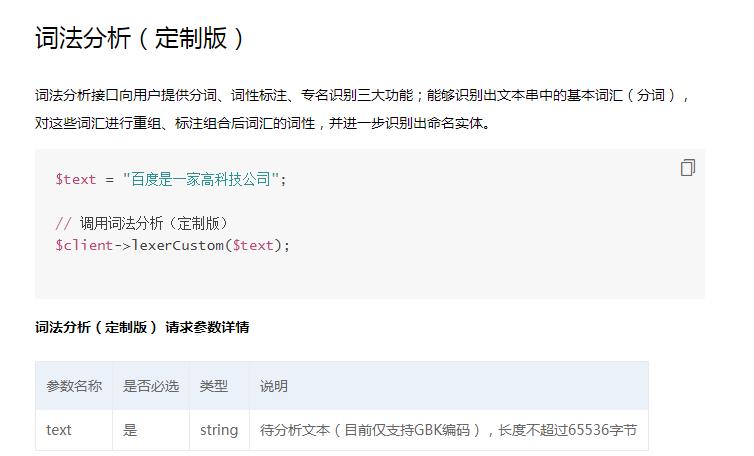
原样照搬上面的代码,粘贴到自己的index.php中:
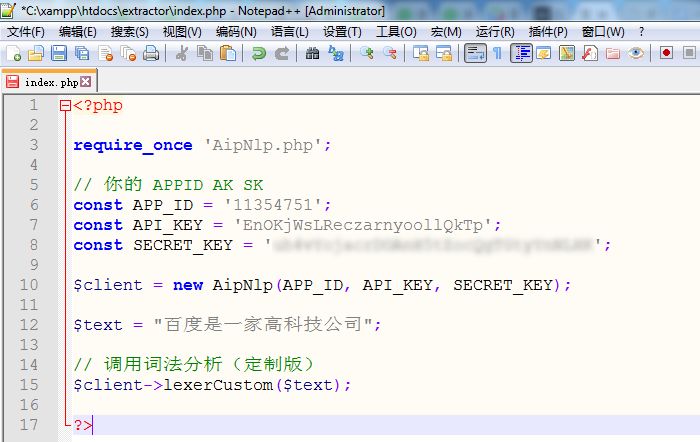
然后我想在网页中查看“百度是一家高科技公司”查看词性分析的结果,根据上面的代码,词性的分析的结果已经放到“$client->lexerCustom($text)”之中了,需要我把它显示出来,所以我这样修改一下代码:
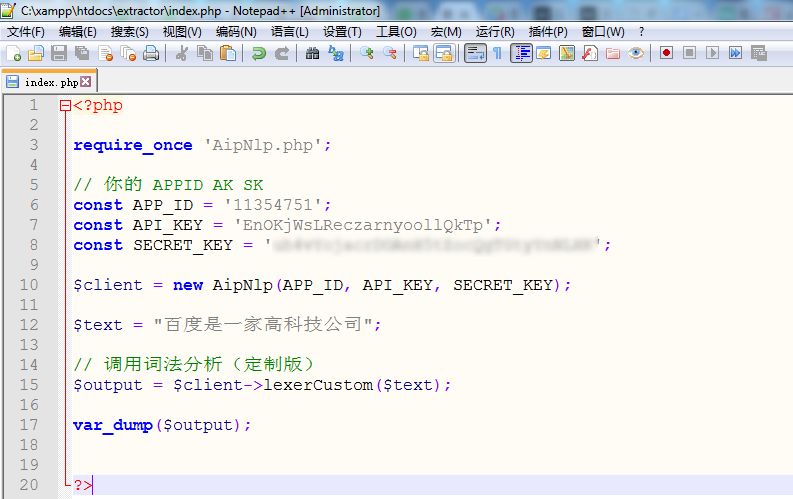
然后在浏览器中访问这个页面,查看到如下结果:
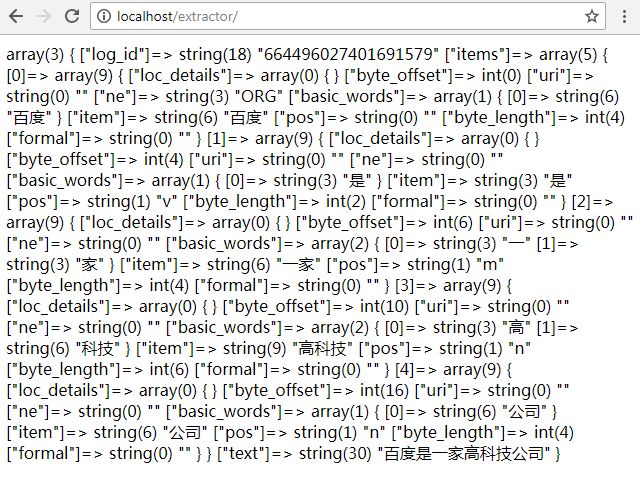
这白花花的一篇都是什么呢?“羊杂毛”?
不明白的地方还是得看使用说明。在说明中看到的例子里,可知:
1) 这个工具可以分析词性,如下图:
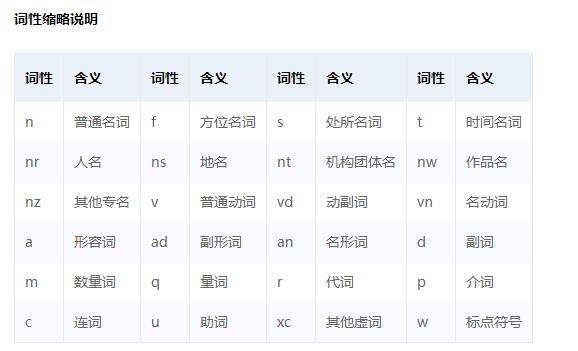
“名词”分为普通名词、方位名词、处所名词等等。
2)还可以分析专名,如下图
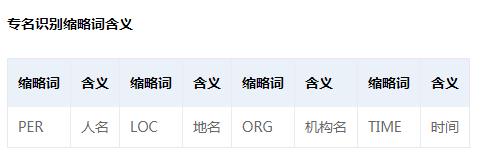
3)在命名实体类型(ne)和词性(pos)分析结果中可以看到以上的标记
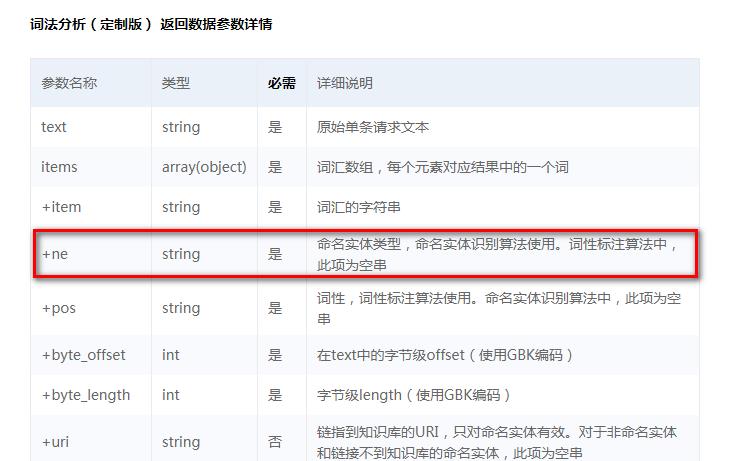
4)工具分析后,可以在返回的数据中看到对应的分析结果,如下图:
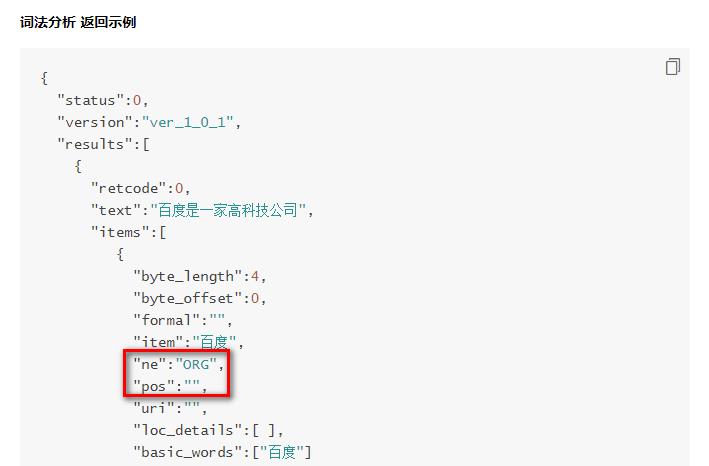
这样一来,我们就知道怎么提取结果了。
四、在浏览器中自定义显示分析结果
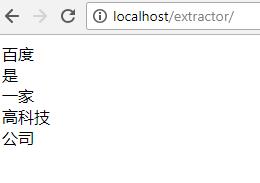
从示例的结果中可以看出,原文“百度是一家高科技公司”的分析结果为:
百度/是/一家/高科技/公司
我们现在写一段简单的代码将其逐行打印出来,代码如下:
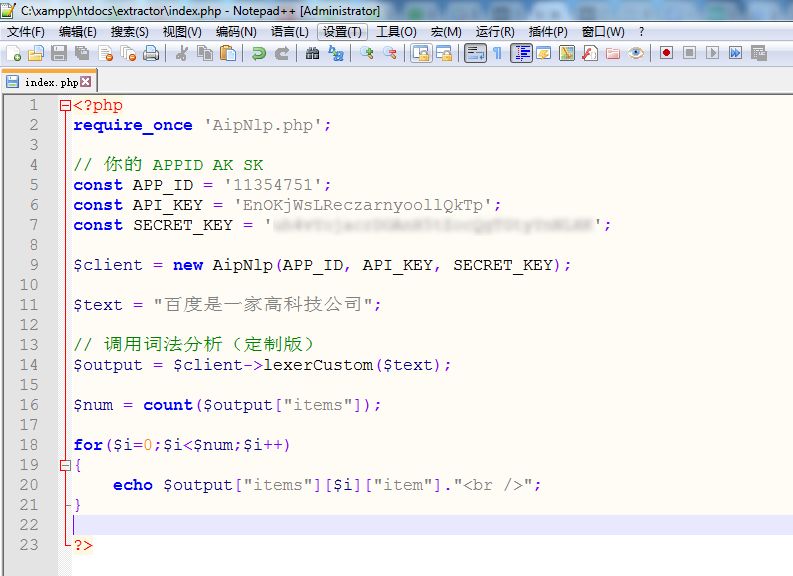
运行结果如下:
接下来,我再把各个部分的“命名实体类型”和“词性”以表格的形式呈现出来,部分代码如下:
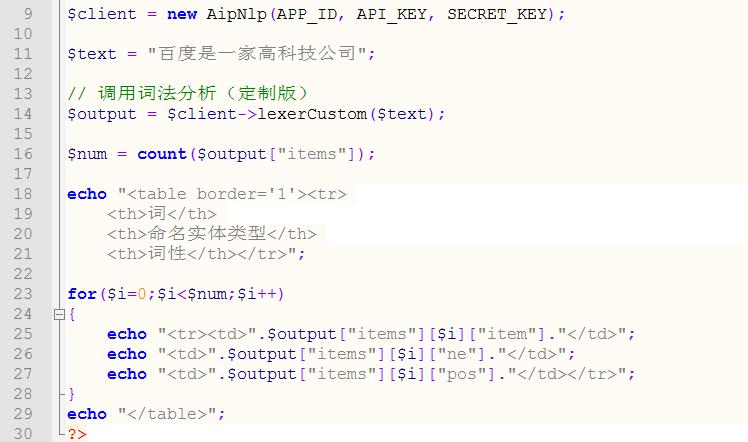
运行效果如下:

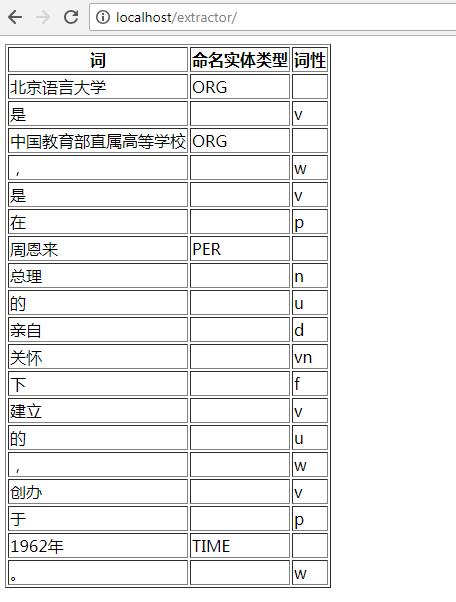
我们可以再试一下下面这句长的:“北京语言大学是中国教育部直属高等学校,是在周恩来总理的亲自关怀下建立的,创办于1962年。”
运行效果如下:
五、对分析结果进行统计
接下来,我们继续来对这些结果进行分析,比如我希望呈现一个所有名词的汇总的,比如:上文中一共有n个名词,其中包括:m个命名实体、a个普通名词、b个人名、c个地名......
部分代码如下:
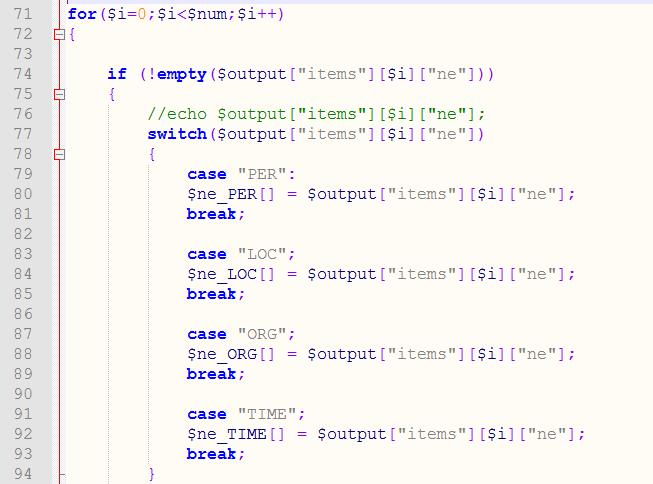
定义空数组用来存储命名实体和各名词词性的分析结果

根据分析结果来进行“分流”:
最后是统计结果:

然后我们来看这句话的运行结果:
分析原文:“百度是一家高科技公司。北京语言大学是中国教育部直属高等学校,是在周恩来总理的亲自关怀下建立的,创办于1962年。”
分析结果:

该文本中命名实体共有 5 个:其中人名有:1 个;地名有:0 个;机构名有:3 个;时间名词有:1 个。
该文本中名词共有 4 个:其中普通名词有:3 个;方位名词有:1 个;处所名词有:0 个;时间名词有:0 个;人名有:0 个;地名有:0 个;机构团体名有:0 个;作品名有:0 个;其他专名有:0 个。
通过这样的方式我们就可以对待分析的文本进行统计了。那么如果百度分析错了怎么办?有些新词它没有识别出来怎么办?
百度其实还支持自定义的词表:
结语
那么把名词统计完就算完事儿了吗?
事实上我上面所展示的只是百度自然语言处理API的一部分很小很小的功能,具体能够做出什么东西来要看你的想象,比如:你可以做一个名词高亮标记器,把所有的名词都高亮显示出来;你可以把上面的名词高亮标记器和你已有的术语表结合到一起,让你自己的术语译文显示在名词后面,这不就可以辅助翻译了吗?
难道百度自然语言处理只能标记“名词”?请看下表:
词法分析只是众多百度自然语言处理API中的一个,在上面的列表中你还可以看到很多很多很多其他的功能。
可以说,只要你会一些基本的编程知识,你就能开始运用这些免费的自然语言处理技术做出对自己的学习、工作和研究有帮助的小工具。
不知道大家有没有听说过“AI 民主化”(Democratizing AI)这个概念,在未来的几年里越来越多的文科专业学生也将掌握编程知识,如果能够充分利用市面上的开源或免费的(哪怕是付费的)人工智能技术,那么大家将会看到一大堆有创意有价值的办公工具和研究工具,为我们的生活赋能。
不光百度在做这样的有价值的事,腾讯、阿里、谷歌等一大批互联网公司都在不断开放自己的人工智能服务,让更多人可以通过极为简单的方法应用人工智能技术。
我相信这是未来技术发展的趋势。
以上是关于永久免费的百度自然语言处理技术,了解一下?的主要内容,如果未能解决你的问题,请参考以下文章